


If you're running a SaaS product right now, you probably recognise the pattern. Sales closes a promising deal. Product adds a stretch goal. Engineering says yes because saying no feels risky. Then deadlines slide, incidents pile up, and hiring becomes a panic move instead of a strategy.
That isn't a staffing problem. It's a capacity planning problem.
CTOs who treat capacity planning as admin stay reactive. CTOs who treat it as a delivery discipline gain speed, predictability, and room to make better bets. That's the difference between a team that constantly absorbs pressure and a team that delivers with intent. At Rite NRG, that mindset sits inside the #riteway approach: Extreme Ownership, proactive communication, and clear accountability for outcomes, not just output.
Beyond Firefighting From Reactive to Proactive Delivery
Reactive delivery has a familiar smell. Sprint plans look full on Monday. By Wednesday, two engineers are pulled into support, one dependency slips, and a release date turns into “best effort”. Nobody planned failure. But nobody owned capacity with enough precision to prevent it.
That matters because delivery chaos compounds into business problems fast:
- Roadmap credibility drops when product dates keep moving
- Team energy falls when every week feels like recovery from the last one
- Commercial confidence weakens when leadership can't tell investors what will ship and when
- Hiring quality suffers when recruitment is driven by urgency instead of capability gaps

Capacity planning is not an ops side quest
The core logic behind capacity planning is older than software. Britain had to confront it during the industrial era, when scaling factories and railways forced organisations to coordinate labour, plant, and transport against forecast demand, as outlined in Netstock's historical view of capacity planning. That's the same problem a SaaS company faces when customer demand outruns delivery bandwidth.
The lesson is simple. Scaling always exposes coordination limits. Software doesn't escape that. It just hides it for a while behind heroic effort.
Practical rule: If your roadmap depends on people repeatedly “stepping up”, you don't have a strong delivery engine. You have unmanaged risk.
What Extreme Ownership looks like in practice
A CTO with Extreme Ownership doesn't say, “The team missed the date.” They ask, “What signals did we ignore, and what system do we need so this becomes predictable?”
That shift changes behaviour:
- You stop planning from hope. You plan from observed throughput, availability, and constraints.
- You stop treating every request as equal. You force trade-offs earlier.
- You stop hiring generically. You hire or augment where the bottleneck sits.
- You build a repeatable operating rhythm. That's where real operational efficiency in delivery systems comes from.
Predictable delivery isn't glamorous. It wins anyway. Customers trust it. Boards trust it. Teams trust it. And once your organisation trusts your delivery forecasts, product strategy gets sharper because decisions are no longer built on optimism alone.
Forecasting Demand Like a Strategic Partner
Most capacity plans fail before they start because demand forecasting is weak. Leadership sets ambitious goals, teams estimate loosely, and nobody reconciles the gap until the quarter is already off track.
A stronger approach starts with one hard rule. Use measured baselines, not staffing assumptions. High-precision capacity plans should begin with measured baseline utilisation, historical performance data, and continuous monitoring of actual consumption, as explained in Productive's guide to IT capacity planning.
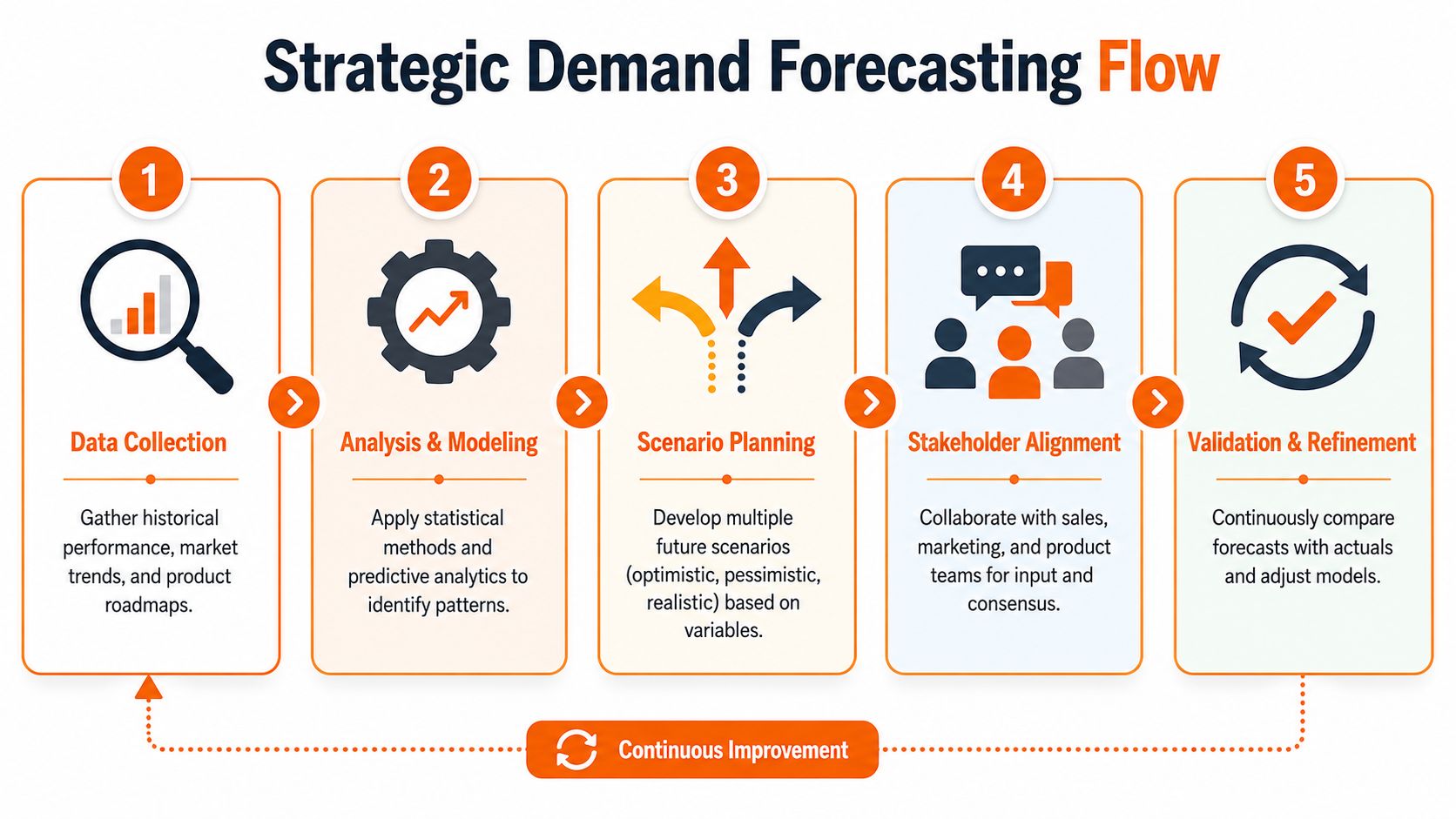
Start with evidence, not ambition
If your roadmap says “launch three major initiatives”, that is not a demand forecast. It's an aspiration.
Your forecast should blend four inputs:
- Product roadmap demand tied to actual delivery effort in hours, service load, or constrained specialist time
- Sales pipeline pressure that may pull roadmap items forward or create onboarding and integration spikes
- Historical throughput from the teams and systems that will carry the work
- Operational load such as incidents, platform maintenance, security work, and support for existing customers
Forecasting gets serious when you model the work that steals delivery time, not just the work leadership wants to celebrate.
Top-down and bottom-up are both useful
Use both forecasting lenses. Just don't confuse them.
| Approach | Best For | Pros | Cons |
|---|---|---|---|
| Top-Down | Annual planning, board alignment, roadmap framing | Fast, strategic, tied to revenue and business goals | Can hide delivery constraints and create false confidence |
| Bottom-Up | Sprint and quarter planning, execution realism | Grounded in team capability and actual workload | Can be too narrow if teams don't see upcoming commercial shifts |
Top-down forecasting starts with business targets, product bets, or contractual commitments. Then you translate those into delivery demand. It's useful when the company needs directional clarity.
Bottom-up forecasting starts with real team capacity, known work, and observed throughput. Then you aggregate upwards. It's useful when you need believable plans.
The strongest CTOs force these two views to meet. If top-down ambition and bottom-up reality don't align, don't paper over the mismatch. Escalate it. That's leadership.
A practical forecasting sequence
Run the process like this:
- Collect baseline data. Pull delivery throughput, incident load, support effort, and infrastructure consumption.
- Translate roadmap items into demand. Convert ideas into effort on the constrained parts of your system.
- Layer scenario pressure. Include major deals, compliance deadlines, migrations, and seasonal demand patterns.
- Review with functional leaders. Product, engineering, sales, and customer teams need one shared picture.
- Refine continuously. A forecast isn't a document. It's a management loop.
If you still rely on broad manual estimates from team leads without validating them against actual performance, you're guessing. Guessing is expensive.
Sizing Teams and Infrastructure for Outcomes
The default reaction to delivery stress is “we need more people”. Sometimes that's true. Often it isn't.
If your release pipeline is slow, your architecture is brittle, or one specialist role blocks all progress, adding headcount can increase cost without increasing throughput. That's why mature capacity planning starts with constraints, not recruitment.
Stop thinking in headcount alone
In complex systems, capacity problems are often solved by redesigning the network instead of just adding more bodies. That framing appears clearly in Vizient's analysis of capacity across care settings, where the argument is that throughput issues aren't always solved by adding beds. The same logic applies to SaaS delivery.
Your bottleneck may be:
- A platform choke point such as slow deployments or fragile environments
- A skill choke point such as one architect, one SRE, or one data engineer approving everything
- A decision choke point where product, compliance, or leadership approvals stall execution
- A work-location choke point where the wrong work sits with the wrong team
That last point is routinely missed. Some work should stay with your core team. Some should move to a platform squad. Some should be automated. Some should be shifted to a specialist partner.
Design the delivery network
Think like an operator, not just a recruiter.
A good capacity design asks:
- Where should this work happen?
- What capability does it require?
- What happens when demand lands unevenly?
- What relief valve do we use when one lane overloads?
If you're mapping schedules across multiple teams or service windows, resources like Headset Army's scheduling software recommendations are useful because they show how tooling can expose workload imbalance before it turns into missed commitments.
Adding engineers to a system with a hidden bottleneck is like opening another checkout when the real queue is stuck at payment authorisation.
Infrastructure belongs in the same conversation. A team can't deliver predictably on top of flaky environments and manual provisioning. Tightening deployment pipelines, environment consistency, and release automation through practices like infrastructure as code often provides more usable capacity than another rushed hire.
Measuring What Matters KPIs and SLAs
A capacity plan without metrics is a spreadsheet with ambition. You need operating signals that tell you whether capacity is healthy, constrained, or being wasted.
One core metric in UK firms is capacity utilisation, defined as the ratio of output or billable time to total available hours, with long-range planning commonly running on a two- to 12-month horizon, according to Productive's capacity planning metrics guidance. That matters because it gives delivery leaders a practical window for planning instead of vague “long term” language.
The KPI set I'd put in front of a CTO
Track a small set of metrics that expose flow and risk.
- Capacity utilisation tells you whether teams are underused, overloaded, or sitting in a workable operating band.
- Lead time for changes shows how long it takes to move from approved work to production value.
- Deployment frequency tells you whether your system supports fast, low-friction release.
- Mean time to recovery exposes operational resilience.
- SLA compliance shows whether service commitments are realistic under current load.
- Capacity gap or surplus makes the planning conversation explicit instead of political.
What each metric means for the business
High utilisation can look efficient on paper while killing adaptability. If everyone is fully committed, nobody can absorb urgent work, production issues, or strategic opportunities.
Lead time is where customers feel your delivery model. If lead time drifts, roadmap confidence drops and revenue-enabling features arrive later than planned.
Here's a useful explainer to support leadership conversations:
SLA compliance is where commercial promises meet operating reality. If you miss SLAs because your team is stretched, that isn't a support issue. It's a capacity issue.
Board-level lens: The point of KPI tracking isn't to prove teams are busy. It's to prove the business can deliver commitments with control.
Keep the metric system honest
A few rules keep this useful:
- Review trends, not snapshots. One good sprint proves nothing.
- Connect metrics to decisions. If utilisation rises and lead time worsens, stop adding work.
- Pair delivery and operational metrics. Shipping fast while recovery time degrades is not healthy capacity.
- Make ownership explicit. Every KPI needs one accountable leader.
If your current dashboard celebrates output without exposing delivery risk, it isn't helping you manage capacity. It's helping you hide it.
Proactive Risk and Scenario Planning
Most delivery organisations say they plan. Few test the plan against disruption.
That's a mistake. Capacity planning becomes real when you stress it. If you don't model shocks, your first serious surprise becomes a live-fire exercise with customers watching.
A practical workflow is to define the horizon, identify the bottleneck, choose the least-cost capacity lever, and validate the plan with a what-if scenario, including cases such as a 15% increase in demand, as outlined in PlanetTogether's capacity planning workflow. Skipping that scenario test is a common reason teams add cost without improving throughput.
Scenario planning is where leadership earns its keep
The point isn't to predict the future perfectly. The point is to decide in advance how you'll respond when the future misbehaves.
Run scenario planning around the risks that can hurt your business:
- A growth spike that increases onboarding, infrastructure load, support volume, or feature pressure
- A talent shock such as the loss or absence of a key engineer
- A dependency failure involving a supplier, platform vendor, or internal shared service
- A roadmap compression caused by a customer commitment or funding milestone
Use levers, not panic
When a scenario exposes a gap, don't jump straight to permanent hiring. Choose the least-cost lever that protects outcomes.
That usually means comparing options such as:
- Scheduling changes, where lower-priority work moves out of the critical path
- Cross-training, where specialist dependency reduces over time
- Temporary augmentation, where you add capacity for a defined period
- Selective outsourcing, where work with clear interfaces moves to a partner
- Scope control, where you cut low-value commitments instead of overloading the team
A resilient plan doesn't assume calm conditions. It prices in disorder and decides how much flexibility the business is willing to buy.
If your organisation reviews risks only after dates slip, you don't have scenario planning. You have post-incident commentary.
Tooling Governance and Cadence
Tools don't fix weak ownership. Governance does.
I've seen startups overcomplicate capacity planning with enterprise software before they have clean data. I've also seen scale-ups cling to spreadsheets long after the business needed stronger visibility. Both mistakes create drag because the tool and the operating model are out of sync.
Pick the lightest tool that supports disciplined decisions
For an early-stage SaaS company, a structured spreadsheet tied to Jira, Linear, Azure DevOps, or ClickUp can be enough. The goal is visibility into demand, constrained roles, and committed versus available capacity.
As the organisation grows, you usually need a system that can handle:
- Resource visibility across teams and functions
- Historical reporting for throughput and utilisation
- Scenario modelling for quarterly planning
- Integration with delivery tools and incident systems
The tool matters less than the discipline around it. If data isn't current, no dashboard will save you.
Set the cadence and force accountability
A useful governance model is simple:
- Quarterly strategic review to align capacity with roadmap, commercial goals, and platform risk
- Monthly operational review to compare plan versus actuals and resolve emerging gaps
- Bi-weekly tactical check-in for team-level adjustments, dependencies, and exceptions
Ownership should be explicit. The CTO should own the decision system. Engineering managers and delivery leaders should own the accuracy of inputs. Product leadership should own demand clarity and prioritisation. Finance should understand the implications of capacity choices, especially when trade-offs affect hiring or partner usage.
Extreme Ownership becomes operational. No vague accountability. No “someone should update the model”. One plan. Current data. Clear decisions. Repeated on cadence until it becomes part of how the business runs.
Scaling Capacity with Nearshore Partners
When demand clearly exceeds internal capacity, you have three basic options. Slow the roadmap. Hire internally. Add external capacity. Good CTOs evaluate all three. They don't default to one out of habit.
Nearshore partners are often misunderstood because leaders frame them as outsourcing. That's too shallow. In a serious capacity strategy, nearshore is a capacity lever. It can absorb spikes, add scarce expertise, or create a structured path to scale delivery without forcing rushed permanent hiring.
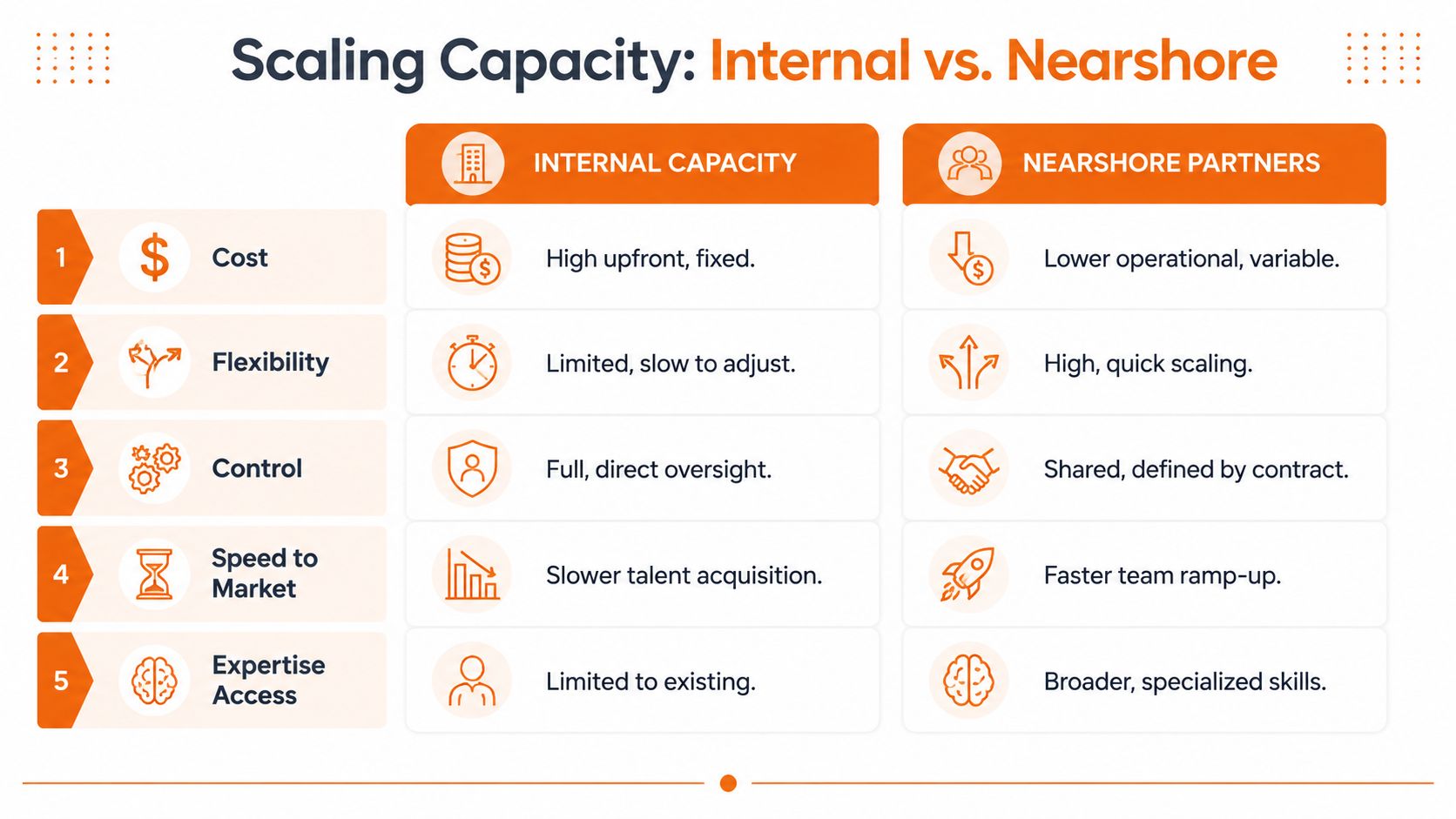
Dedicated team or BOT
These two models solve different problems.
| Model | When it fits | What you get | Watch-outs |
|---|---|---|---|
| Dedicated Team | You need capacity or specialist skills quickly inside your current delivery model | Embedded engineers working inside your tools, rituals, and priorities | Requires strong internal product and engineering leadership |
| Build-Operate-Transfer | You want to establish a longer-term delivery centre with eventual ownership | A partner builds the team and operating setup, then transfers control to you | Needs a clear transfer plan, governance model, and leadership commitment |
A Dedicated Team works well when the bottleneck is immediate. You need shipping capacity, platform capability, or senior hands in a known area. The team plugs into your roadmap and delivery system.
A Build-Operate-Transfer model is more structural. It makes sense when you want to build your own R&D footprint without carrying the full initial burden of hiring, compliance, local operations, and setup.
Use partners as planned capacity, not emergency cover
Many companies err by bringing in an external team only after delivery has already become chaotic. That usually creates a rough onboarding, unclear ownership, and poor outcomes.
A better move is to treat external capacity as part of the plan:
- For roadmap acceleration, where a parallel stream can move without overloading the core team
- For specialist bottlenecks, where hiring locally may be too slow or uncertain
- For resilience, where you need a flexible buffer instead of fixed permanent cost
- For regional expansion, where you want to establish capability in a new location
If you're evaluating this route, nearshore software delivery models are worth reviewing alongside your internal hiring plan, because the right partner model depends on whether you need immediate throughput, specialist capability, or a future-owned delivery centre.
My recommendation is blunt. Don't wait until your roadmap is already slipping. Decide in advance which capacity lever you'll pull, under what conditions, and how that choice supports business outcomes.
If capacity planning has become a source of friction instead of control, talk to Rite NRG. We help SaaS leaders turn delivery demand into a workable operating model, whether that means sharpening forecasting, improving delivery governance, or adding nearshore capacity through dedicated teams or a BOT structure.

