


Your backlog probably looks busy. That doesn't mean it's healthy.
I see the same pattern over and over. A team starts with good intent, captures every idea, every stakeholder request, every bug, every “we should really do this one day” thought, and calls it transparency. Six months later, the backlog is packed, nobody trusts the priorities, sprint planning takes too long, engineers are filling in gaps themselves, and deadlines slip because half the work wasn't ready when it entered delivery.
That's not a tooling issue. It's a leadership issue.
Good backlog management is one of the clearest signals that a company knows how to turn product ambition into predictable business outcomes. Bad backlog management creates a feature graveyard. Work goes in. Value never comes out. Teams stay active, but the business doesn't get momentum.
If you're running distributed teams, nearshore teams, or a mix of product, platform, and AI work, the stakes are even higher. Distance magnifies ambiguity. Weak priorities create delivery drag. Vague tickets become expensive conversations.
The fix is straightforward. Treat the backlog as a strategic control system, not a storage unit. Own it aggressively. Cut ruthlessly. Prepare work early. Prioritise by business outcome. Protect engineering focus like it's a scarce asset, because it is.
Stop Drowning in Features and Start Delivering Value
A chaotic backlog rarely announces itself as chaos.
It usually shows up as a team that's constantly “in motion” but never fully confident. Product says the roadmap is clear. Engineering says the stories aren't. Stakeholders keep adding urgent items. Sprint goals get diluted by bugs, technical debt, and half-defined features. Delivery starts to feel heavy, then political, then unpredictable.
That's when leaders make the wrong diagnosis. They ask for better estimates, tighter deadlines, more ceremonies, more reporting.
None of that fixes the actual problem.
What a feature graveyard looks like
A feature graveyard has a few obvious symptoms:
- Too many items: The backlog keeps growing, but very little gets removed.
- Weak definitions: Stories contain intent, not enough detail to execute.
- Priority theatre: Everything is marked important, so teams make trade-offs on the fly.
- Hidden dependencies: Engineering discovers blockers after work starts.
- No expiry: Old ideas hang around long after the context that created them has disappeared.
The result is predictable. Teams burn time clarifying work mid-sprint. Stakeholders lose trust because output doesn't translate into visible progress. Senior people spend their energy untangling noise instead of driving outcomes.
A backlog should reduce decision load, not create more of it.
Backlog management is a business discipline
If your backlog can't tell the team what matters now, what matters next, and what should be dropped, it isn't serving the business.
Strong backlog management does three things at once. It sharpens focus, protects delivery capacity, and creates a cleaner link between effort and customer value. That's the heart of the #riteway mindset: extreme ownership over the flow of work, not passive administration of tickets.
A healthy backlog gives people confidence. It tells engineers what's ready. It tells stakeholders what won't be done yet. It tells leadership whether the company is investing in the outcomes it says it cares about.
That's how you stop drowning in features. You stop treating the backlog like an archive and start running it like an engine.
From Feature List to Strategic Value Engine
Backlog management isn't admin. It's air traffic control for product delivery.
When it works, every piece of work in motion has a clear reason to exist, a clear place in the queue, and enough definition to move safely into execution. When it doesn't, teams taxi endlessly. Work waits for answers. Priorities collide. Delivery windows get missed because nobody managed the sequence.
This visual captures the shift well:
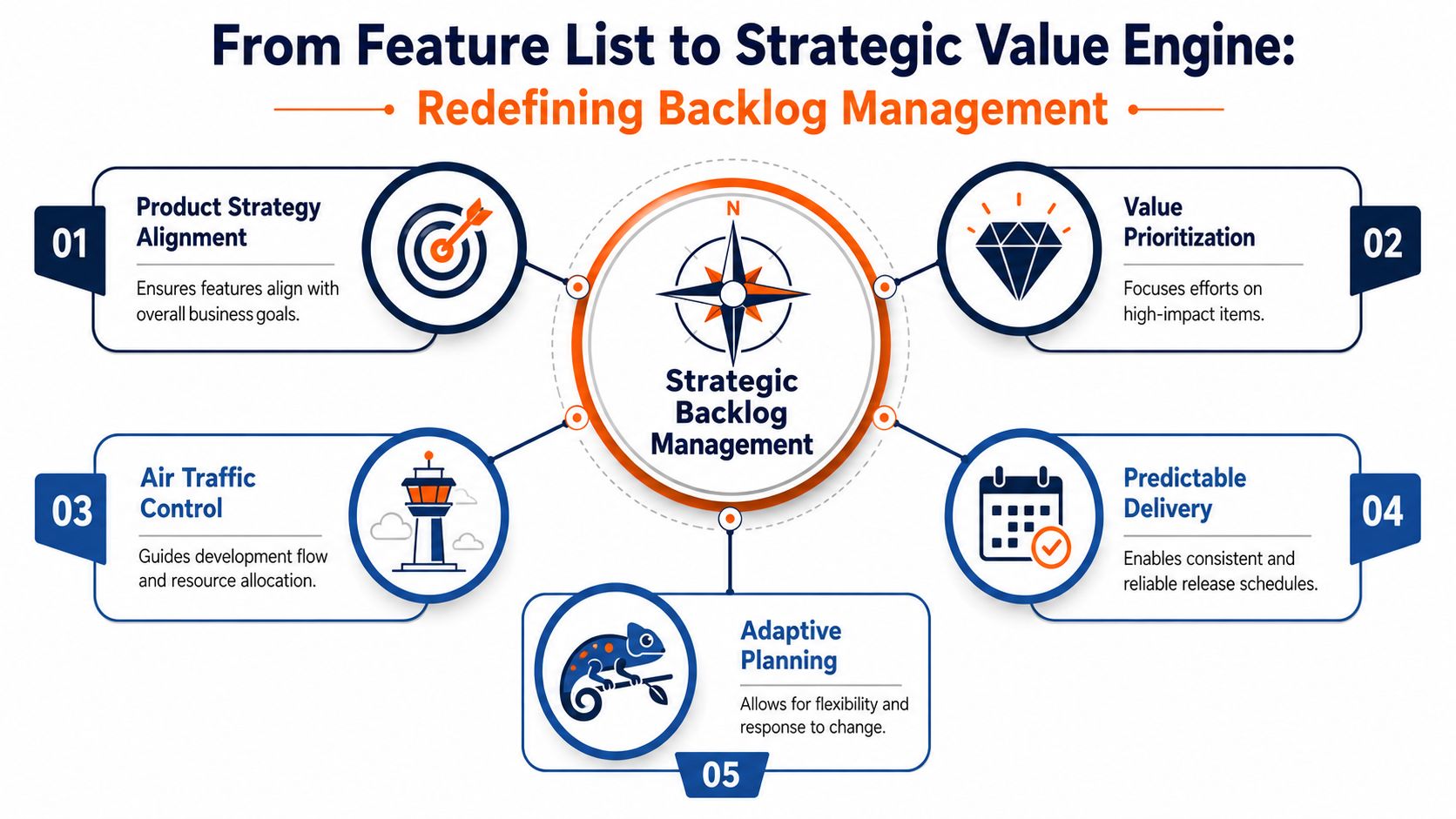
Treat the backlog as the operating layer of strategy
Your roadmap carries intent. Your backlog carries commitment.
That distinction matters. The roadmap says where you're going. The backlog decides what the team spends its finite time on next. If those two aren't aligned, you'll still ship things, but you won't build momentum.
A strategic backlog does four jobs well:
- Translates goals into executable work
- Makes trade-offs visible
- Surfaces delivery risk early
- Keeps the team working on the highest-value ready items
That's why the backlog should be dynamic. Not bloated. Not “complete”. Dynamic.
Decompose earlier or pay later
The fastest way to poison delivery is to drag oversized epics into planning and expect the team to sort it out under time pressure.
UK-oriented backlog guidance recommends breaking epics into stories and discussing them 1–2 sprints in advance, because earlier decomposition reduces ambiguity, improves estimation accuracy, and exposes technical dependencies before they block delivery, especially when teams are balancing features, bugs, and technical debt (Aha backlog guidance).
That advice is practical, not procedural. Teams need time to ask basic questions before a sprint starts. What's the scope? What dependencies exist? What can be cut? What's unknown? Which part delivers value first?
Practical rule: if a team is still discovering core assumptions during sprint planning, the backlog isn't ready.
Build a ready queue, not a vague inventory
You don't need the whole backlog detailed. You need the near-term slice ready for execution.
That means:
- Epics are split: Large ideas become deliverable slices.
- Near-term items are estimated: The team can reason about effort because the work is clear enough.
- Dependencies are named: Integrations, approvals, and architectural constraints are visible.
- Acceptance is understood: People know what “done” means.
A short explainer helps if your stakeholders still think backlog management is just Jira hygiene:
The strongest teams don't just organise work. They shape demand so delivery stays predictable.
Essential Workflows and Roles for Flawless Execution
A strong backlog needs rhythm. Without it, quality collapses between planning sessions.
Most backlog problems aren't caused by a lack of effort. They come from the wrong operating model. One person owns the list, everyone else reacts to it, and refinement becomes a reluctant meeting where people try to rescue unclear work at the last moment.
That model fails because clarity is shared work.
Who owns what
The Product Owner or product manager should own the why. They decide what outcome matters, what problem is worth solving, and what should move first.
Engineering leaders and senior developers own the how enough. Not final implementation detail for every future idea, but enough technical shaping to expose risk, sequence dependencies, and stop the team from walking blind into avoidable complexity.
If your organisation still blurs these accountabilities, this breakdown of product manager vs project manager responsibilities is useful because many backlog failures start with role confusion.
The refinement cadence that actually works
Refinement should feel like preparation, not bureaucracy. Keep it fast, focused, and outcome-led.
A practical cadence looks like this:
- Weekly backlog refinement: Review near-term items, cut unclear work, challenge priority.
- Pre-planning technical check: Confirm dependencies, assumptions, and sequencing.
- Stakeholder decision moments: Resolve trade-offs before sprint commitment, not during it.
- Ongoing cleanup: Archive duplicates, merge overlap, delete stale requests.
That rhythm matters more for distributed teams. If people aren't in the same room, you can't rely on ambient context. The backlog has to carry more clarity.
Definition of Ready is not optional
Teams that want predictable delivery need a real Definition of Ready. Not a ceremonial checklist nobody enforces.
Use simple standards:
- Problem is clear: The team understands the user or business outcome.
- Scope is bounded: The story isn't hiding three separate initiatives.
- Dependencies are visible: External teams, data constraints, and platform work are noted.
- Acceptance is testable: People can verify whether the work is complete.
- Open questions are few: Unknowns exist, but they're explicit and manageable.
If an item needs a long verbal explanation to be understood, it isn't ready.
Extreme ownership beats passive ticket management
The #riteway mindset changes the quality of refinement because nobody says, “That's not my part.”
Product pushes for sharper outcomes. Engineers challenge ambiguity early. Delivery leads protect flow. Stakeholders are forced to choose instead of endlessly adding. That's what extreme ownership looks like in practice. A team taking responsibility for clarity before execution begins.
You don't need more meetings. You need better prepared work and stronger accountability around what enters delivery.
Prioritisation Frameworks That Drive Business Outcomes
Most backlogs don't fail because teams can't come up with ideas. They fail because leaders won't make hard choices.
If everything stays on the list, priority turns into politics. The loudest stakeholder wins. The most recent request jumps the queue. Technical debt gets postponed until it becomes a delivery tax. That's not prioritisation. That's drift.
A good framework forces trade-offs in public.
Three frameworks worth using
Here's a practical comparison:
| Framework | Best For | Key Variables | Primary Benefit |
|---|---|---|---|
| RICE | Feature evaluation in product-led environments | Reach, Impact, Confidence, Effort | Brings structure to competing feature requests |
| WSJF | Sequencing larger initiatives and cross-functional work | Cost of delay, job size | Helps teams choose what to do sooner for economic impact |
| MoSCoW | Stakeholder alignment and scope negotiation | Must, Should, Could, Won't | Creates fast clarity when priorities are contested |
Use RICE when feature demand is noisy
RICE works well when you've got a stack of possible features and need a rational way to compare them.
It's useful because it separates “important sounding” from “worth doing now”. A feature with broad reach and clear impact may outrank a pet request from a single stakeholder, even if that stakeholder has seniority. That's healthy.
RICE is strongest when your product team has enough product insight to discuss likely value with discipline. It's weaker when teams pretend confidence is certainty. Don't game the score. Use it to sharpen judgement.
Use WSJF when sequencing matters more than preference
WSJF is strong when multiple streams of work compete for the same capacity. Platform work, compliance, migration effort, critical bugs, customer-facing features. As a result, many backlogs become distorted because teams compare very different kinds of work with one blunt scoring model.
WSJF makes the conversation more grounded. It asks what delay costs you and what size of job you're taking on. That makes it useful for leadership discussions, especially when technical enablers don't look flashy but enable future speed.
If you need support tools for this kind of evaluation, these AI tools for product feature prioritization are worth reviewing because they can help teams structure noisy input from users and stakeholders.
Use MoSCoW when alignment is the real problem
MoSCoW is simple, which is why it works.
When you're heading into an MVP, a release cut, or a deadline-driven planning cycle, teams often don't need another scoring formula. They need a hard conversation about what must ship, what can wait, and what won't happen now.
That “won't” category matters. It creates strategic honesty.
Pick the framework that fits the decision
Don't force one model onto every backlog decision. Use the tool that matches the shape of the problem.
A simple rule set works well:
- Choose RICE when product teams are comparing user-facing opportunities.
- Choose WSJF when multiple work types compete across a constrained delivery system.
- Choose MoSCoW when stakeholder alignment and scope discipline matter most.
If your leadership team needs a broader view of how these choices fit into decision quality, this guide to decision-making frameworks in delivery and product work is a solid companion.
Prioritisation isn't about ranking every idea. It's about protecting capacity for the few things that move the business.
Measuring What Matters for Predictable Delivery
Backlog management should show up in delivery performance. If it doesn't, you're tidying tickets, not improving execution.
The most useful signal here is flow. How quickly does work move from decision to delivery? How much gets stuck? How often does active work sprawl across too many items at once? These questions matter more than whether your backlog “looks organised”.
This is the metric view that leaders should care about:

Start with lead time
Lead time tells you how long it takes for a change to move through the system and reach delivery. It is one of the clearest ways to assess whether your operating model is responsive.
The 2024 DORA and Google Cloud State of DevOps benchmark shows that elite performers had lead time for changes of less than one day, while low performers took between one month and six months (DORA benchmark summary).
That gap should change how you think about backlog management. A slow lead time isn't just a delivery problem. It usually reflects oversized work, unclear priorities, hidden dependencies, and too much work waiting in the system.
Watch cycle time, throughput, and WIP together
Lead time matters, but don't look at it alone.
Use a small set of operational metrics:
- Cycle time: How long work takes once the team starts it.
- Throughput: How many items the team finishes in a given period.
- Work in progress: How much active work the team is juggling at once.
When WIP expands, context switching follows. When context switching rises, throughput gets noisy. When throughput gets noisy, planning quality drops. That's how “we're very busy” turns into “we still missed the release”.
Measure value flow, not ticket motion
A mature team doesn't celebrate backlog movement. It cares about delivered outcomes.
Ask sharper questions:
- Did high-priority items reach customers predictably?
- Did technical debt reduction unblock future delivery?
- Did the queue stay stable enough for teams to commit with confidence?
- Did emergency work repeatedly displace strategic work?
Those conversations expose whether the backlog is acting as a filter or a dumping ground.
Operational check: if most sprint disruption comes from work that “should have been obvious earlier”, your backlog shaping discipline is too weak.
For executives, this is the payoff. Better backlog management improves predictability, and predictability builds trust. Teams stop negotiating chaos every sprint. The business gets a more reliable path from idea to value.
Common Backlog Pitfalls and How to Crush Them
The most dangerous backlog myth is that keeping everything is responsible.
It isn't. It's avoidance.
A bloated backlog gives the illusion of optionality, but in practice it creates noise, hides what matters, and drains senior attention into reviewing work that nobody should build. Teams say they're preserving ideas. What they're really preserving is indecision.
Backlog rot is real
One of the most useful rules in backlog hygiene is also one of the most ignored. Give ideas an expiry date.
Expert guidance recommends assigning backlog items a 3–6 month due date and deleting rotten items that miss the window, explicitly because stale work blocks discovery and delivery. That matters even more in the UK, where 63% of digital organisations reported a digital skills gap in 2024 and the estimated annual cost of that gap was £63 billion (Atlassian backlog guidance and UK skills context).
If senior technical people are spending time reviewing stale requests, your backlog is stealing capacity from real progress.
The anti-patterns worth eliminating fast
A few backlog habits should trigger immediate correction:
- The “just in case” queue: Ideas sit for ages with no sponsor, no urgency, and no defined outcome.
- Vague story writing: Teams enter delivery still asking what the item means.
- Priority inflation: Every stakeholder labels their request critical.
- No deletion culture: Work survives because nobody wants to be the person who removes it.
The fix is not subtle. Delete harder. Split earlier. Challenge more.
A simple hygiene policy
Run your backlog with explicit rules:
- Every item needs an owner
- Every item needs a reason to exist
- Items without movement expire
- Unclear work does not enter delivery
- If priorities change, the backlog changes with them
That last point matters. Backlog management isn't a museum of historical requests. It's a live statement of intent.
A clean backlog doesn't mean you lack ideas. It means you know how to choose.
Teams that embrace this become easier to manage and faster to trust. They spend less time excavating old decisions and more time shipping work that still matters.
Supercharging Delivery with Nearshore Teams and AI
Distributed delivery exposes every weakness in backlog management.
When teams work across locations, ambiguity gets more expensive. You can't rely on hallway clarification, local tribal knowledge, or heroic intervention from a senior person sitting nearby. The backlog has to do more work. It has to carry context, sequencing, constraints, and decision clarity across the whole delivery system.
That's why nearshore models work best when the operating discipline is strong, not loose.
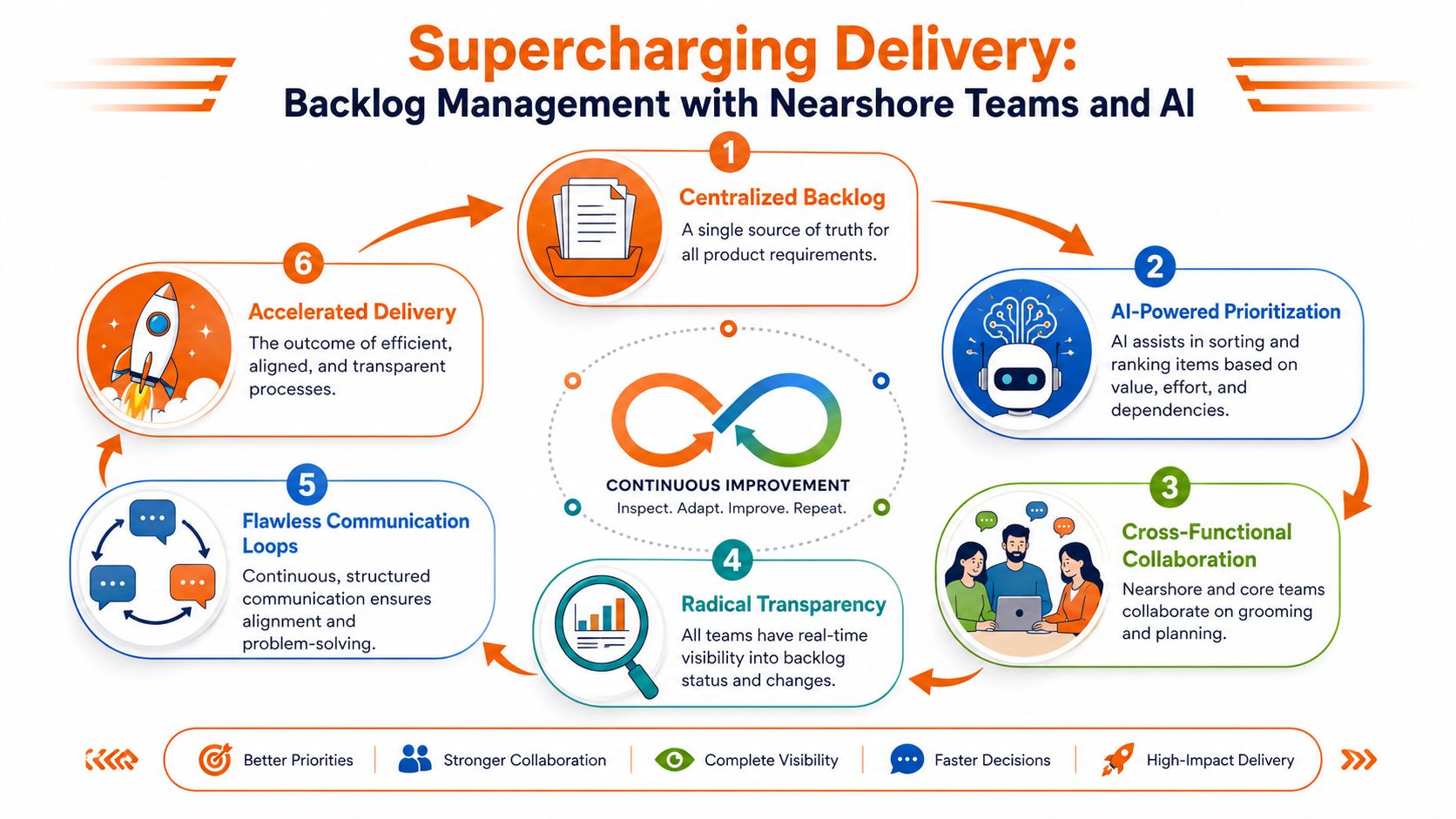
Why senior distributed teams handle backlog complexity better
Senior engineers don't need hand-holding. They need direction, context, and room to solve problems properly.
That matters in nearshore setups because experienced people can spot missing assumptions, challenge weak scope, and help shape stories before those stories become delivery risk. They reduce management overhead by closing clarity gaps early. That's a major advantage when speed and predictability both matter.
If you're weighing how this model works in practice, this overview of nearshore software delivery is useful because it shows why communication design matters as much as raw capacity.
AI work needs a different backlog lane
Traditional backlogs assume work is linear and well bounded. AI work often isn't.
The UK Government's Technology Adoption Survey found that 72% of UK businesses had adopted at least one AI technology by 2024, up from 66% in 2023, and adoption is expected to keep rising in 2025 (AI adoption context for backlog management). That changes the shape of backlog management because AI-related work often includes experimentation, evaluation, prompt iteration, governance, and data quality tasks that don't fit neatly into standard feature-story assumptions.
A smarter model separates delivery work from AI discovery work. Don't force exploratory AI tasks into the same planning logic as deterministic feature development. You'll create false certainty and hide risk.
Where AI helps the backlog itself
AI is also useful inside the delivery process.
Used well, it can help teams:
- Draft user stories: Turn rough inputs into clearer starting points.
- Surface dependency patterns: Highlight related items and likely blockers.
- Summarise backlog themes: Make large queues easier to review.
- Support reporting: Reduce manual status collation for leads and stakeholders.
Platforms like BuddyPro's expert AI platform are worth exploring if you're assessing how AI capabilities can support operational workflows around planning, coordination, and execution.
This point is bigger than tooling. Predictable delivery happens when senior teams, clean backlog discipline, and AI-assisted workflows reinforce each other. That combination makes nearshore execution feel tight, transparent, and fast, not distant.
If your backlog has become a feature graveyard, Rite NRG can help you rebuild it into a delivery system that drives predictable business outcomes. We work with SaaS companies and product leaders who need senior nearshore teams, fast MVP execution, and AI-powered delivery processes that create clarity instead of chaos. If you want stronger ownership, sharper prioritisation, and a backlog your team can trust, talk to Rite NRG.

