


Your roadmap probably looks healthy on paper. New features are scoped, investors want velocity, customers expect reliability, and your team is pushing hard to hit the next release. Then a dependency alert lands, a rushed hotfix exposes more than it solves, and suddenly product delivery stops while engineering scrambles to contain security debt that's been building for months.
That's the pattern I see most often in SaaS teams that move fast without discipline. They don't lose time because security is too strict. They lose time because security was treated as cleanup work instead of delivery infrastructure.
Secure coding practices are how you stop that cycle. Done properly, they don't slow teams down. They remove rework, tighten decision-making, and make releases more predictable. That's the operational standard behind the #riteway methodology. Take Extreme Ownership, build guardrails early, and make secure delivery the default path instead of an occasional rescue mission.
Stop Shipping Vulnerabilities Start Accelerating Value
A familiar scenario plays out in scale-ups every week. The team ships quickly, wins early customers, adds integrations, and starts layering in third-party packages to keep momentum high. Nobody thinks they're being reckless. They're being practical.
Then reality hits. A customer security questionnaire exposes gaps. A new enterprise prospect asks hard questions about patching and support. An engineer finds a vulnerable package deep in the stack, and nobody is fully sure who owns it, where it's used, or how risky the blast radius is. The roadmap doesn't pause politely. It slams into a wall.
That's not just a security problem. It's a delivery problem, a trust problem, and a leadership problem.
Security debt is delivery debt
When teams postpone secure coding practices, they create hidden drag in every sprint:
- Release confidence drops because changes carry unknown risk.
- Engineering capacity shrinks because senior people get pulled into reactive fixes.
- Sales cycles get harder because prospects sense uncertainty.
- Product planning gets distorted because urgent remediation displaces roadmap work.
Secure code isn't a tax on speed. It's the operating discipline that stops fast teams from sabotaging themselves.
The strongest delivery teams don't bolt security on at the end. They build it into design, code review, testing, release, and maintenance. They know that every avoidable vulnerability introduced upstream becomes an expensive coordination problem downstream.
The proactive model wins
The old model says ship first and harden later. That model fails in modern SaaS because your platform is never standing still. You're updating code, libraries, infrastructure, workflows, and customer-facing integrations continuously. A reactive posture can't keep up.
The better model is simple. Make secure coding practices part of normal execution. Treat ownership as explicit. Automate checks where machines outperform humans. Keep humans focused on judgement, architecture, and prioritisation.
That's where Extreme Ownership matters. Somebody owns the code. Somebody owns the dependency. Somebody owns the fix. Somebody owns the customer impact. When ownership is clear, teams move faster because they don't waste time asking who should act.
The Real Business Case for Secure Code
Leaders who still frame security as overhead are looking at the wrong ledger. The actual cost isn't the review step, the test automation, or the extra design discipline. The true cost is what happens when insecure code contaminates delivery.
A weak security posture doesn't just create risk exposure. It delays launches, drags out due diligence, complicates procurement, and forces product teams into unplanned remediation cycles. Founders feel it in pipeline friction. CTOs feel it in team focus. Product managers feel it when roadmap commitments slip for reasons they didn't plan for.
Secure code protects momentum
If you want predictable growth, secure code needs to be treated as a commercial enabler.
Here's why:
- Investors and buyers look for operational maturity. A team that can explain how it designs, tests, patches, and supports software looks easier to back.
- Enterprise customers buy confidence. They're not only buying features. They're buying reliability, supportability, and evidence that your platform won't become their problem.
- Product teams ship better when surprises shrink. Secure coding practices reduce the number of late-stage discoveries that derail releases.
- Engineering leaders keep capacity for innovation. Less firefighting means more room for roadmap work.
Product lifecycle discipline signals seriousness
One of the smartest parts of the UK approach is that support obligations are tied to lifecycle thinking. The UK's Software Security Code of Practice requires a minimum one-year notice before ending software support, which directly reduces the risk of unpatched legacy systems and pushes vendors to take a longer-term view of maintenance and third-party validation, as outlined in this analysis of the UK Software Security Code.
That matters commercially. Teams that plan support windows properly don't trap customers on abandoned versions, and they don't force emergency migrations under pressure. They create a more stable operating environment for revenue retention and platform trust.
Board-level view: secure coding practices strengthen revenue resilience because they reduce avoidable disruption in product delivery, customer confidence, and support planning.
Insecure code creates opportunity cost
The opportunity cost of poor coding discipline is often underestimated. The focus tends to be on incident prevention only. That's too narrow.
The bigger business losses usually show up as:
| Business pressure | What insecure code causes |
|---|---|
| Enterprise sales | Longer security reviews and slower approvals |
| Product delivery | More rework, more blocked releases |
| Team effectiveness | Senior engineers pulled into reactive clean-up |
| Customer trust | More scrutiny around maintenance and patching |
A healthy security posture tells the market your team is organised. That message matters. Not because it sounds good in a slide deck, but because customers and investors can usually tell when a team is improvising.
Core Principles of Unbreakable Software
Strong software isn't built by memorising a checklist. It's built by applying a few hard principles consistently, even when deadlines tighten.
The UK Government's 2024 Software Security Code of Practice sets a baseline of 14 principles across secure design, build environment security, secure deployment and maintenance, and communication with customers. It also requires vendors to understand software composition and assess third-party component risk. That matters because over 60% of recent UK software breaches originated from insecure dependencies, according to the UK Government's Software Security Code of Practice.

Secure by design means no security theatre
Secure by design means you make security decisions at architecture stage, not after a penetration test embarrasses the team. You choose safer defaults, tighter access boundaries, and cleaner service interactions before code sprawl makes those choices painful.
Secure by default means the system starts in the safest sensible state. It doesn't depend on every user, admin, or engineer remembering to switch protection on later.
That's why data handling needs architectural discipline too. If your team is revisiting how application data is stored and protected, this guide to secure database storage is a useful practical reference because it brings storage decisions back to fundamentals instead of tool hype.
Least privilege keeps mistakes small
Every system has bugs. The question is whether a bug becomes an inconvenience or a crisis.
The principle of least privilege limits what users, services, and components can do. If one part fails, it shouldn't get unrestricted access to everything else. Good architecture assumes faults will happen and contains them.
A simple mental model helps:
- Front end asks only for what it needs
- APIs authorise every request
- Services get scoped permissions
- Developers avoid broad access by default
Defence in depth keeps delivery resilient
No single control is enough. Input validation helps, but it won't save a bad permission model. Authentication matters, but it won't fix secrets management. Automated scanning helps, but it won't replace good design.
That's why resilient teams layer controls instead of betting on one hero mechanism.
Build your platform like a modern office building. Reception matters, but so do locked floors, access cards, cameras, alarms, and clear evacuation routes.
Unbreakable software isn't literally unbreakable. It's software designed so that one mistake doesn't turn into systemic failure. That mindset changes how teams code, review, test, and support products over time.
Prioritised Practices for SaaS and Legacy Systems
Teams often don't need more security advice. They need a sharper order of execution.
Start with the practices that cut the most risk and the most delivery friction. The priority is slightly different for a greenfield SaaS product than for a legacy estate, but the core rule stays the same. Fix what reduces exposure and increases release confidence fastest.
Start with the non-negotiables
Expert guidance in the UK context points to a practical baseline: input validation using allowlists, MFA for authentication, effective error handling with generic messages, peer code review in the deployment pipeline, and logical isolation of secrets from the codebase, as outlined in this secure coding best practices explainer.
That set is strong because it covers both exploit prevention and delivery hygiene.
What not to do
// Anti-pattern
app.post('/login', async (req, res) => {
const user = await db.findUser(req.body.username);
if (!user || user.password !== req.body.password) {
return res.status(401).send(`Invalid password for ${req.body.username}`);
}
res.send(user);
});
This code trusts raw input, exposes too much in the response, and suggests weak authentication handling.
The Rite Way
// Better pattern
app.post('/login', async (req, res) => {
const username = validateUsername(req.body.username); // allowlist pattern
const password = validatePasswordFormat(req.body.password);
const user = await authService.findUser(username);
const authorised = await authService.verifyPassword(user, password);
if (!authorised) {
return res.status(401).send('Invalid credentials');
}
return res.status(200).send({ status: 'MFA required' });
});
The better pattern validates input, avoids leaking internal detail, and assumes a stronger authentication journey.
Prioritised secure coding practices
| Priority | Practice | Impact Area | SaaS/Legacy Focus |
|---|---|---|---|
| 1 | Input validation with allowlists | Attack prevention at entry points | Both |
| 2 | MFA for sensitive access paths | Account protection | SaaS first, then legacy admin paths |
| 3 | Generic error handling | Information leakage reduction | Both |
| 4 | Peer code review in pipeline | Release quality and change control | Both |
| 5 | Secrets isolated from codebase | Credential protection | Both |
| 6 | Server-side authorisation checks | Access control | Legacy first if permissions are inconsistent |
SaaS teams should optimise for repeatability
In greenfield or modern SaaS environments, build these controls into templates, shared libraries, and CI rules. Don't rely on every squad rediscovering the same good habits.
A disciplined review workflow matters here. If your engineering organisation is tightening merge quality, these code review processes are a good reference point for building reviews that improve speed and safety instead of becoming ceremonial.
Legacy teams should target blast radius
Legacy systems need a different instinct. Don't try to redesign the whole estate first. Wrap the riskiest edges.
Focus on:
- Authentication choke points where older access patterns need strengthening
- Input-heavy endpoints that accept external data and deserve immediate validation
- Verbose error paths that leak implementation details
- Embedded credentials buried in scripts, config files, or old deployment routines
Practical rule: if you can't modernise the whole system this quarter, reduce what an attacker can learn, reach, or reuse.
That approach keeps momentum intact. It also gives leadership a clearer path from remediation to modernisation, instead of lumping everything into one impossible transformation programme.
Integrate Security into Your SDLC The Rite Way
Teams get the best results when secure coding practices stop being a side policy and become part of how work moves. That means planning, coding, review, testing, release, and maintenance all carry security responsibilities that are visible and owned.
The operating model should feel boring in the best possible way. Developers know what checks run. Reviewers know what they must verify. Pipeline rules are predictable. Ownership is explicit. Escalation paths are clear.
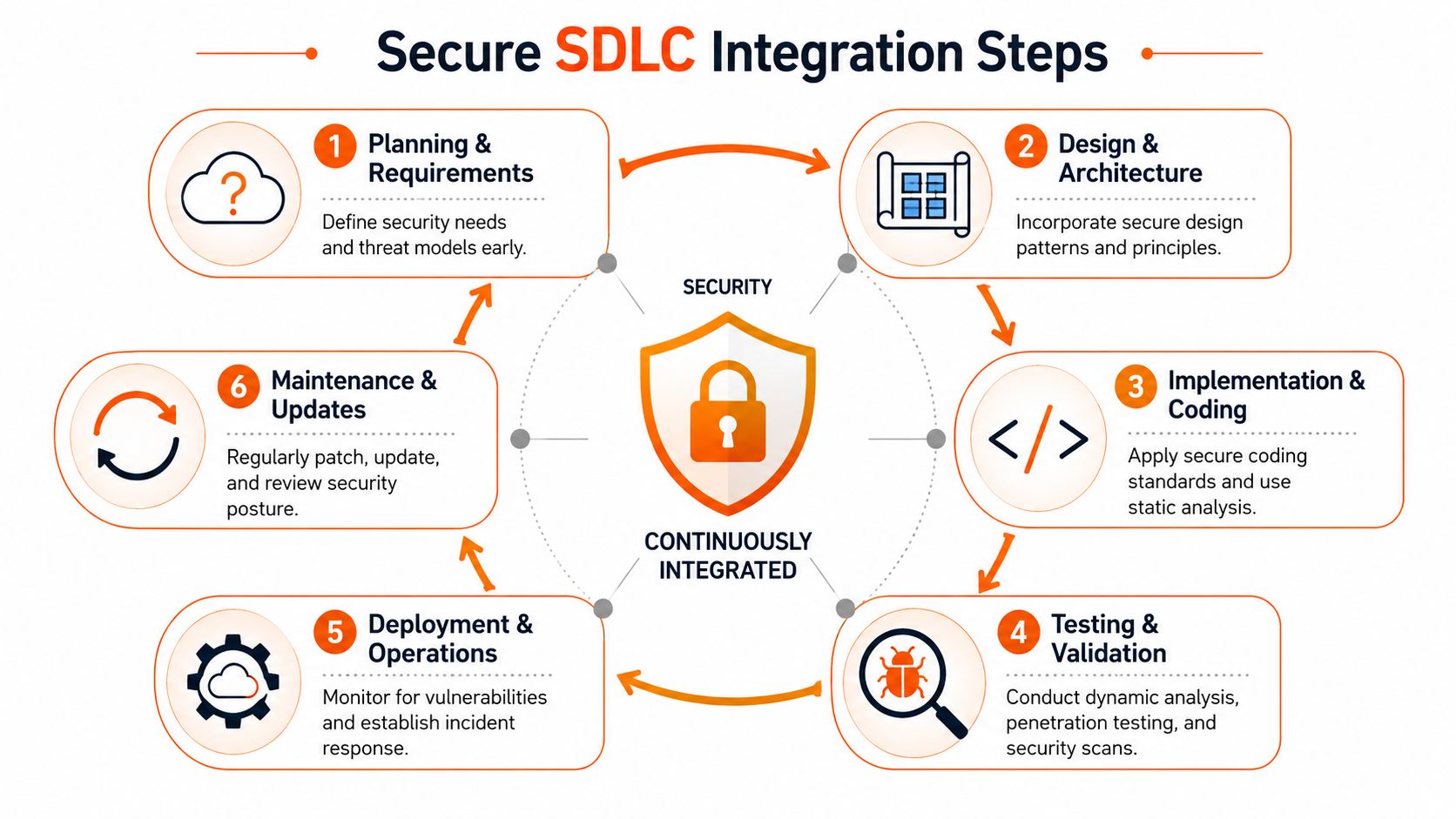
Build a paved road, not a policy deck
A secure SDLC works when the safest route is also the easiest route. That means:
- Planning includes threat-aware requirements. Teams define sensitive data flows, critical permissions, and dependency expectations before implementation starts.
- Design reviews challenge unsafe defaults. Architects and leads check whether services, roles, and integrations are scoped sensibly.
- Implementation includes automated checks. SAST, DAST, secret scanning, and dependency monitoring run in the pipeline, not as occasional side quests.
- Code review enforces judgement. Humans focus on logic, access control, and risky assumptions.
- Deployment blocks unsafe changes. The pipeline should stop insecure changes before customers ever see them.
- Maintenance keeps ownership alive. Patching, support planning, and dependency remediation continue after release.
To make static analysis decisions practical rather than ideological, this review of comparing static code analysis options is useful for teams choosing tools that fit their stack and delivery tempo.
A broader operating view also helps. This perspective on security in the software development life cycle is worth reading if you're aligning engineering, product, and leadership around one delivery model.
Here's a useful walkthrough to support that shift:
Extreme Ownership needs mechanisms
Culture alone won't fix remediation speed. Ownership has to be encoded in workflow.
UK guidance recommends linking code ownership to vulnerability alerts through tools such as GitHub's CODEOWNERS, which can automatically notify responsible developers when a new CVE affects a dependency they introduced. That creates faster remediation and clearer accountability, as explained in this piece on CODEOWNERS and vulnerability ownership.
That's exactly how Extreme Ownership should work in practice. Not as a slogan. As a routing system.
What a mature workflow looks like
A high-performing secure SDLC usually has these traits:
- Ownership is mapped to services, repositories, and dependencies.
- Security checks are automated before merge and before release.
- Review standards are written down so quality doesn't depend on mood or memory.
- Exceptions are logged with named approvers and a remediation deadline.
- Support windows are planned so maintenance isn't improvised.
If a vulnerability alert appears and your team still has to ask who owns the service, your SDLC isn't integrated yet.
The fastest teams aren't the ones with the fewest controls. They're the ones with the clearest defaults.
Measure What Matters Governance and Continuous Improvement
Security programmes stall when leaders track activity instead of outcomes. Counting scans, meetings, or policy documents won't tell you whether your software is becoming safer or your delivery is becoming steadier.
You need a small set of metrics that show whether the team is finding issues early, fixing them quickly, and preventing the same patterns from recurring.

Track speed, ownership, and carry-over risk
The UK's NCSC guidance stresses automating security testing because it creates scalable, repeatable controls and can reduce time to fix vulnerabilities by 35%, according to the NCSC developers collection. The same guidance also calls for tracking security debt in a register from identification through mitigation.
That combination matters. Automation increases consistency. A security debt register stops known issues from disappearing into backlog fog.
The metrics I'd put in front of leadership are these:
- Time to detect whether problems are being found early enough in the lifecycle
- Time to remediate whether ownership and workflow are effective
- Security debt ageing whether known issues are lingering too long
- Escaped vulnerability themes whether the same classes of mistakes keep reaching later stages
Governance should remove ambiguity
Governance works best when it's lightweight and decisive.
Use a simple rhythm:
| Governance element | What leadership should ask |
|---|---|
| Security debt register | Which high-risk items are still open, who owns them, and what's blocking closure? |
| Release readiness review | Are any accepted risks time-bound and documented? |
| Trend review | Are recurring issue types dropping or repeating? |
| Ownership audit | Does every critical service and dependency have a named owner? |
If your team is formalising that discipline, an information technology security audit can help frame how evidence, controls, and accountability should hang together.
Good governance doesn't create blame. It creates visibility, decision speed, and fewer unpleasant surprises.
Use metrics to improve behaviour
Don't weaponise dashboards. If teams think every metric will be used against them, they'll hide risk instead of surfacing it.
Use metrics to ask better questions:
- Are we preventing more issues before review?
- Are fixes stalling in one team, one service, or one approval layer?
- Are accepted exceptions still justified?
- Are we carrying security debt because priorities are unclear, or because ownership is weak?
That's how continuous improvement becomes real. Teams learn faster when the numbers drive action, not theatre.
Your Action Plan for Predictable Secure Delivery
If you want faster delivery, start treating secure coding practices as part of throughput. Not compliance theatre. Not a side concern for the security team. Core delivery discipline.
The teams that execute well do three things consistently. They align security with business outcomes, they assign unmistakable ownership, and they integrate checks into normal workflows so the right behaviour happens by default. That's the logic behind the #riteway methodology. High energy, clear accountability, and proactive execution beat reactive clean-up every time.
Your next move doesn't need to be complicated. It needs to be structured.
The practical starting point
Take these actions this month:
- Map ownership clearly for repositories, services, and dependencies.
- Set a minimum secure coding baseline for validation, authentication, error handling, review, and secrets management.
- Automate the checks that should never rely on memory.
- Create a security debt register and review it with the same seriousness as product delivery risk.
- Tie support and maintenance planning to real lifecycle commitments so old versions don't become silent liabilities.
Secure delivery becomes predictable when the organisation stops relying on heroics. That's the shift. Fewer surprises, cleaner releases, stronger customer trust, and more capacity for the roadmap that drives growth.
If you want help turning secure coding into a repeatable delivery system, Rite NRG works with SaaS teams to build predictable, senior-led engineering execution around ownership, speed, and product outcomes. Download The Secure Delivery Checklist, use it to pressure-test your current workflow, and if the gaps are bigger than they should be, start a conversation.

