


Your product team is busy all day and still misses dates. Engineering closes tickets, but customers don't feel momentum. Founders add headcount, then wonder why delivery still feels slow, expensive, and unpredictable.
That's an operational efficiency problem.
Not a motivation problem. Not a talent problem. Not even a tooling problem on its own. It's the gap between effort going in and customer value coming out. If you run a SaaS company, that gap decides how fast you enter a market, how much waste you tolerate, and how often quality problems come back to tax your roadmap.
Why Operational Efficiency Is Your Unfair Advantage
A lot of SaaS leaders treat operational efficiency like a back-office concern. That's a mistake. It's one of the few advantages you can build internally and compound quickly.
When roadmap pressure rises, many organizations react incorrectly. They pack additional tasks into sprints, increase the frequency of meetings, and demand more from engineers. That creates motion, not progress. You get more parallel work, more handoffs, more rework, and less trust in delivery dates.

The market isn't giving you free productivity
The UK context matters here. In a low-productivity environment, firms that reduce cycle time, downtime, and rework can create a meaningful competitive advantage. ONS data show that UK output per hour in 2024 was only around 1.5% above its 2008 level, which means businesses have had to create their own efficiency gains rather than rely on broad economic tailwinds, as explained in this analysis of operational efficiency and UK productivity.
For founders and CTOs, the lesson is simple. You won't drift into efficient delivery because the economy got easier. You have to build it deliberately.
Operational efficiency is what turns a product roadmap into shipped value with less waste. It helps you release sooner, spend more carefully, and protect quality while you scale. That's the difference between a SaaS company that controls its pace and one that keeps reacting.
Practical rule: If your team is working flat out and customers still wait too long for meaningful improvements, your delivery system is leaking value.
Ownership is the multiplier
The #riteway mindset matters here. Frameworks help, but they don't fix a culture where everyone waits for someone else to solve bottlenecks. Efficient teams act differently. Product owns clarity. Engineering owns delivery health. Leadership owns prioritisation. Partners own outcomes, not excuses.
That's what Extreme Ownership looks like in practice. Someone spots a blocker and moves on it. Someone sees a risky dependency and raises it early. Someone notices QA is overloaded and redesigns the workflow before release quality slips.
Operational efficiency also connects directly to financial discipline. If you're tightening spend while trying to maintain growth, a strong operating model has to sit alongside a strong money model. This guide to mastering financial operations is useful because it shows how control, visibility, and process discipline have to work together.
The companies that win aren't always the ones with the biggest teams. They're the ones that convert effort into outcomes faster than everyone else.
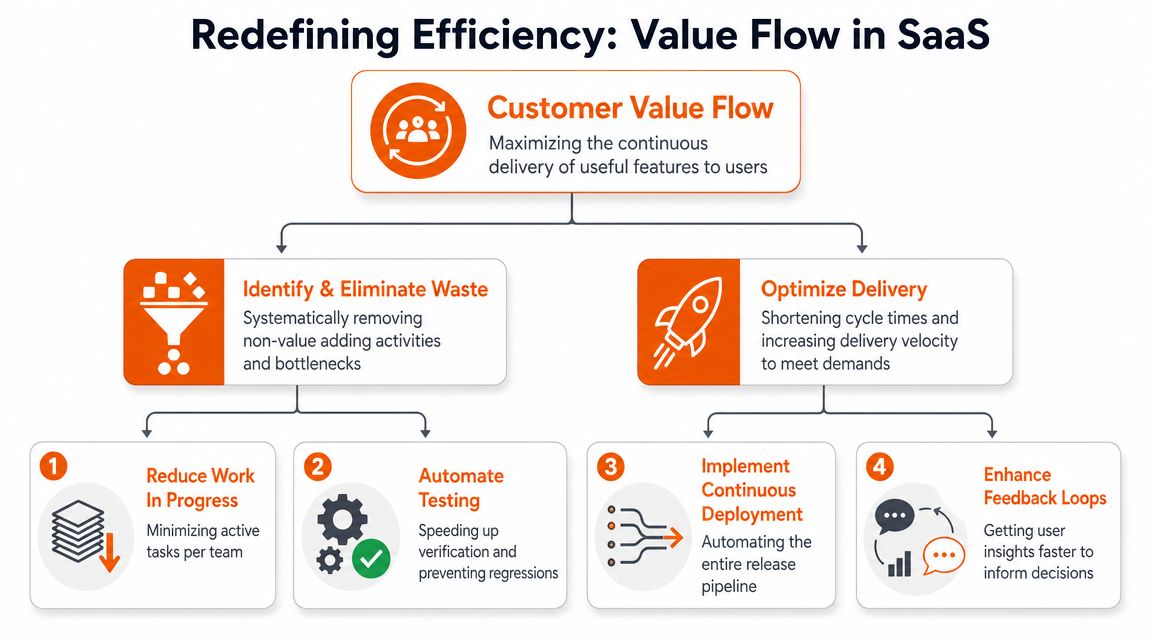
Redefining Operational Efficiency for SaaS Teams
Forget the old factory-floor definition. SaaS teams don't exist to produce more output for its own sake. They exist to move useful customer value from idea to deployment with as little drag as possible.
That changes the definition entirely.
For a SaaS company, operational efficiency means maximising value flow while minimising waste. Waste includes waiting on approvals, unclear requirements, duplicated QA, context switching, avoidable bugs, slow handoffs, and features that ship without moving any business metric that matters.
People decide whether the system works
Most delivery problems get mislabelled as technical. Often they're people problems in disguise.
A strong SaaS team needs clear accountability, fast decisions, and the right level of seniority in the room. If nobody owns outcome trade-offs, work drifts. If your engineers are waiting on fragmented product input, they can't move with confidence. If your team structure forces every decision up a chain, velocity dies.
Look at people through three lenses:
- Decision ownership. Who decides scope, sequencing, and release readiness?
- Team design. Are you organised for flow, or for internal politics?
- Capability mix. Do you have enough senior product, engineering, QA, and delivery judgement to avoid preventable churn?
Process either accelerates value or blocks it
Process should reduce friction. Too many teams do the opposite.
A healthy delivery process makes it easy to prioritise, build, test, release, and learn. An unhealthy one creates queues at every stage. You see ticket ageing, bloated work in progress, and endless “almost done” work. Teams look productive because everything is busy, but customer value moves slowly.
Good process in SaaS usually means:
- Tighter handoffs between product, design, engineering, and QA
- Short feedback loops so bad assumptions get caught early
- Clear release paths so shipping doesn't become an event
- Visible constraints so everyone knows where work stalls
Operational efficiency in SaaS isn't about keeping everyone occupied. It's about keeping value moving.
Technology should remove friction, not add ceremony
The technology pillar matters, but not as a trophy cabinet of tools. Tooling should support flow, visibility, and repeatability.
The UK pattern is useful here. Government-backed business surveys have shown that many firms use at least one digital technology, but adoption of more advanced tools is much lower. Cloud computing is used by roughly half of firms, while artificial intelligence use has historically been in the low double digits and only recently started rising more quickly, as outlined in this UK-focused review of digital adoption and operational efficiency.
The important point isn't “buy more software”. It's this: digitally mature firms tend to coordinate work better, automate more intelligently, and use data more effectively. In SaaS delivery, that usually means better CI/CD discipline, better QA automation, better reporting, and fewer manual bottlenecks.
People, process, and technology are not separate conversations. They are one operating system. If one is weak, the whole delivery engine slows down.
Frameworks and KPIs to Diagnose Inefficiency
If you want to improve operational efficiency, stop asking whether the team is “busy”. Busy teams can still be badly run. You need a diagnosis that exposes where value is getting stuck.
One useful framework is Overall Equipment Effectiveness, or OEE. It comes from manufacturing, but the logic translates well to software delivery if you use it properly. OEE multiplies Availability, Performance, and Quality into one score. A team with 95% Availability, 70% Performance, and 80% Quality only reaches 53.2% OEE, which shows how one weak area can drag down the whole operation, as shown in this breakdown of operational efficiency metrics and OEE.
Translate OEE into software delivery language
Don't apply OEE mechanically. Translate it into terms your product and engineering leaders can act on.
- Availability means usable team capacity. Are people consistently available to move planned work, or are priorities, incidents, and meetings destroying focus?
- Performance means delivery flow against a realistic baseline. Are stories and features moving through the system at a healthy pace, or are they sitting in queues?
- Quality means how much work lands cleanly the first time. Defects, escaped bugs, failed releases, and rework all belong here.
Pinpointing inefficiency is difficult, for it rarely lives in one obvious place. Many teams blame engineering speed when the actual issue is poor quality upstream or unstable priorities from leadership.
Track business-facing KPIs, not activity theatre
A lot of SaaS dashboards are packed with noise. Story points completed, lines of code, and hours logged don't tell a founder or CTO what they need to know.
Here's a better filter.
| Focus Area | Vanity Metric (Avoid) | Value-Driven KPI (Track) |
|---|---|---|
| Delivery output | Story points completed | Cycle time |
| Engineering activity | Lines of code written | Lead time for changes |
| Sprint optics | Tickets closed | Rework rate |
| Team utilisation | Hours assigned | Throughput of released customer value |
| Release volume | Number of deployments alone | Deployment stability and defect follow-up |
| Planning confidence | Velocity in isolation | Predictability of committed delivery |
A burndown chart can still help if you use it as a warning sign rather than a success badge. This Tekk.coach burndown chart walkthrough is worth a look because it shows how to read delivery slippage before it turns into deadline theatre.
Resource visibility matters more than most teams admit
A surprising number of delivery issues come from poor allocation, not poor effort. The same people get pulled into roadmap work, support escalations, interviews, stakeholder calls, and firefighting. Then leaders act shocked when sprint commitments slip.
If your team can't see capacity clearly, planning will always be soft. That's why mature delivery organisations invest in better workload visibility and planning discipline. A practical place to start is understanding how resource management software in delivery teams supports capacity planning, dependency control, and more realistic commitments.
The fastest way to improve a delivery system is to identify where work waits, where work breaks, and where work gets done twice.
Measure those three things well and operational efficiency stops being abstract.
High-Impact Strategies to Boost Delivery Velocity
Monday starts with a standup. By Thursday, the sprint is already off track. A developer is waiting on product clarification, QA is buried under late handoffs, and release prep has turned into a scramble. That is not a productivity problem. It is an operating model problem.
SaaS teams struggling with delivery velocity need structural fixes that cut delay, reduce waste, and let nearshore teams ship with confidence. The best gains come from tightening ownership, shrinking queues, and automating repetitive work that slows releases every single week. Tools help. Extreme Ownership is what makes the tools matter. At #riteway, teams own outcomes, surface blockers early, and fix issues before they spread.

Build around autonomous pods
If feature delivery still moves across separate departments for discovery, development, QA, and release, expect drag. Nearshore SaaS delivery works better with cross-functional pods that own a problem from refinement to production.
That does not mean every person is a generalist. It means the pod has the authority and coverage to keep work moving without waiting on three other teams to answer, approve, or test. Product, engineering, QA, and delivery should share one goal, one backlog focus, and one definition of done.
That structure improves speed for a reason. Handoffs drop. Context stays inside the team. Decisions happen faster. Defects surface earlier. Accountability gets sharper because nobody can pass a blocker to another department and call it done.
Ownership stops being a slogan at this stage. If a pod sees a dependency, it resolves it or escalates it immediately. If requirements are weak, it pushes for clarity before build starts. That behavior protects time-to-market far more than another ceremony ever will.
Cut work in progress before you add people
Founders and CTOs often respond to slow delivery by adding headcount or opening more parallel workstreams. That usually makes throughput worse.
Limit active work hard. Finish before starting. If a feature is blocked by dependency, missing decisions, or unclear scope, mark it clearly and remove the blockage. Do not let teams hide stalled work inside "in progress" while they start new items to look busy.
This matters even more in nearshore setups, where timezone overlap is valuable and should not be wasted on status chasing. A smaller set of active priorities gives distributed teams cleaner handoffs, faster review cycles, and fewer expensive restarts.
Value stream mapping helps here because it exposes where delivery slows down. The slowest point is often not coding. It is waiting for approval, clarification, test coverage, or release signoff. Fix those points first. That is where wasted effort turns into lost margin.
Use AI where it removes repeatable delivery drag
AI should reduce friction in the workflow, not decorate a broken process. If the team lacks ownership, clean handoffs, or clear release criteria, AI will speed up confusion.
Use it where rules repeat, inputs are structured enough, and fast response matters. Good examples include test case generation, regression support, release note drafting, defect triage, documentation updates, and delivery reporting. For QA specifically, this e2eAgent.io AI testing workflow shows how automated verification can reduce bottlenecks without removing engineering judgment.
Teams pushing further should also examine how agentic engineering in software delivery can handle repetitive operational work while keeping human accountability in place. That combination matters. Automation handles volume. Owners handle decisions.
Here's a useful primer on the mindset behind that shift:
Protect velocity by protecting resilience
Delivery velocity collapses fast when resilience is weak. One unstable release, one preventable security incident, or one rollback-heavy deployment can wipe out weeks of apparent efficiency.
Lean teams still need release discipline, monitoring, rollback readiness, and clear incident ownership. Cut those corners and the savings disappear into downtime, customer support load, and rework. Speed without control is just deferred cost.
Speed without resilience is fake efficiency. You only realise the cost after the outage, the rollback, or the customer escalation.
For founders and CTOs running nearshore delivery, the standard should be simple. Every team owns delivery outcomes end to end. Every blocker gets surfaced early. Every repeated task gets automated where it makes sense. That is how you ship faster, spend less, and protect quality at the same time.
One practical option for founders and CTOs that need support with process automation, delivery visibility, and nearshore execution is Rite NRG, which works as a software delivery partner rather than a staffing list.
A Phased Roadmap for Lasting Improvement
Most operational efficiency programmes fail for one reason. Leaders try to fix everything at once. That creates change fatigue, vague accountability, and no visible wins.
A better approach is phased. You need a baseline, then a controlled pilot, then scale. That's how you improve delivery without destabilising the business.

Phase 1 Audit and baseline
Start by examining how work flows, not how your process documents say it flows. Pull in product, engineering, QA, and leadership. Identify where work waits, where requirements wobble, and where defects return.
Your baseline should include a practical view of cycle time, release friction, rework patterns, and capacity distortion. This phase also forces leadership to confront prioritisation habits that subtly impede delivery.
A useful output from this phase is a short list of operational constraints, ranked by business impact. Not a giant transformation deck. Just the few issues that most directly slow value delivery.
Phase 2 Pilot and refine
Pick one team, one product area, or one critical workflow. Run the improvement there first.
That might mean introducing stronger sprint entry criteria, reducing work in progress, tightening QA automation, or restructuring into a more autonomous pod. Keep the pilot narrow enough to learn quickly and broad enough to expose real dependencies.
Three things matter here:
- Visible ownership so the pilot doesn't become a side project
- Fast feedback so adjustments happen weekly, not quarterly
- Clear success criteria tied to speed, cost discipline, or quality outcomes
A pilot works when it proves a better way of operating, not when it produces a pretty slide for leadership.
If your leadership team needs a practical framework for sequencing these decisions, this product and delivery roadmap strategy guide is a useful reference point.
Phase 3 Scale and automate
Once the pilot works, scale what was proven. Don't scale everything that was attempted.
Many companies frequently make a mistake. They standardise too early, automate messy workflows, and accidentally spread bad habits faster. Scale only the changes that improved flow and made ownership clearer.
At this stage, operational efficiency should start showing up in delivery economics as well as execution quality. The operational efficiency ratio is calculated as Operating Expenses ÷ Total Revenue × 100, and reducing that ratio below 15% through better processes and automation supports faster, more cost-effective delivery for SaaS partners and their clients, as described in this operational efficiency ratio guide.
That ratio matters because it turns delivery improvement into a board-level conversation. Better flow isn't just an engineering win. It affects margin, pricing flexibility, and the ability to invest without bloating cost.
From Efficient Operations to Market Domination
Operational efficiency isn't a side initiative. It's the operating discipline that turns product ambition into shipped outcomes.
The strongest SaaS teams don't just adopt better tools or rewrite a few ceremonies. They build a culture where people take ownership early, act on signals quickly, and fix root causes instead of managing symptoms. That's why the #riteway principles matter. Extreme Ownership, high energy, and proactive delivery habits make every framework more effective.
Culture decides whether improvement sticks
You can map workflows, tighten KPIs, and automate test runs. None of that will last if your culture still rewards delay, ambiguity, and passive behaviour.
Efficient teams escalate risk early. They don't hide behind status updates. They challenge bad prioritisation. They protect focus. They care about speed, cost, and quality at the same time because that's how healthy SaaS businesses grow.
A founder feels it in faster releases. A CTO sees it in fewer avoidable bottlenecks. Customers notice it in steadier product progress.
Efficient delivery becomes strategic leverage
When your operation runs well, everything gets easier. Market experiments happen sooner. Quality issues shrink before they infect the roadmap. Teams trust delivery dates more. Leaders spend less time chasing updates and more time making useful decisions.
That's the actual payoff. Operational efficiency creates room to move.
The goal isn't a busier team. The goal is a delivery engine that turns effort into market traction with less waste.
If you want better outcomes, stop treating inefficiency as normal startup chaos. Fix the system. Build the habits. Raise the standard of ownership.
If you want a delivery partner that works like an advisor, not a body shop, talk to Rite NRG. They help SaaS teams improve operational efficiency through senior nearshore delivery, product-minded execution, and proactive support that keeps speed, cost, and quality in balance.

