


Your team probably isn't struggling because they write bad code. They're struggling because code meets reality too late.
A founder sees the symptom as missed release dates, nervous launches, and too many “small” bugs reaching customers. A product manager feels it as uncertainty. A CTO feels it as rising delivery risk. Engineers feel it as context switching, painful merges, and late-night firefighting that should never have been necessary.
That's where the question what is continuous integration stops being technical trivia and becomes a business question. If your team can't integrate work safely and constantly, you don't have a delivery engine. You have a queue of risk.
At Rite NRG, we look at CI through the lens of the #riteway. Extreme Ownership. Fast feedback. Proactive control. The point isn't to install another tool and feel modern. The point is to create a system where every change gets validated early, your main branch stays healthy, and delivery becomes predictable enough to support growth.
Stop Dreading Deployments and Start Delivering Value
Thursday night. The release window is open. One engineer is fixing a merge conflict, another is rerunning tests manually, your product lead is waiting for a go or no-go answer, and someone says the words nobody wants to hear: “It worked on my branch.”
That situation isn't bad luck. It's a design flaw in how the team integrates work.
When developers leave integration until late, they create big-batch risk. Conflicts pile up. Assumptions drift. Bugs hide in the gaps between branches. Then your most senior people get pulled into rescue mode. They stop building the next valuable thing because they're untangling work that should have been validated days earlier.
Bad integration burns scarce leadership time
This matters even more in the UK market. Demand for software skills is strong, and employers still face hiring and retention pressure. That makes experienced developer time expensive and limited. CI matters because it reduces the coordination burden on senior engineers by catching defects earlier and avoiding long integration bottlenecks, turning it into a staffing and productivity strategy, not just a build habit, as noted in Harness's overview of continuous integration.
Practical rule: If your best engineers spend release day acting as human glue between branches, your delivery system is wasting one of your scarcest assets.
Founders often underestimate this cost because it doesn't appear neatly in a line item. It shows up as delayed feedback, slower roadmap execution, and good people losing energy. The business impact is real even when the failure looks “technical”.
Extreme Ownership starts with integration discipline
Teams with an ownership mindset don't accept release chaos as normal. They treat every merge, every failed build, and every flaky test as a signal that the operating model needs tightening.
That's the first mindset shift. Continuous integration is not a developer convenience. It is an engineering control. It protects flow. It preserves confidence. It gives your team a reliable rhythm for shipping product changes without repeatedly paying the same integration tax.
A SaaS company doesn't win because it occasionally delivers a big release. It wins because it can keep delivering, safely, week after week, while competitors are still stabilising last month's changes.
If your deployments feel heavy, tense, or unpredictable, don't start by blaming output. Fix integration.
What Continuous Integration Really Is
The cleanest answer to what is continuous integration is simple. Developers integrate small changes into a shared codebase frequently, and every integration is checked automatically.
Martin Fowler's canonical definition still holds up. He describes continuous integration as a practice where team members integrate their work frequently, at least daily, and each integration is verified by an automated build and test process so teams detect errors as quickly as possible, in his foundational article on continuous integration.
Think of it as an assembly line
A useful way to understand CI is to stop thinking about “developer branches” and think about an assembly line.
If a car factory let every team build large sections in isolation for weeks and only tested whether the parts fit together at the end, production would be chaos. Software teams make the same mistake when they delay integration. CI fixes that by forcing fit checks constantly.
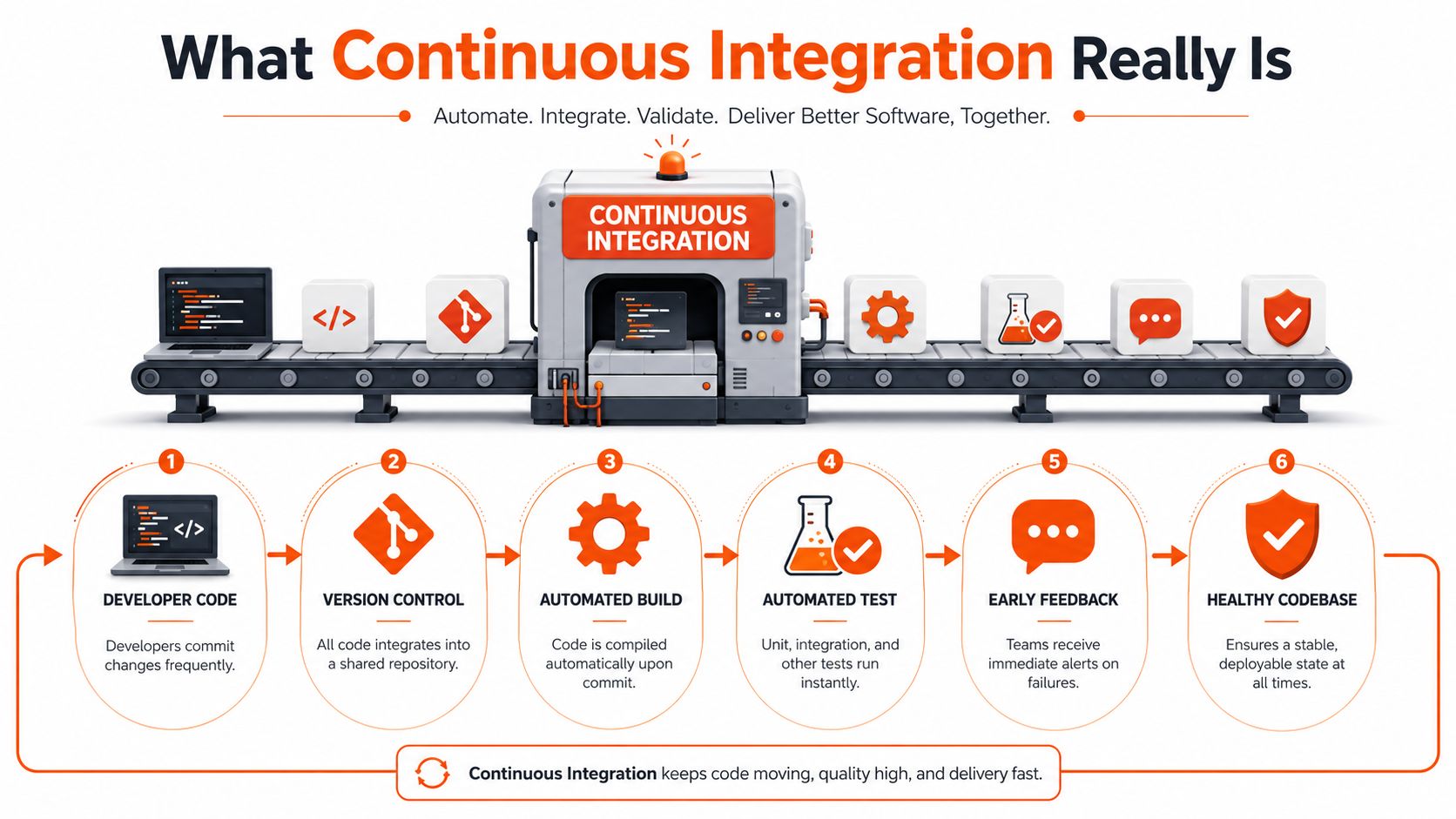
The loop is straightforward:
- Write a small change
- Commit it to version control
- Trigger an automated build
- Run automated tests
- Give immediate feedback
- Keep the shared codebase healthy
That loop sounds basic. It isn't. When a team does it properly, it changes behaviour. Engineers work in smaller slices. Problems surface earlier. Reviews become clearer. Releases become less dramatic.
CI is a practice, not a logo
Jenkins, GitHub Actions, CircleCI, GitLab CI. These are implementation options, not the definition. Buying a tool doesn't mean you're doing CI well.
Real CI means the team commits often, validates every change automatically, and treats a broken build as urgent. It's part of the same delivery thinking behind agile development benefits, where shorter feedback loops reduce risk and keep product work tied to outcomes rather than assumptions.
A healthy main branch is not a nice-to-have. It's the baseline for reliable delivery.
If your pipeline runs once a day, half the tests are ignored, and everyone shrugs when main is red, you don't have continuous integration. You have automation theatre.
CI vs Continuous Delivery vs Continuous Deployment
These terms get blurred together all the time, and that creates bad decisions. Leaders approve the wrong investment. Teams argue about tooling when they should be deciding on release control.
Here's the clean split. Continuous integration validates code changes. Continuous delivery makes validated software ready to release. Continuous deployment releases every validated change to production automatically.
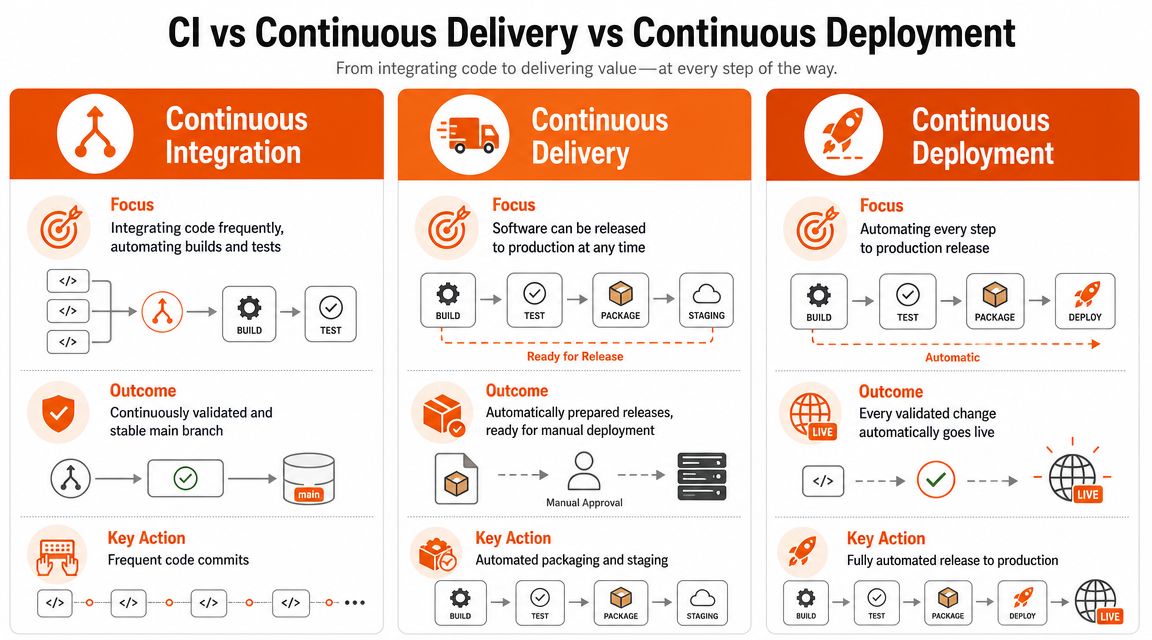
The differences that matter
| Practice | Core concern | What gets automated | Human decision point |
|---|---|---|---|
| Continuous Integration | Code quality and integration safety | Build and test on each change | Before release |
| Continuous Delivery | Release readiness | Build, test, package, prepare for deployment | At production release |
| Continuous Deployment | End-to-end release automation | Build, test, package, deploy to production | Removed after quality gates pass |
A lot of SaaS teams need CI immediately. They do not all need continuous deployment immediately.
Pick the maturity level your business can support
If you're in a regulated environment, have complex release coordination, or you're still building test confidence, continuous delivery is often the smart target. It keeps the software release-ready while preserving a manual decision before production.
If your product is mature, your automated checks are strong, and your rollback capability is solid, continuous deployment can make sense.
Use this decision lens:
- Choose CI first if your team struggles with merge pain, broken main branches, or low trust in code changes.
- Choose continuous delivery next if you want release predictability without removing oversight.
- Choose continuous deployment last if your quality gates, observability, and operational maturity are already strong.
Don't automate the last mile to production before you've stabilised the first mile of integration.
That sequencing matters. Founders sometimes push for “full CI/CD” because it sounds advanced. In practice, the biggest gains usually come from getting CI disciplined and boring. Boring is good. Boring means predictable. Predictable means you can plan product, sales, and customer commitments with less guesswork.
From Code Commits to Business Momentum
Your team is ready to ship a revenue-driving feature on Friday. Instead of release confidence, you get merge conflicts, last-minute fixes, and a Slack channel full of guesswork. That is not an engineering inconvenience. It is a business bottleneck.
A weak CI practice turns product delivery into a planning risk. A disciplined CI practice turns code commits into dependable business movement. The difference shows up in launch timing, customer trust, and how fast your team can respond when the market changes.
DORA performance is the business lens
The 2024 State of CI/CD report from the Continuous Delivery Foundation found that 83% of developers are involved in DevOps activities, and teams using CI/CD tools reported better deployment performance across DORA metrics. That matters because DORA metrics are not engineering vanity numbers. They measure how reliably your company can turn decisions into shipped product.
For a SaaS founder, the translation is straightforward:
- Higher deployment frequency means faster feature delivery, quicker fixes, and less release batching that slows the roadmap.
- Shorter lead time for changes means customer feedback reaches production sooner.
- Lower integration friction means less rework, fewer interruptions, and more engineering time spent on product progress.
- Better quality controls mean fewer avoidable incidents, especially when teams build security checks into the software delivery process instead of treating them as a late-stage cleanup task.
CI does not matter because the pipeline passes. CI matters because the business can move without drama.
What founders should demand from CI
Ask questions that expose whether your delivery system supports growth or blocks it:
- Can we ship a change without turning release day into an incident response exercise?
- How fast do we detect and contain a bad change?
- Can product and sales trust delivery dates tied to the main branch?
- Are we tracking lead time and change failure rate, or relying on optimism?
Those answers affect more than engineering. They affect launch coordination, customer commitments, and the credibility of your roadmap.
At Rite NRG, we treat CI as part of delivery strategy, not build-server hygiene. The goal is simple: create a delivery system that supports predictable MVP execution, fast iteration, and quality you can trust under pressure. That outcome-focused approach is why CI belongs in founder-level conversations.
The same logic applies to mobile teams implementing Capacitor CI/CD pipelines. If build, test, signing, and release steps are inconsistent, every shipment costs more attention than it should.
Momentum comes from trust
CI's ultimate output is operational trust.
Product trusts estimates. Engineering trusts the main branch. Leadership trusts release plans. That trust removes drag from the system and gives the company more shots on goal each month.
One clean commit changes very little on its own. A steady flow of validated commits gives a SaaS company the speed and predictability to grow.
Anatomy of a Modern CI Pipeline
A modern CI pipeline should feel automatic, visible, and strict. Not heavy. Not mysterious. Not dependent on one person who “knows the build server”.
A single code change should move through a clear sequence of checks the same way every time. That consistency is what gives teams confidence.
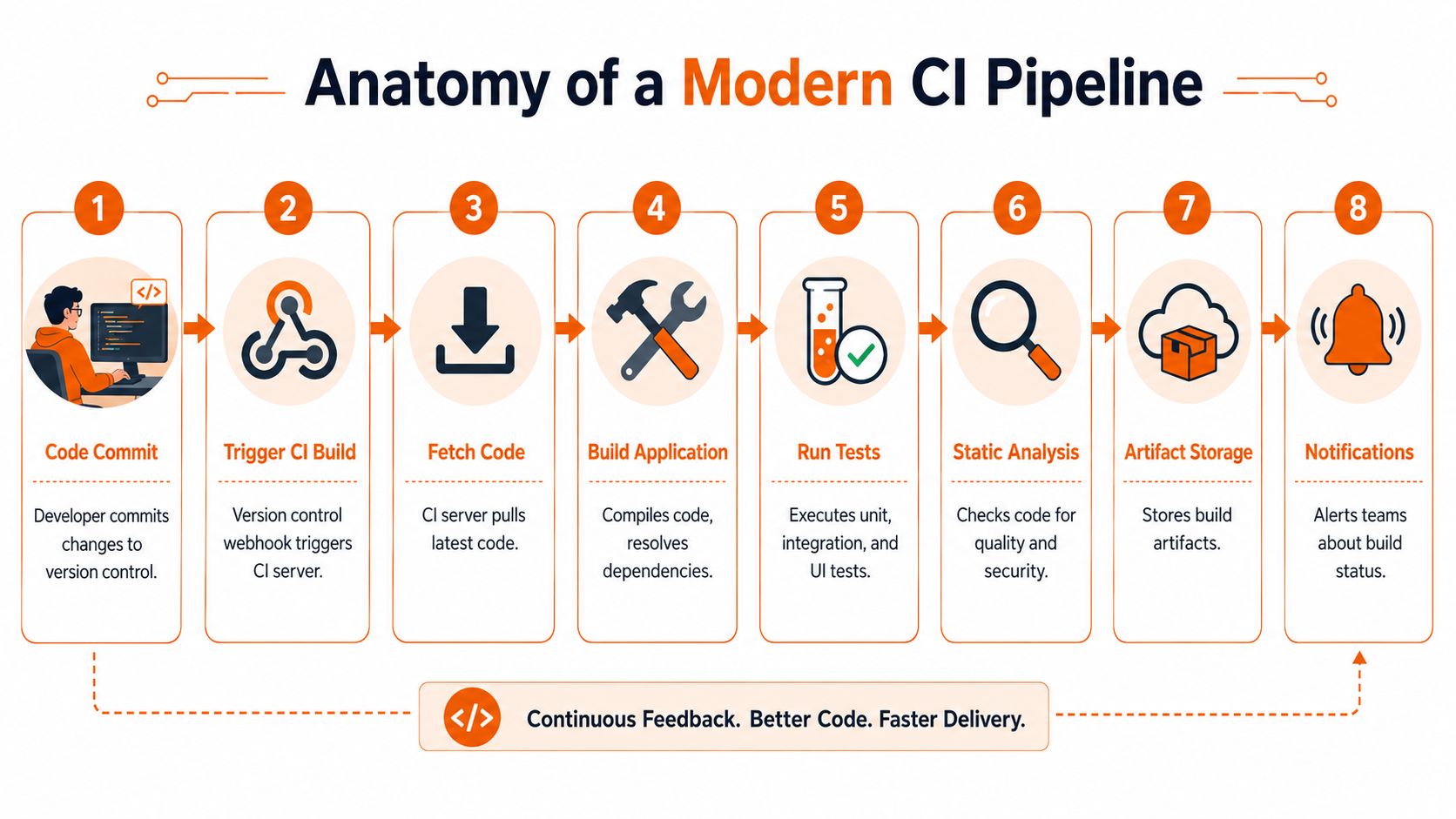
What a healthy pipeline includes
A typical flow in GitHub Actions, Jenkins, GitLab CI, or CircleCI looks like this:
- A developer pushes code to a branch or opens a pull request.
- The CI system triggers automatically through a webhook or repository event.
- The runner fetches the code and restores dependencies.
- The application builds so the team knows the change is structurally valid.
- Automated tests run, including unit and integration checks.
- Static analysis and security checks run to catch quality and dependency issues early.
- A build artefact is generated and stored so later stages use the exact validated output.
- The team gets notified in Slack, Teams, email, or the repository UI.
That's the visible skeleton. Value lies in the quality gates. Every gate answers a specific business question: does it build, does it work, is it safe enough, and can we trust the result?
Security checks should be part of the same flow, not bolted on at the end. That's why teams building modern delivery systems should understand security in the software development life cycle as part of pipeline design, not a separate compliance afterthought.
Good CI keeps feedback close to the change
This walkthrough helps make the mechanics concrete:
Different stacks need different details. A web app might run frontend tests, API integration checks, and package a container image. A mobile or hybrid app needs more platform-aware automation. If your team works with Capacitor, this guide to implementing Capacitor CI/CD pipelines is a useful example of how build and release automation gets adapted to a specific delivery context.
The best pipeline is the one your team can trust on a busy Tuesday afternoon, not just the one that looks impressive in a conference talk.
If feedback arrives fast, engineers fix issues while the code is still fresh in their heads. If feedback arrives hours later, the pipeline becomes background noise and quality drops. That's why pipeline speed matters. Fast feedback protects flow.
How Rite NRG Uses CI to Ship MVPs Faster
A SaaS founder with a narrow market window doesn't need theory. They need a launch path that won't collapse under first contact with real users.
One client came to us with exactly that problem. They needed an MVP in market quickly, but their existing setup depended on manual checks, long-lived branches, and release decisions based on gut feel. Every feature felt bigger than it was because nobody trusted integration.
We build the delivery system with the product
Our response wasn't to say, “Let's add a build server.” That's too shallow.
Under the #riteway, Extreme Ownership means we treat the delivery pipeline as part of the product system from day one. The team set up automated build validation, test gates, branch policies, and a clear path from pull request to release-ready artefact. We also made failures visible immediately, so nobody had to discover problems in a release meeting.
The key shift was behavioural. Engineers stopped treating integration as an event and started treating it as a constant. Product decisions improved too, because smaller changes could be released with less fear.
The MVP moved faster because risk moved earlier
The founder's real problem wasn't code output. It was uncertainty.
Once CI was in place, the team could iterate in smaller slices, validate changes continuously, and make release calls with evidence instead of guesswork. Security checks and performance-minded validation were included inside the pipeline rather than saved for the end, because late surprises kill MVP momentum.
That changed the shape of delivery:
- Features were easier to scope because the team worked in thinner increments.
- Bugs were cheaper to fix because they surfaced close to the change that caused them.
- Release conversations got shorter because quality status was already visible.
- Stakeholders got better predictability because main stayed in a releasable state.
Advisory matters. A vendor installs tools. A delivery partner changes the system that produces outcomes.
Ownership shows up in the boring details
Strong CI is built from unglamorous decisions made consistently. Naming conventions. Branch rules. Test reliability. Artefact versioning. Build failure handling. Those details decide whether a pipeline becomes a growth asset or a noisy dashboard everyone ignores.
For MVP work, that discipline matters even more. Early-stage teams don't have spare time for integration debt. They need a release process that protects speed while preserving confidence. That's exactly why CI belongs at the centre of product delivery, not at the edge of engineering.
CI Best Practices That Drive Real Value
Many teams can set up a pipeline. Far fewer build one that improves delivery.
The difference comes from operating discipline. UK guidance is clear on the direction of travel. Automated pipelines improve predictability by validating every change early, and organisations should define quality gates, enforce trunk-based development, and measure metrics such as change failure rate and lead time to see whether integration debt is falling, as outlined in CloudBees' guidance on continuous integration.

The practices worth enforcing
- Commit in small slices. Large branches create delayed risk. Smaller changes are easier to review, test, and reverse.
- Keep one trusted source of truth. Your shared repository must reflect the actual state of the product, not a hopeful approximation.
- Automate quality gates. Tests, static analysis, and dependency checks should run by default, not by memory.
- Protect the main branch. If the build fails, treat it as an interruption to delivery, because that's what it is.
- Keep pipelines fast. Slow feedback trains engineers to ignore the system.
- Version build artefacts. The thing you tested should be the thing you promote.
- Use short-lived branches or trunk-based workflows. Integration risk rises the longer changes live away from main.
- Measure operational outcomes. Change failure rate and lead time tell you whether CI is improving delivery or just generating activity.
Security and governance belong inside CI
A modern pipeline also needs to account for software supply chain risk. Dependency scanning, policy checks, and repeatable builds should happen inside the flow of delivery. If security is left to periodic review, teams lose both speed and confidence.
That same principle applies to multilingual products, content-heavy systems, and operational workflows connected to development platforms. For teams working in Microsoft's ecosystem, this practical write-up on TranslateBot and Azure DevOps is a useful example of how repository workflows connect with broader delivery operations.
Key takeaway: If a control matters enough to do manually before release, it probably matters enough to automate earlier in CI.
Quality assurance also needs to be integrated, not separated into a late-stage handoff. Teams that want stronger delivery discipline should connect CI design with broader quality assurance processes so testing strategy, release confidence, and feedback loops reinforce each other.
What to fix first
If your current setup is messy, don't try to perfect everything at once. Tighten the fundamentals in this order:
| Priority | Fix | Why it matters |
|---|---|---|
| First | Broken build ownership | A red pipeline kills trust immediately |
| Second | Faster feedback | Short cycles change behaviour faster than policies do |
| Third | Stronger quality gates | Tests and analysis stop preventable defects earlier |
| Fourth | Better flow metrics | You need evidence that delivery is improving |
Good CI isn't flashy. It's dependable. It reduces avoidable work, supports auditability, and gives leaders a more trustworthy delivery cadence. That's real value.
If your team is shipping with too much friction, too much uncertainty, or too many late surprises, talk to Rite NRG. We advise SaaS teams on delivery systems that support faster MVPs, stronger quality control, and more predictable execution through senior engineering, product-first thinking, and Extreme Ownership.

