


Your product is getting traction. Sales calls are going well, pilot customers want more, and your roadmap looks exciting on paper. Then the platform starts fighting back. Releases slow down, one customer's heavy usage affects everyone else, onboarding a new tenant feels manual, and enterprise prospects ask security questions your current setup can't answer with confidence.
That's the moment when SaaS platform architecture stops being a technical topic and becomes a business one. If your architecture makes every new feature harder to ship, you won't just frustrate engineers. You'll delay revenue, increase churn risk, and weaken your position in every investor and customer conversation.
Why Your SaaS Platform Architecture Defines Your Success
A strong SaaS platform architecture gives you an advantage. A weak one creates drag in every department.
Founders often treat architecture as something to “clean up later”. That's backwards. The right architecture is what lets you move quickly now without paying for every shortcut twice. It's the operating system for your pricing model, onboarding flow, support quality, security posture, and gross margin.
Architecture changes business outcomes
The numbers are clear. Organisations have achieved a 40% reduction in IT maintenance costs and a 30% faster time-to-market by using scalable architectures, and a UK-based platform that optimised its data architecture saw a 22% increase in customer lifetime value and a 15% drop in churn within 18 months (platform architecture outcomes in practice).
That's the frame I'd use in every boardroom conversation. Architecture isn't about elegant diagrams. It's about lowering maintenance effort, increasing release speed, and protecting retention.
If your current platform makes every delivery cycle noisy, fragile, or slow, you don't have an engineering problem alone. You have a growth problem.
The #riteway mindset changes how teams build
The best teams don't hide behind tickets, estimates, or hand-offs. They take Extreme Ownership. They surface risk early, make trade-offs explicit, and connect technical decisions to outcomes the business cares about.
That's what I mean by the #riteway. High energy. Proactivity. No passive delivery. No “we built what was asked” excuses when the result doesn't move the business forward.
Practical rule: If an architectural decision can't be explained in terms of speed, margin, retention, security, or expansion revenue, it probably isn't the right priority.
A consulting mindset matters here. You don't need a team that only ships code. You need people who can tell you when your tenancy model will hurt onboarding, when your auth design will block enterprise sales, and when your deployment flow will become the bottleneck. That's why a sound software architecture design approach matters early, not after the platform starts creaking.
What good looks like
A winning SaaS architecture does four things well:
- Supports growth: New tenants, new features, and new integrations don't break the system.
- Protects customer trust: Security, resilience, and visibility are designed in.
- Keeps delivery fast: Teams can release small changes without risky all-or-nothing deployments.
- Improves unit economics: Infrastructure and support effort stay under control as the customer base grows.
That's the standard. Anything less becomes expensive fast.
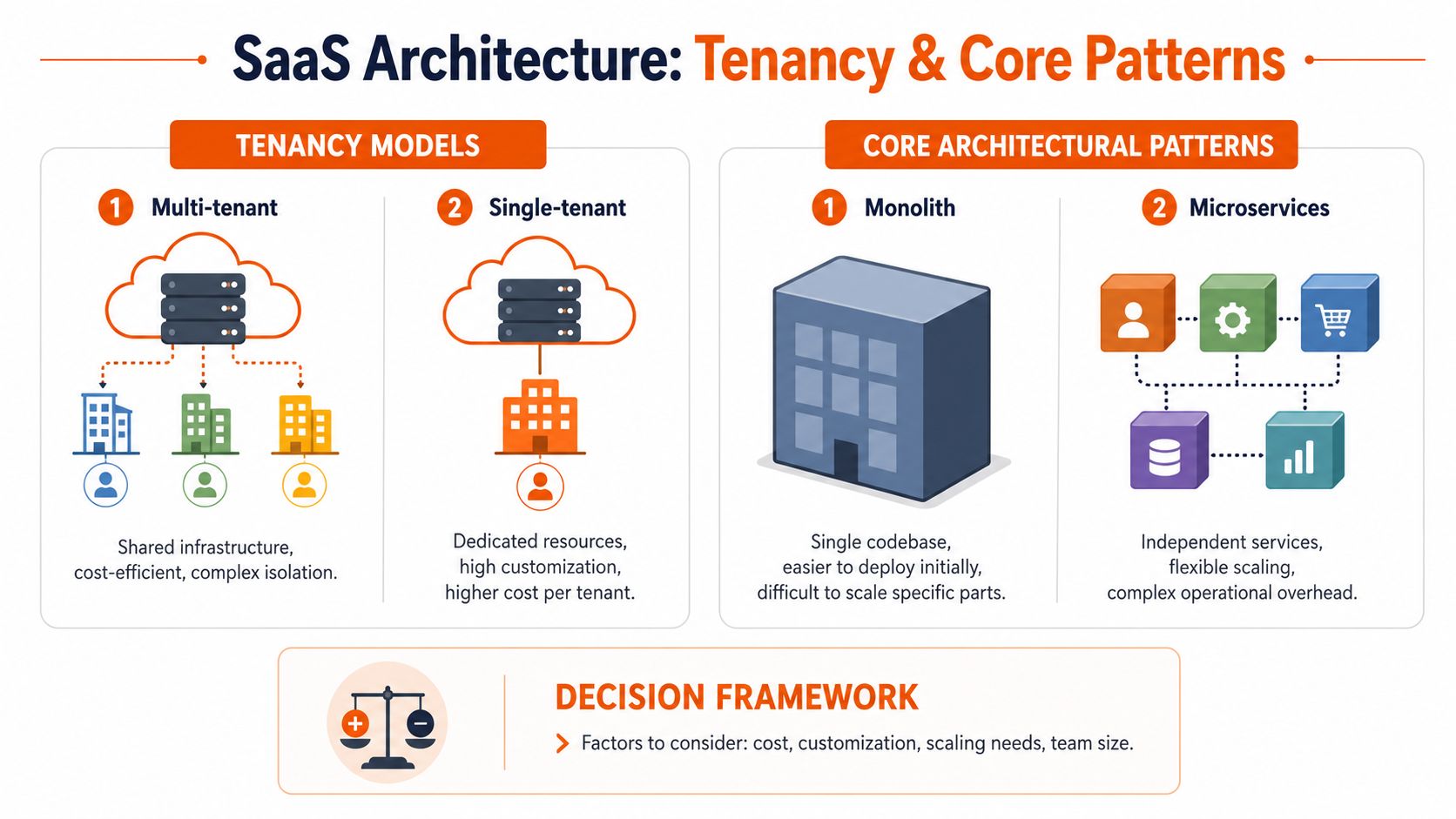
The First Big Decisions Tenancy and Core Patterns
Before you choose frameworks, clouds, or deployment tools, make two decisions properly. First, how tenants will be isolated. Second, how services will be structured.
Get these wrong and you'll spend months undoing early assumptions.
Tenancy is a business model decision
More than 70 percent of businesses now use cloud-based software, and the multi-tenant model has emerged as the definitive principle for reducing infrastructure costs. Typical SaaS architecture also sits across three layers: application, database, and infrastructure. At the same time, approximately 6 percent of SaaS products still fail due to technical limitations, which is exactly why these early architectural choices matter (SaaS architecture market context).
Single-tenant and multi-tenant aren't abstract labels. They shape cost, support, compliance posture, and customer segmentation.
| Model | Best fit | Strength | Trade-off |
|---|---|---|---|
| Multi-tenant | Most B2B SaaS products | Lower infrastructure cost and easier standardisation | Harder isolation and operational design |
| Single-tenant | High-compliance or highly customised offers | Stronger separation and customer-specific control | Higher cost per customer and more operational overhead |
A simple rule helps.
- Choose multi-tenant if your product targets repeatable workflows, standard pricing, and broad market scale.
- Choose single-tenant if your core commercial value depends on hard isolation, deep customer-specific configuration, or unusual compliance requirements.
- Choose a hybrid path if you expect standard customers first and enterprise demands later.
If you're weighing that choice in detail, this guide to multi-tenancy in cloud computing is worth reviewing.
Shared infrastructure can be a competitive advantage. Only if you design isolation, access control, and operational visibility as first-class concerns.
Modular monolith versus microservices
This debate wastes too much time because teams treat it like ideology. It's a sequencing decision.
A modular monolith is one deployable codebase with clear internal boundaries. A microservices setup splits those boundaries into independently deployable services.
Here's the blunt advice.
Start simpler than your ego wants
A modular monolith is often the right starting point when:
- Your product is still finding shape: features are changing weekly.
- Your team is small: coordination overhead will hurt more than service separation helps.
- Your domain isn't stable yet: boundaries drawn too early are usually wrong.
It gives you speed, lower operational complexity, and fewer moving parts to monitor. That's valuable during early learning.
Split when the business needs it
Move toward microservices when:
- one domain needs to scale independently
- deployments are blocked by coupling between teams
- failures in one area affect unrelated user journeys
- compliance or security boundaries need tighter control
Microservices can be the right move, but only when they solve a real business constraint. If your billing service, analytics pipeline, and user management need separate release cycles, separate scaling behaviour, or separate operational ownership, then split them. If not, don't create distributed systems pain for sport.
The decision criteria founders should actually use
Don't ask, “What architecture do modern SaaS companies use?” Ask better questions:
- What are we selling in the next 18 months?
- Which customers need isolation or customisation?
- Where will usage spikes happen first?
- How many teams will ship into this platform?
- Which failure would hurt revenue most?
Answer those truthfully and the right pattern usually becomes obvious.
Building Your Core Architectural Components for Scale
Once the foundational decisions are made, the next step is to design the core components that will carry the product through launch and beyond. At this stage, many teams make expensive mistakes. They build only for the first demo, not for the first serious customer.
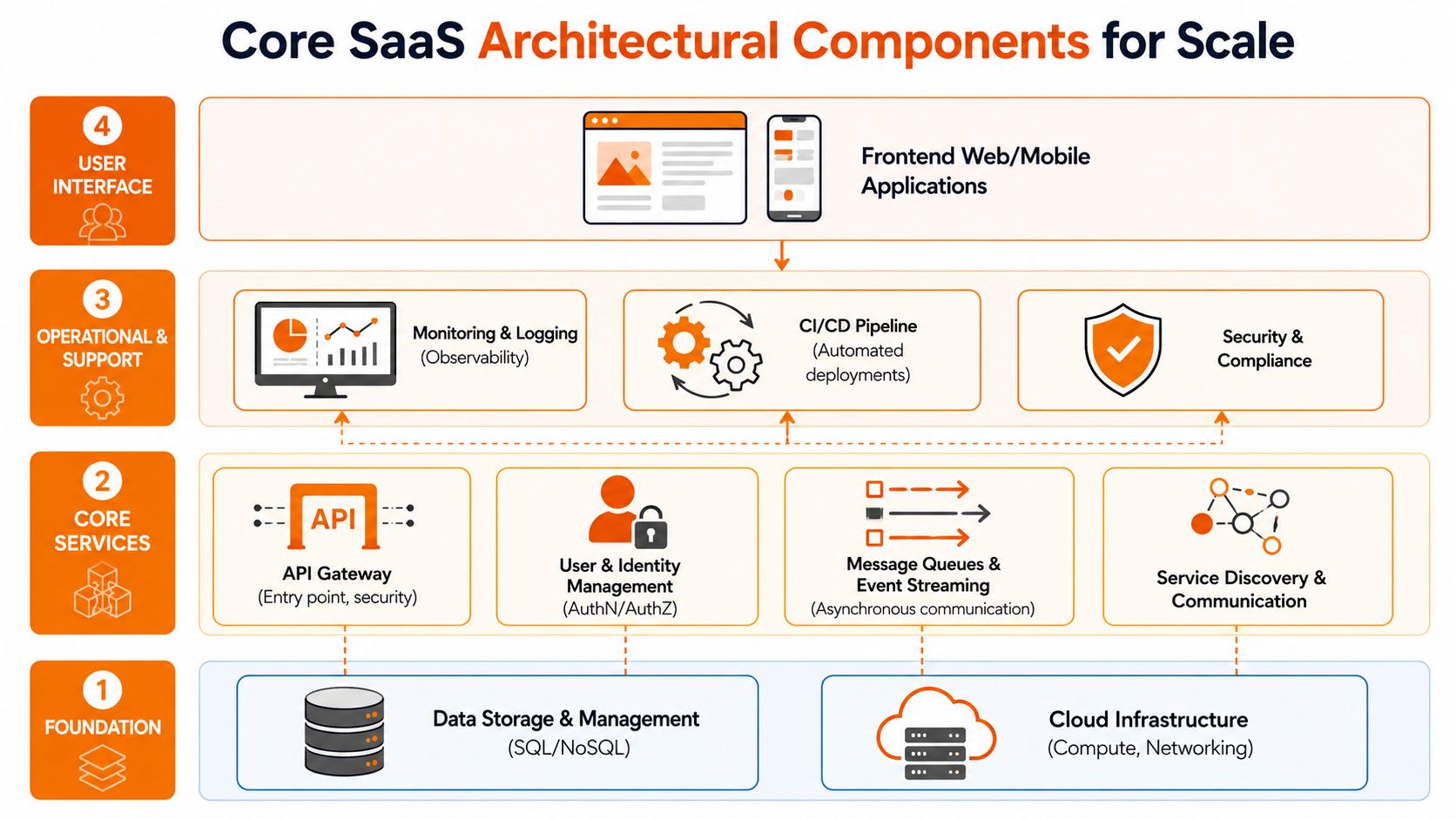
Build the front door properly
Your API layer is your product's front door. Treat it that way.
A good API layer should enforce consistent authentication, validation, rate control, and versioning. It should also make it easy to add clients later, whether that's a web app, mobile app, partner integration, or internal admin tool. Teams that skip discipline here usually end up with duplicated logic spread across services and frontends.
Use clear domain boundaries. Don't let “temporary” endpoints become permanent architecture.
Design data for retrieval, not just storage
Most early SaaS products model data around what's easy to save. Smart teams model data around what users, support staff, and internal operators need to retrieve quickly.
Think in terms of:
- Operational data: the records powering day-to-day product workflows
- Analytical data: reporting, product insight, and customer behaviour
- Tenant context: ownership, permissions, and isolation rules attached to every meaningful object
If you don't design for tenant context early, future reporting, debugging, billing, and access control become painful.
A useful test: Can your support team answer “what happened for this customer?” without asking engineering to inspect logs manually?
Auth and billing deserve more respect
Authentication and authorisation are often treated as boilerplate. That's a mistake. Your auth model shapes security, enterprise readiness, admin workflows, and future SSO support. Keep identity, roles, and permissions explicit. Avoid scattering access rules through controllers and UI code.
Billing is similar. Even if your first release only has a simple subscription, architect the billing layer so plans, entitlements, trials, limits, and invoicing logic can evolve. Stripe, Chargebee, or Paddle can help with payment workflows, but you still need a clean internal entitlement model.
A practical build sequence looks like this:
- Start with identity: login, session management, role separation, and audit-friendly access rules.
- Then stabilise the data model: core entities, tenant ownership, lifecycle states, and migration discipline.
- After that, formalise billing and entitlement logic: what the customer bought, what they can access, and what happens when usage or plans change.
- Finally, harden asynchronous flows: queues, retries, and background workers for email, imports, exports, notifications, and reporting.
For teams building cloud-heavy systems, recruiting top cloud infrastructure talent can make the difference between a clean platform foundation and months of avoidable rework.
A short explainer helps frame the component stack in practical terms:
Don't bolt on operability later
Include logging, deployment automation, environment management, and configuration controls from the start. They aren't “platform extras”. They're what let your team release often without introducing chaos.
A scalable SaaS platform architecture isn't just user-facing software. It's the operational machinery behind the software.
Architecting for Resilience Security and Observability
A prospect is in a late-stage sales call. They ask three questions. How do you protect our data? What happens if a service fails? How fast will you know before our team notices? If your architecture cannot answer those clearly, you do not have an enterprise-ready SaaS platform. You have a product with revenue risk.
Resilience, security, and observability are not backend hygiene tasks. They shape deal velocity, renewal confidence, support costs, and your ability to ship without creating operational drag. They also shape delivery. Teams that design these controls early avoid expensive rewrites later, which matters even more if you are building fast with an AI-enabled nearshore team and need clear standards that keep quality high across every sprint.
Security starts with identity
Founders often spend too much time debating perimeter controls and too little time defining who can access what, under which conditions, and how that access is reviewed. That is backwards.
Start with centralised identity and access management. Put SSO, MFA, role-based access, session controls, and audit trails at the centre of the platform. Then make every service respect that model. AWS security guidance for SaaS teams recommends building strong tenant isolation, least-privilege access, and traceable identity controls into the platform from the start, not layering them on after customers ask for security questionnaires (AWS SaaS Lens security design principles).
The business case is simple. Strong identity architecture shortens security reviews, reduces support tickets around permissions, and gives larger customers fewer reasons to stall procurement.
Resilience is a revenue protection system
Outages rarely stay contained on their own. A slow dependency backs up a queue. Retries surge. Workers compete for resources. Login slows down. Billing jobs miss their window. Your team ends up fighting symptoms instead of fixing the fault line.
Design clear failure boundaries early.
| Priority | What to implement | Why it matters |
|---|---|---|
| Isolation | Separate critical workflows and limit blast radius between services, jobs, and tenants | A failure in one area should not take down onboarding, billing, or login |
| Recovery | Idempotency, retries with limits, dead-letter queues, backups, and tested restore paths | Temporary faults stay temporary, and incidents end faster |
| Elasticity | Autoscaling, load balancing, rate limiting, and capacity guardrails | Spikes in traffic or abusive usage do not become platform-wide outages |
Treat partial failure as normal operating reality. A dependency will slow down. A deployment will go wrong. One tenant will generate unusual load. Good SaaS architecture contains the problem, preserves the core customer journey, and gives your team room to recover without turning every incident into a company-wide fire drill.
Observability must be tenant-aware
Generic dashboards are not enough for a multi-tenant product. Aggregate latency and error charts tell you something is wrong. They do not tell you which tenant is affected, which workflow is failing, or whether the issue threatens churn, SLA exposure, or expansion revenue.
AWS calls out tenant-aware operational visibility as a core SaaS design principle because operators need to understand activity and performance at the tenant level, not only at the system level (AWS SaaS Lens general design principles).
That is the difference between infrastructure monitoring and business-aware operations.
If your team needs a stronger operating model, this guide to tenant-aware monitoring and observability practices is worth reading.
What to instrument first
Instrument the signals that change decisions, not vanity charts.
- Per-tenant traffic and latency: identify noisy tenants, degraded customer experience, and emerging capacity hotspots
- Authentication and access events: failed logins, privilege changes, suspicious access patterns, and admin actions
- Asynchronous workflows: queue depth, processing lag, retry spikes, dead-letter volume, and stuck jobs
- Revenue-critical journeys: signup, onboarding milestones, payment events, provisioning, and core feature completion
- Recovery indicators: backup status, restore test results, deployment health, and incident response timings
Architecture delivers returns to the business. Your team can spot risk earlier, support high-value customers with facts instead of guesses, and make better roadmap decisions because the platform tells you where reliability work protects revenue fastest.
Build these capabilities into delivery, not after delivery. With an AI-enabled nearshore model, that means defining security controls, resilience patterns, and observability standards as part of the build system itself. Clear runbooks, shared telemetry conventions, and automated checks let distributed teams move quickly without lowering the bar. That is how you get speed and control at the same time.
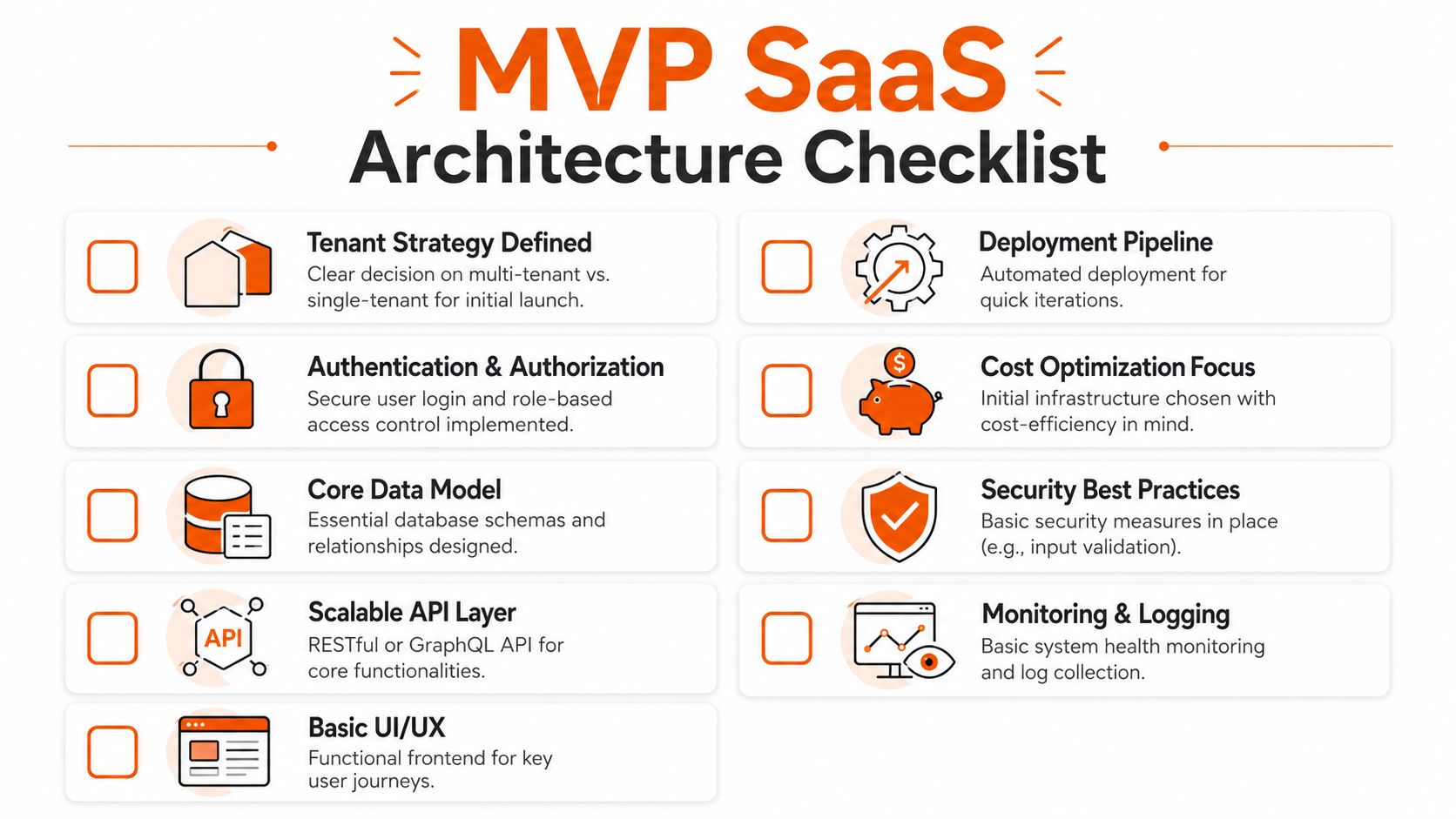
The Actionable MVP Architecture Checklist
An MVP doesn't mean “throw something together”. It means building the smallest version of the platform that can win trust, prove demand, and support fast iteration without collapsing under the first wave of real users.
That requires discipline.
What founders should lock in before build starts
In the UK market for 2026, an AI-assisted MVP architecture is projected to take 10 to 14 weeks and cost £35,000 to £65,000. A mid-range platform with billing is projected at £70,000 to £130,000 over 4 to 7 months, while enterprise-grade systems with multi-tenancy and compliance are projected to take 8 to 14 months and cost £140,000 to £300,000+. The same projection identifies tenancy and compliance as key cost drivers (UK SaaS development cost projections for 2026).
That should reset expectations. If your MVP includes complex tenancy, billing logic, auditability, and enterprise-style controls, it's not a cheap prototype. It's an early platform investment.
The checklist that actually matters
Use this as a decision filter before work begins:
- Tenant strategy is explicit: You've chosen multi-tenant, single-tenant, or a phased hybrid path.
- Identity is not deferred: Core login, role handling, and access control are part of the first build.
- Data model supports ownership: Every critical object has a clear tenant and user relationship.
- API boundaries are defined: Core workflows have stable contracts instead of ad hoc endpoints.
- Deployment is automated: Even a basic CI/CD pipeline beats manual release rituals.
- Monitoring exists from day one: Errors, logs, and health checks are available before the first customer issue.
- Billing assumptions are documented: Even if payment is simple, entitlement logic is clear.
- Security basics are built in: Validation, secrets handling, and least-privilege access aren't optional.
- Commercial scope is constrained: You know which user journeys must work flawlessly at launch.
What to cut and what to keep
Founders usually try to cram too much into the first version. Don't.
Keep the workflows that prove customer value. Keep the controls that protect trust. Keep the architecture choices that preserve future speed.
Cut the nice-to-have integrations. Cut speculative flexibility. Cut edge-case admin tooling unless it directly affects launch readiness.
Your MVP should be narrow in features and serious in architecture.
That's how you avoid the classic trap. Shipping fast, then discovering the first ten customers exposed design flaws that force a rewrite.
Accelerating Delivery with Nearshore Teams and AI
It's Monday morning. A prospect wants a security review by Friday, a trial customer found a billing edge case over the weekend, and your product roadmap is already slipping because two hires are still stuck in interview loops.
That is not a staffing problem alone. It is a delivery model problem.
Good SaaS architecture creates options. The right delivery setup turns those options into shipped product, faster revenue, and fewer expensive delays. Founders who treat delivery as an afterthought usually pay for it in slower releases, unclear ownership, and technical decisions that drift away from business priorities.
Nearshore teams speed you up only when they own outcomes
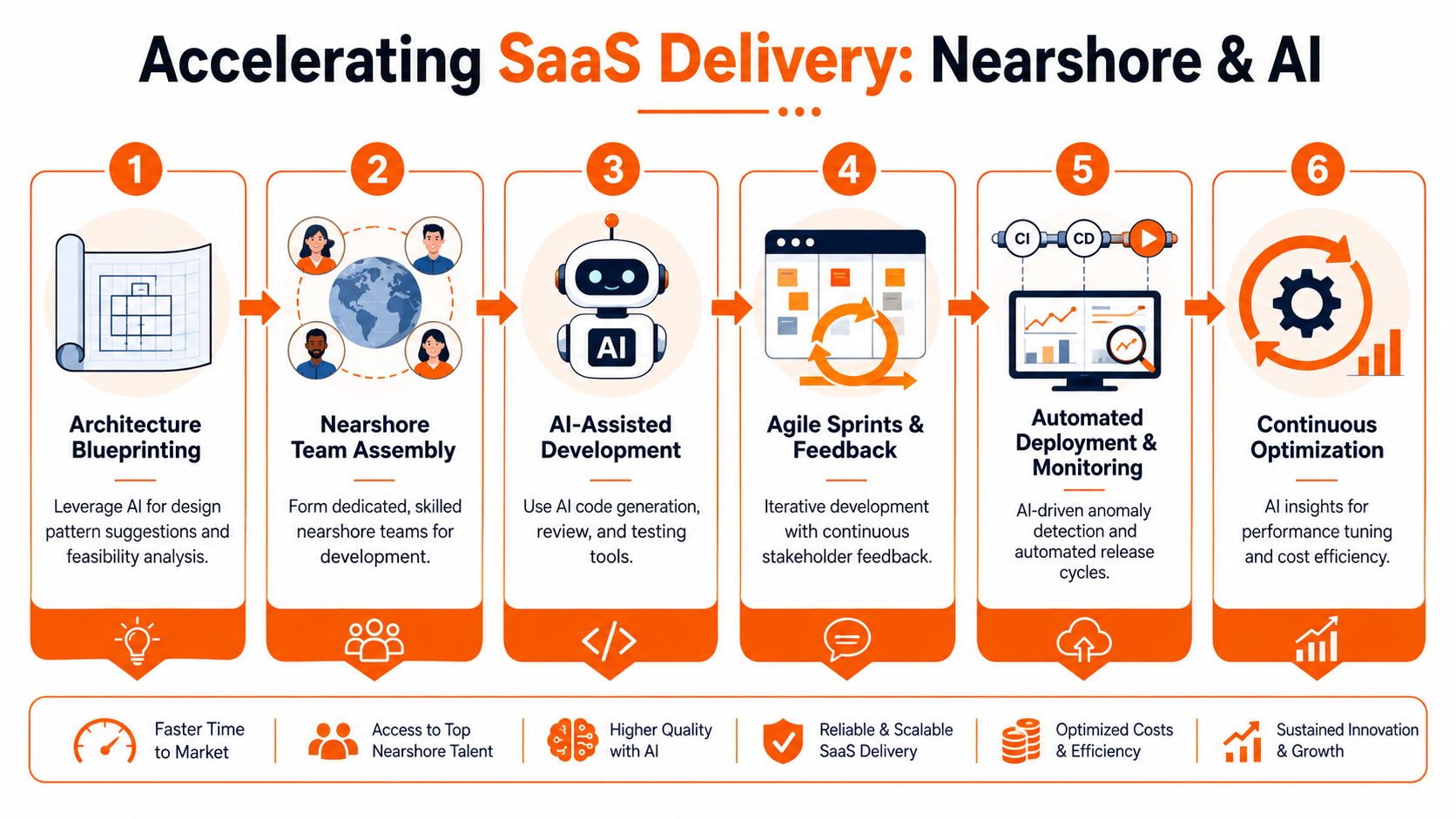
Nearshore delivery works best when the team is close enough in time zone to make decisions daily, senior enough to challenge weak requirements, and accountable enough to own results instead of shipping tickets.
Treat a nearshore team as a cheap extension bench and you will get more activity, not more progress. Use one as a true product and engineering partner and you cut hiring drag, reduce decision latency, and keep momentum when the market will not wait.
Set it up this way:
- Use senior builders from day one: early SaaS work needs judgement, not extra hands.
- Give direct access to founders or product owners: strategy gets lost when every decision passes through three layers.
- Measure outcomes, not output: release quality, cycle time, onboarding speed, and commercial impact matter more than story points.
- Build shared operating habits: one backlog, one set of rituals, one definition of done.
- Require documentation and transferability: your platform cannot depend on private Slack threads and memory.
If you're comparing models, LatHire's guide to nearshore teams gives a practical view of the trade-offs.
AI should compress cycle time
AI belongs in delivery because it removes drag. It should help your team make better decisions faster, catch obvious mistakes sooner, and spend more time on architecture, product logic, and customer impact.
Used properly, AI improves work across the stack:
| Delivery area | Where AI helps | Why it matters |
|---|---|---|
| Discovery | Requirement clarification, solution comparison, dependency mapping | Less ambiguity before engineering starts |
| Engineering | Code assistance, review support, test generation, refactoring suggestions | Faster implementation with fewer routine bottlenecks |
| Operations | Release checks, anomaly detection, incident triage support | Teams spot issues earlier and recover faster |
| Hiring and onboarding | Candidate screening support, knowledge retrieval, documentation summarisation | New team members become useful sooner |
AI does not replace architecture judgement. It increases the output of engineers who already know what good looks like.
That distinction matters. A weak team with AI still makes weak decisions faster. A strong team with AI shortens feedback loops across delivery.
Why this model fits SaaS companies that need speed without chaos
Modern SaaS products rarely fail because code could not be written. They fail because decisions pile up, releases wait on the wrong people, and every change touches too much of the system.
A nearshore team with senior engineers and AI support helps fix that operationally. Work can move in parallel. Reviews happen faster. Documentation gets produced instead of postponed. Testing starts earlier. Risks surface before they become launch blockers.
This is especially useful when different parts of the platform move at different commercial speeds. Billing changes, onboarding improvements, integrations, and admin tooling should not all sit behind one overloaded release path. If your architecture supports separation and your delivery model supports ownership, you get faster iteration where the business needs it most.
That is the point. Better delivery is not about velocity in the abstract. It is about reaching customers sooner, learning sooner, and protecting focus while the product grows.
How I'd structure delivery in practice
For a founder building or modernising a SaaS platform, I'd use a model like this:
Start with a clear architecture brief
Define the business priorities behind the platform first. Revenue model, tenant model, compliance needs, service boundaries, and the first customer journeys must be clear before development scales.Keep the initial team small and senior
A delivery lead, strong product direction, and a handful of experienced engineers will outperform a larger mixed-seniority team in the early stages.Bake AI into the workflow, not as a side experiment
Use it in discovery, coding, testing, release checks, and knowledge sharing. Make it part of how the team works every week.Run short decision cycles with business visibility
Founders should see scope trade-offs, delivery risk, and release impact in real time. Weekly course correction beats late-stage surprise.Design for continuity from the start
Whether you keep the nearshore team, blend it with in-house hires, or transition ownership later, the codebase, tooling, and documentation should support a clean handoff.
The best delivery model does more than ship features. It helps the business make decisions faster.
That matters even more in modernisation and vendor transition work. An incoming team must absorb context quickly, stabilise what exists, and improve the platform without pausing the roadmap. That is where an AI-enabled nearshore model stands out. You get execution capacity, architectural judgement, and faster learning loops at the same time.
Your Architecture Is Your Business Strategy
Your SaaS platform architecture is a commercial decision in technical form.
Choose the wrong tenancy model and your margins suffer. Choose the wrong service boundaries and delivery slows down. Neglect identity, resilience, or observability and customer trust becomes fragile. Rush the MVP without architectural discipline and every future sprint gets harder.
The upside works the same way. Strong architecture creates speed. It supports better onboarding, cleaner releases, stronger security answers in enterprise sales, and a platform your team can improve without fear. That's what founders should optimise for.
The teams that win don't separate technology from outcomes. They connect every architectural choice to value delivery. Faster launches. Lower maintenance burden. Better retention. More predictable scaling.
That's the spirit of Extreme Ownership. Don't outsource responsibility for the result. Build with people who think beyond implementation, act early, and stay accountable for what the platform delivers to the business.
A winning SaaS platform doesn't happen by accident. It's designed that way.
If you want a partner that combines senior SaaS engineering, consulting-level delivery guidance, and AI-powered nearshore execution, Rite NRG helps founders and product teams build scalable platforms with speed, clarity, and ownership.

