


If your QA process slows delivery, you don't have a quality function. You have a delay mechanism.
That's the mistake too many CTOs still make. They treat quality assurance as the last checkpoint before release, hand work to a separate team, wait for a bug list, then wonder why delivery feels heavy, expensive, and unpredictable. That model doesn't protect the business. It hides risk until the worst possible moment.
A modern QA function should do the opposite. It should increase release confidence, tighten feedback loops, reduce rework, and make delivery more predictable. It should help product, engineering, and operations move faster with fewer surprises. That's what good quality assurance processes deliver.
I'm opinionated on this because the stakes are commercial, not academic. Quality isn't about ticking process boxes. It's about protecting revenue, reputation, and team capacity while keeping momentum high. The best teams don't “add QA” at the end. They build quality into planning, engineering, data handling, release, and monitoring from day one.
That requires a different mindset. We call it Extreme Ownership. Quality is not one team's job. It's everyone's operating standard. Developers own testability. Product owners own clarity. QA specialists own strategy, coverage, and risk visibility. Delivery leaders own the system that keeps all of it moving.
Stop Treating Quality as a Bottleneck
The most popular advice about QA is still wrong. It assumes quality assurance processes exist to catch defects before release.
That's too small a goal.
If your process is built mainly around late-stage test execution, you'll keep paying the same tax. Requirements drift slips through. Developers code without enough fast feedback. Testers become overloaded. Releases bunch up. Defects surface late, when fixes are slower, coordination is harder, and confidence drops.
What bottleneck QA looks like
You've seen the symptoms:
- Long test phases: Work sits in a queue waiting for verification.
- Late defect discovery: Problems appear after multiple dependencies have already moved on.
- Fragile releases: Teams debate whether to ship because nobody trusts the signal.
- Recurring rework: The same classes of issues keep returning because the process never changed.
That isn't a testing problem. It's a delivery design problem.
Practical rule: If QA mostly happens after coding, your process is already too late.
Strong quality assurance processes act as an accelerator because they reduce uncertainty early. They push risk detection closer to the moment work is created. They give teams a reliable answer to the only question the business really cares about: can we release safely and keep moving?
Shift the conversation from defects to outcomes
A CTO shouldn't ask, “How many bugs did QA find?” Ask better questions:
- Can this team release on demand with confidence?
- Where does risk become visible in the pipeline?
- Which quality checks protect customer trust and compliance?
- How much rework are we creating because feedback arrives too late?
That's the commercial lens.
The #riteway view is simple. Build a QA function with high energy, clear ownership, and proactive intervention. Don't wait for defects to pile up. Design a system that prevents avoidable issues, flags meaningful risk early, and keeps teams shipping. When you do that, QA stops being a cost centre and starts behaving like a growth lever.
What Are Quality Assurance Processes Really For
Quality assurance processes exist to build organisational confidence. Not vague confidence. Operational confidence.
They tell the business whether outputs are reliable, whether change is controlled, and whether teams can make decisions without guessing. That applies to software, data, compliance, and service delivery. Good QA is a confidence engine.
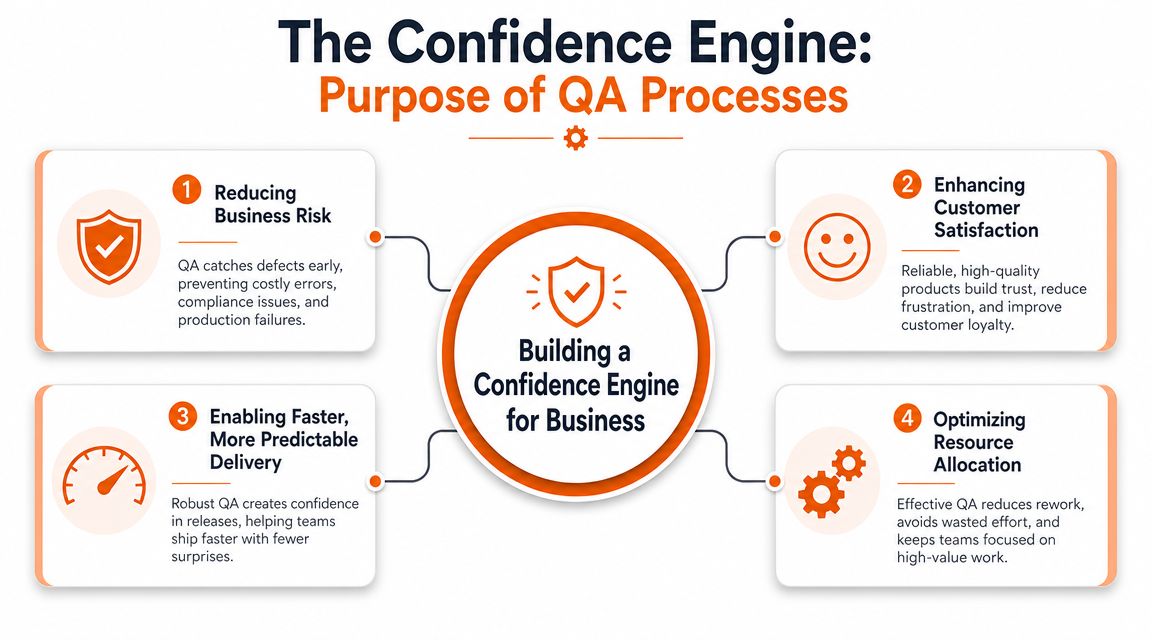
Confidence is the product
Organizations often describe QA as testing. That's incomplete. Testing is one mechanism. The primary output is confidence in decisions such as:
- Release confidence: Can we deploy today without crossing our risk tolerance?
- Product confidence: Will this change do what customers expect?
- Operational confidence: If something breaks, will we detect it fast and respond cleanly?
- Leadership confidence: Can stakeholders trust the delivery forecast?
When those answers are weak, the business slows down. Teams add meetings, approval layers, manual checks, and release hesitation. None of that is scale. It's compensation for poor signal.
Structured QA beats ad hoc inspection
The UK gives a useful example of what mature assurance looks like outside software alone. The Office for Statistics Regulation's Quality Assurance of Administrative Data framework requires producers to assess data using six quality dimensions: relevance, accuracy and reliability, timeliness and punctuality, accessibility and clarity, comparability, and coherence. It also calls for checks on completeness, coverage, missing values, unit non-response, item non-response, and measurement error, as set out in the OSR QAAD framework for statistical producers.
That matters because it shows quality assurance processes are not random inspections. They are structured systems that make outputs meaningful enough for decisions.
Teams don't need more ceremony. They need clearer evidence that what they're shipping can be trusted.
That same principle applies in SaaS. If you want predictable delivery, your QA process needs defined standards, clear decision points, and visible evidence. If you're also refining broader operating models, these effective business process strategies are useful because they reinforce the same idea: repeatable outcomes come from deliberate process design, not heroic effort.
What a QA process should produce
A serious QA function should produce four things:
- Risk visibility so leaders know what they're accepting.
- Decision support so release calls aren't driven by gut feel.
- Feedback loops so teams learn quickly and improve the system.
- Trust so customers, auditors, and internal stakeholders believe the output.
If your current process mostly produces bug reports, it's underpowered.
Integrating Quality into Your Delivery Pipeline
Quality has to live inside delivery, not outside it.
The right model is simple. Check quality where work is created, where systems connect, and where customer journeys matter most. Don't concentrate all assurance at the end and call it discipline. That just creates queues.
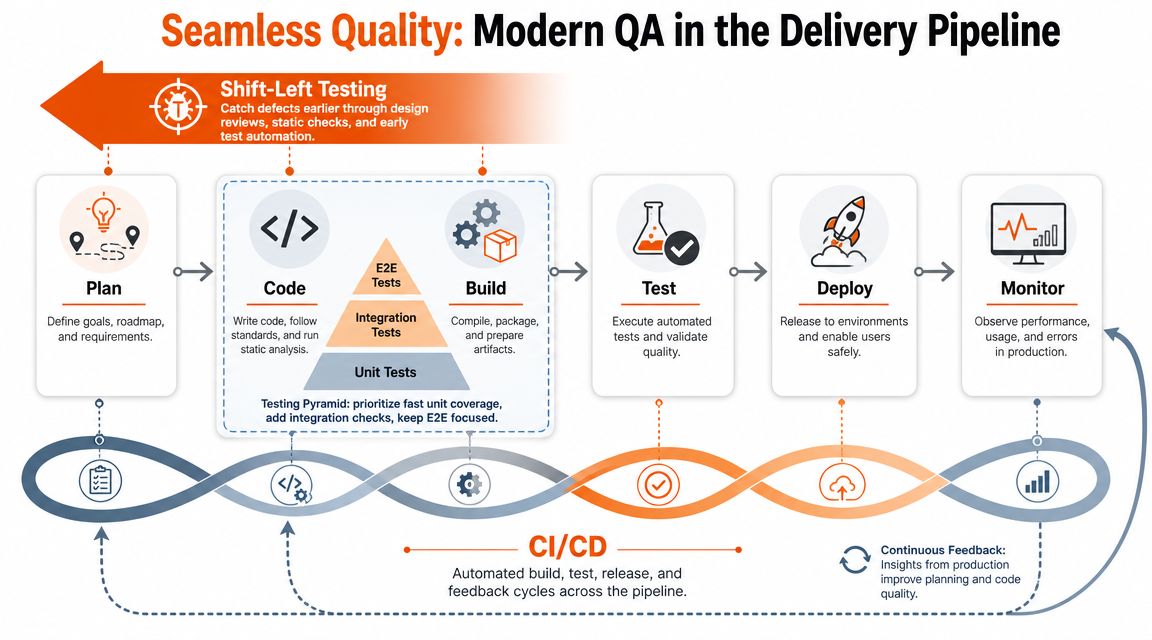
Build a layered control system
The most practical way to structure modern quality assurance processes is as a layered control system. The UK government's service manual requires teams to test iteratively, automate tests where practical, and use continuous integration so defects are detected early rather than after release. In practice, mature QA in frequent-release environments relies on unit and component tests to gate merges, API or contract tests to verify service boundaries, and a smaller set of end-to-end tests to validate critical user journeys, as summarised in this discussion of automation in CI/CD and layered QA controls.
That structure matters because heavy dependence on UI tests gives teams false confidence. Those tests are slower, more brittle, and harder to maintain.
Here's the operating principle:
- At the code level: Developers should get fast feedback in minutes, not hours.
- At the service level: Teams should verify integrations before defects leak downstream.
- At the journey level: Only the most business-critical end-to-end flows should be covered.
Shift left, but don't stop there
“Shift left” gets repeated so often that teams stop thinking about what it means. It doesn't mean doing all testing early. It means moving defect prevention and validation closer to design and coding while keeping feedback active all the way through release and production.
A healthy delivery pipeline behaves more like an assembly line with checks at each station. Planning clarifies acceptance criteria. Coding triggers local and CI checks. Build stages validate packaging and contracts. Deployment uses guarded rollouts. Monitoring confirms the change behaves as expected in the production environment.
This walkthrough is worth watching because it gives a practical view of how these ideas fit into delivery workflows.
Put release safety into the pipeline
If release confidence depends on tribal knowledge, you're exposed.
Use your pipeline to enforce the basics:
- Automated merge gates: Don't rely on reviewers to catch everything manually.
- Contract verification: Protect service boundaries before dependent teams feel the pain.
- Critical path end-to-end coverage: Keep this focused and business-led.
- Post-deploy checks: Confirm the release worked where it counts.
For teams tightening their operational controls after release, these incident response procedures are a useful companion to pipeline quality. Assurance doesn't end at deployment. It extends into detection, recovery, and learning.
Building a Team That Owns Quality
A separate QA department that “checks the work” is one of the most expensive habits in software delivery.
It creates handoffs, weakens accountability, and teaches developers that quality belongs to someone else. Then everyone acts surprised when defects bounce between teams and releases stall.
High-performing teams distribute ownership. That doesn't mean eliminating QA specialists. It means using them properly. Their job is to raise the quality bar across the system, not sit at the end of a queue validating work that should already be testable.
The mindset shift that matters
Under Extreme Ownership, every role owns quality through the lens of outcomes.
A developer's work isn't done when code is committed. It's done when the change is testable, observable, and reliable in production. A product manager doesn't just write tickets. They reduce ambiguity so the team can build the right thing. A QA lead doesn't just execute scripts. They design risk coverage, improve signal quality, and strengthen release confidence.
| Quality Ownership Models: Traditional vs. #riteway | Traditional Mindset (Gatekeeper) | #riteway Mindset (Extreme Ownership) |
|---|---|---|
| Developer | Writes code, then passes it to QA | Builds testable code, adds checks, owns reliability after merge |
| QA specialist | Runs test cases and blocks release if needed | Shapes strategy, risk coverage, automation, and quality visibility |
| Product manager | Hands over requirements | Clarifies outcomes, edge cases, and acceptance criteria early |
| Engineering manager | Tracks delivery status | Designs a system where quality and throughput improve together |
| Delivery lead | Escalates defects late | Surfaces risk early and removes blockers before they become incidents |
Design roles around outcomes
Many CTOs underperform by defining responsibilities by activities instead of business outcomes.
Use these outcome-led expectations instead:
- Developers own prevention: better unit coverage, cleaner contracts, fewer avoidable regressions.
- QA owns confidence strategy: smarter automation, stronger risk targeting, better release evidence.
- Product owns clarity: acceptance criteria that reflect user value and edge conditions.
- Leadership owns the environment: enough time, tooling, and standards for quality to happen by design.
The fastest teams aren't the ones with the fewest checks. They're the ones where nobody waits to be told to care.
If your current team structure still rewards ticket passing, fix the operating model before you buy more tools. Team design drives delivery behaviour. For leaders working on that broader shift, this guide to building high-performing teams is worth reading because quality ownership is ultimately a team sport.
Using Metrics That Matter to the Business
Most QA dashboards are cluttered with outputs that sound useful and prove very little.
Counting executed test cases, logged defects, or pass rates can create activity theatre. You get reports. You don't get business clarity. A CTO needs metrics that show whether quality assurance processes are improving speed, stability, and control.
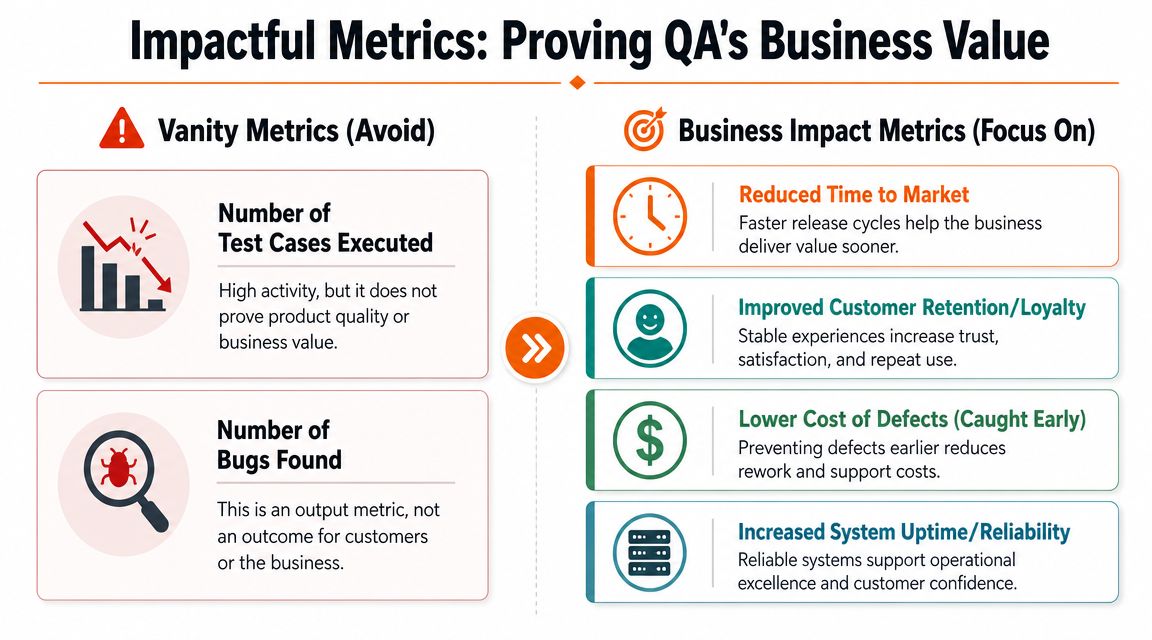
Drop vanity metrics
A high bug count can mean the team is thorough. It can also mean the product is unstable. A low bug count can mean quality is high. It can also mean coverage is weak. On their own, these numbers don't help leaders make confident decisions.
The same goes for raw test case totals. More tests do not automatically mean more assurance. If the suite is slow, brittle, or disconnected from business risk, it becomes overhead.
Use metrics that answer commercial questions instead.
Track delivery and stability together
The strongest QA functions improve both flow and resilience. That's why I recommend focusing on a small set of operational metrics such as:
- Cycle time: How long it takes for work to move from commitment to production.
- Deployment frequency: How often the team can ship safely.
- Change failure rate: How often releases cause incidents, rollbacks, or hotfixes.
- Mean time to recovery: How quickly the team restores service when something goes wrong.
These metrics matter because they connect engineering quality with customer experience and delivery predictability. Faster cycle time means faster value realisation. Better recovery protects reputation. Lower failure rates reduce disruption for support, product, and commercial teams.
If a metric doesn't help you decide whether delivery is becoming safer and faster, it belongs in the background.
Treat traceability as a business asset
For regulated products, metrics alone aren't enough. You also need evidence.
UK GDPR and the Data Protection Act 2018 require appropriate technical and organisational measures, and in practical QA terms that means documented controls, traceability, and audit-ready records. A strong process links requirements to test cases, test results, and defects so teams can prove that security and privacy checks were executed, as described in this overview of governance and traceability in QA for regulated UK products.
That's not admin for admin's sake. It improves release confidence because leaders can see what was tested, what failed, what was fixed, and what risk remains.
A sensible scorecard combines both sides:
| Business question | Useful signal |
|---|---|
| Are we shipping quickly enough? | Cycle time and deployment frequency |
| Are releases stable? | Change failure rate and recovery performance |
| Can we prove control? | Requirement-to-test traceability and audit-ready evidence |
| Are we reducing waste? | Fewer late surprises and less rework in the release path |
That's how you justify QA investment. Not by saying the team was busy, but by showing delivery is becoming more dependable.
Supercharge Your QA with Tooling and AI
Tooling doesn't fix a weak QA model. It amplifies whatever model you already have.
If your team is reactive, disconnected, and overloaded, adding more tools will just produce faster chaos. If your team already owns quality, the right toolchain will multiply its effectiveness. That's the difference mature CTOs understand.
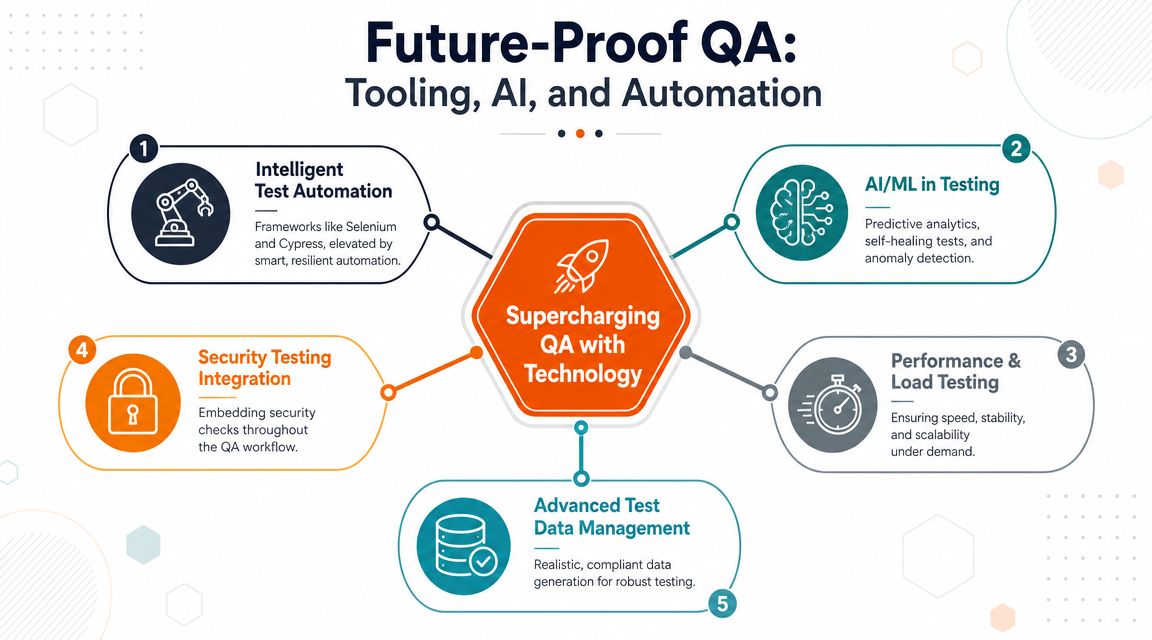
Build a toolchain, not a pile of products
Organizations often find themselves with too many disconnected QA tools and not enough operational coherence. They use one platform for test management, another for UI automation, another for API checks, separate monitoring tools, separate incident logs, and no clean feedback loop between them.
Fix that.
A practical stack often includes tools such as Cypress or Playwright for browser testing, Postman or contract-testing frameworks for API verification, CI platforms such as GitHub Actions, GitLab CI, or Jenkins, observability tools like Datadog or Grafana, and issue tracking in Jira. The exact products matter less than the system they create together.
Choose tooling that supports three things:
- Fast feedback for engineers
- Clear release signals for leaders
- Low-maintenance automation for the team
Use senior engineers to make automation sustainable
Many companies find themselves burning money when they ask junior teams to build automation first, then wonder why the suite turns fragile and expensive.
Strong test automation needs architectural judgment. Someone has to decide what to automate, what not to automate, where to use mocks, how to handle contracts, how to manage test data, and how to keep suites maintainable as the platform evolves. Senior nearshore engineers are often a smart answer here because they can integrate quickly, work closely with in-house teams, and build automation with production realities in mind rather than treating it as an isolated QA exercise.
The value is not lower cost alone. It's better decisions, faster stabilisation, and less wasted effort.
Extend QA into AI-augmented delivery
AI is already changing how teams build software. QA has to change with it.
Guidance such as the UK government's AI Playbook, updated in 2025, highlights that AI systems need continuous monitoring, explicit human accountability, and documented testing for bias, safety, and performance drift. The bigger issue for CTOs is practical: generic QA advice still rarely explains how to handle rapid changes in models, prompts, and data pipelines, which is why this summary of AI assurance and continuous monitoring expectations is so relevant.
That means your quality assurance processes should expand to cover:
- Prompt and model change control
- Monitoring for drift and unexpected behaviour
- Documented evaluation criteria for safety and performance
- Human review where automated decisions affect people
If you're modernising both engineering delivery and testing, this perspective on AI-driven software development and testing is useful because it connects automation, delivery speed, and governance rather than treating AI as a novelty.
The winners here won't be the teams with the most AI features. They'll be the teams that use AI with disciplined assurance.
Your Action Plan for High-Velocity Quality
CTOs don't need another lecture on best practice. They need a practical move set.
Start with the system you already have. Look at where work slows down, where confidence drops, and where defects or compliance concerns appear late. That will tell you more than any generic maturity model.
Step one: audit for business impact
Review your current quality assurance processes against delivery outcomes, not team activity.
Ask:
- Where does rework enter the flow?
- Which checks are manual because the pipeline can't enforce them yet?
- Which release decisions rely on opinion rather than evidence?
- Where are compliance or data-handling controls poorly documented?
You're not looking for perfection. You're identifying the few constraints that most damage speed and confidence.
Step two: reset ownership across the team
Stop treating QA as a department-level responsibility. Make quality part of every role definition and working agreement.
Do three things quickly:
- Rewrite “done” so it includes testability, evidence, and operational readiness.
- Give QA specialists authority over strategy and risk, not just execution.
- Hold developers, product leads, and managers accountable for quality outcomes, not handoffs.
This cultural shift matters more than any framework label. Without it, the rest becomes process theatre.
Step three: build your roadmap for continuous quality
Don't try to automate everything at once. Sequence the work.
Start with high-value controls:
- Fast merge-gating tests
- API and contract coverage
- A small set of critical end-to-end journeys
- Traceability for regulated or sensitive workflows
- Monitoring that confirms releases behave as intended
Then strengthen the surrounding system. Improve test data handling. Rationalise your toolchain. Add AI-enabled support where it reduces manual effort without weakening oversight.
The outcome you want is simple. Faster delivery with better control. Not speed at the expense of quality, and not quality theatre at the expense of progress.
If you want a delivery partner that treats quality as a business accelerator, Rite NRG is built for that model. Their senior nearshore teams, product-first advisory approach, and AI-powered delivery practices help CTOs build predictable QA functions, improve release confidence, and ship faster without giving up control.

