


Most advice on code review processes is backwards. It treats review as a brake. Slow down. Check syntax. Catch mistakes. Approve reluctantly. Move on.
That mindset creates exactly the behaviour CTOs say they hate. Bigger queues, vague accountability, delayed releases, and senior engineers trapped in comment threads about trivia while product decisions wait. If your review process feels heavy, the answer isn't more ceremony. It's a better operating model.
Strong code review processes are a delivery system. They spread knowledge, harden architecture, sharpen judgement, and force ownership at the right moment, before weak decisions leak into production and become expensive habits. The teams that get this right don't review code as paperwork. They use review to increase delivery confidence and keep momentum high.
That's the core of the #riteway mindset. Extreme Ownership. High energy. Proactive communication. Reviews shouldn't be a grudging gate between “done” and “shippable”. They should help your team ship faster, with fewer handover risks and less hero dependency. If your process can't do that, redesign it.
Beyond Bug Hunts: Code Reviews as a Growth Engine
The old framing says code review exists to catch bugs. That's too narrow, and it leads to poor behaviour. Reviewers start acting like inspectors. Authors get defensive. Everyone optimises for approval rather than improvement.
You need a better definition. Code review processes should improve the team's ability to deliver valuable software repeatedly, without relying on a few overworked experts.
Why the quality gate mindset fails
A pure gate creates queues. Queues create context switching. Context switching kills flow. Then teams start bypassing reviews because “delivery is urgent”, which usually means the process was never fit for delivery in the first place.
It also pushes the wrong social dynamic. The author wants to get through the gate. The reviewer looks for reasons to block. Nobody is discussing the business outcome of the change, whether the design holds up, or whether the change leaves the system easier to evolve next month.
Code review done badly protects nobody. It just moves delay from development into approval.
If your senior engineers are spending their time correcting spacing, renaming variables to match personal taste, or replaying style debates already solvable with automation, you've built a bottleneck and called it engineering discipline.
What a growth engine looks like
A strong review process does four things at once. It improves decision quality, raises the floor for the whole team, creates traceable technical context, and builds confidence to release.
That matters commercially. Faster review cycles shorten the path from idea to customer value. Better review conversations reduce rework. Shared understanding means fewer stalls when a key engineer is on leave or leaves the company. A review process that strengthens ownership also reduces the need for management to constantly chase clarity.
Here's the point I'd make to any CTO. Code review processes are not about policing developers. They're about building a team that can scale delivery without lowering standards.
The shift that changes everything
Treat each review as a small operating ritual for the product, not a compliance task for the repository.
- Ask business-impact questions: Does this change make the product easier to evolve, safer to release, or clearer to support?
- Reward clear ownership: The author owns quality before review begins. The reviewer owns speed and clarity once it lands in the queue.
- Use review to develop people: Every comment should either improve the product or strengthen team judgement.
That's how reviews stop being a drag and start becoming a competitive advantage.
Defining the Why of Modern Code Review Processes
If your team can't explain why it reviews code, the process will decay into habit and opinion. One engineer will use reviews to enforce personal preferences. Another will skim and approve to stay “fast”. Neither approach serves the business.
Modern code review processes need a clear purpose. I use four pillars. If a review practice doesn't support one of these, cut it.
Quality and maintainability
Yes, review should catch problems. But the bigger win is maintainability. A change that technically works and still makes the codebase harder to extend is a bad deal. You'll pay for it later in slower delivery, fragile changes, and avoidable refactoring.
Reviewers should ask practical questions. Is the intent obvious? Does the change fit existing patterns? Will another engineer understand the trade-off six months from now? Those are business questions because they affect the cost of change.
Knowledge sharing
In code reviews, many teams leave value on the table. Reviews are one of the few recurring moments where engineers see work outside their immediate lane. Used well, that reduces dependency on specialists and spreads operational understanding across the team.
Teams that prioritise knowledge sharing during code reviews reduce their bus factor and can onboard new engineers up to 40% faster, leading to more resilient and scalable teams, according to DORA's guidance on code maintainability.
That's not a nice-to-have. That's resilience.
Ownership and accountability
A healthy review process makes ownership visible. The author shows their thinking, tests their own work, and explains trade-offs. The reviewer responds promptly, focuses on important issues, and helps the team move.
Practical rule: If nobody clearly owns review quality, everyone assumes someone else does.
Ownership also means authors don't throw code over the wall. “Please review” is not enough. Explain what changed, why it changed, what risk sits inside it, and where you want the sharpest scrutiny.
Architectural consistency
Growth-stage products often break here first. The team ships quickly, then every feature pulls the system in a slightly different direction. Reviews are the cheapest recurring point to protect architecture before drift becomes expensive.
Use them to keep boundaries clean, patterns consistent, and design choices deliberate. Not rigid. Deliberate.
A simple test helps:
- If it's a logic issue, fix it.
- If it's a readability issue, improve it.
- If it's an architectural issue, stop and discuss it properly.
- If it's a preference issue, don't block delivery unless the team standard says otherwise.
Choosing Your Code Review Workflow
There isn't one best workflow. There's only the workflow that best supports your product stage, your team shape, and your delivery tempo. Teams get into trouble when they copy a model because it's fashionable rather than because it fits.
Three workflows cover most environments well: synchronous pair or mob review, asynchronous pull request review, and automated gated check-ins. The smart move is often combining them instead of pretending one model solves everything.
Three models, three trade-offs
| Model | Review Speed | Knowledge Sharing | Best For |
|---|---|---|---|
| Pair or mob programming | Immediate | High | Complex features, rapid discovery, high-ambiguity work |
| Pull request workflow | Moderate | Medium to high, depending on discipline | Most product teams, distributed collaboration, auditability |
| Automated gated check-ins | Fast for routine checks | Low on its own | Baseline quality enforcement, repetitive standards, high-volume teams |
Pairing is excellent when the cost of misunderstanding is high. A difficult refactor, risky integration, or fuzzy product requirement benefits from live discussion. People can challenge assumptions in real time, and the review is effectively happening while the change is being created.
The downside is obvious. Pairing consumes synchronous time. If you force it onto routine work, you'll burn expensive engineering attention on changes that could have moved cleanly through an asynchronous path.
When pull requests are the right default
Typically, the PR workflow is the practical centre. It creates a written trail, supports distributed teams, and gives reviewers room to evaluate changes without forcing calendar coordination. It also aligns naturally with a disciplined continuous integration approach where checks run automatically before human review.
PRs work best when they're small, well-described, and routed quickly. They fail when authors submit giant bundles of unrelated changes and reviewers treat the queue as optional. That isn't a tooling problem. It's an operating habit problem.
Small, focused changes get reviewed. Bloated changes get postponed, skimmed, or rubber-stamped.
Where automation should sit
Automated gated check-ins should remove noise before a human gets involved. Linting, formatting, unit tests, static analysis, and policy checks belong here. Machines are good at consistency. Use them.
But don't confuse automated checks with review. Automation can tell you whether a rule fired. It can't tell you whether the implementation makes sense for the product, whether the abstraction is sensible, or whether the change introduces future maintenance pain.
A practical selection framework
Choose your workflow based on the nature of the work, not ideology.
- Use pairing for uncertain work: New domain logic, brittle legacy areas, or changes with many edge cases.
- Use PR reviews for standard product delivery: Most feature work, bug fixes, integrations, and cross-team collaboration.
- Use automated gates everywhere: They should sit underneath every workflow and clear out low-value comments before people engage.
You can also layer them.
- Pair on the design.
- Open a tight PR for traceability.
- Let automation enforce baseline checks.
- Reserve reviewer attention for logic, maintainability, and system impact.
That combination gives you speed without sloppiness. More importantly, it keeps senior engineers focused on judgement, which is the scarcest resource in most software teams.
The #riteway Playbook for High-Energy Reviews
Process matters. Behaviour matters more. I've seen decent workflows fail because the team brought low standards and low energy into them. I've also seen straightforward review setups perform brilliantly because the people involved acted with urgency, clarity, and ownership.
That's what the #riteway playbook is built around. Reviews should be prepared properly, handled quickly, and framed around product impact. No passive handoffs. No adversarial tone. No theatre.

What authors must do before asking for review
A review starts before the PR opens. The author sets the quality bar.
Here's the minimum standard I expect:
- Self-review first: Read your own diff as if you were the reviewer. Remove noise, fix obvious naming issues, and catch dead code before anyone else spends time on it.
- Keep scope tight: One change, one purpose. Don't bundle refactors, bug fixes, and feature work together unless they are inseparable.
- State the intent clearly: Explain why the change exists, what trade-offs you made, and where reviewers should focus.
- Prove readiness: Make sure automated checks pass and the branch is reviewable.
A good PR description is short, useful, and specific. It tells the reviewer what matters. It doesn't force them to reverse-engineer your thinking from the diff.
How reviewers should respond
Reviewers own momentum. If a change sits untouched, that's not just an engineering irritation. It's a delivery failure.
Reviewers should focus on issues that materially affect quality, maintainability, security, architecture, or user impact. Everything else should be secondary.
Use comments with clear intent:
- Blocking issue: This must change before merge because it creates real risk.
- Suggestion: This would improve the implementation, but it isn't a release blocker.
- Question: I need clarification because the reasoning isn't obvious.
- Kudos: This is a good decision worth reinforcing.
Review the change, not the person. Precision beats personality every time.
What high-energy review culture sounds like
The tone matters. Lazy comments create friction. Precise comments create movement.
Weak feedback:
- “This is wrong.”
- “I don't like this approach.”
- “Can you clean this up?”
Strong feedback:
- “This introduces duplicate business logic in two services. Pull it into one boundary before merge.”
- “I'm not blocking this, but the naming hides the domain intent. Consider aligning it with the API terminology.”
- “This branch mixes a refactor with a feature change. Split it so we can review the risk properly.”
A lightweight operating rhythm
You don't need a bloated policy manual. You need a few essential habits.
- Authors open review-ready changes only.
- Reviewers respond promptly and don't leave work to rot.
- Comments separate blockers from preferences.
- Disagreements move quickly to direct conversation.
- The author owns the merge and post-merge verification.
That final point matters. Ownership doesn't end at approval. If something breaks after merge, the author shouldn't vanish into the next ticket. They should verify outcomes and close the loop.
This is how code review processes stop draining the team and start strengthening it. Fast doesn't mean careless. It means prepared, decisive, and accountable.
Measuring Review Impact with the Right KPIs
If you measure the wrong thing, your team will optimise for nonsense. I've seen organisations track review volume, comment counts, and lines changed as if those metrics reveal engineering health. They don't. They usually reward noise, bureaucracy, or large diffs.
Measure code review processes by their impact on delivery flow and release confidence.
Here's a useful visual summary of the kinds of signals leadership teams often want to watch:

Metrics that actually help
Start with a compact KPI set and review it consistently.
- Review turnaround time: How long a change waits before meaningful review starts. This exposes queue problems and reviewer overload.
- Comment-to-resolution time: How long it takes to close the loop once feedback is given. This shows whether discussions are crisp or dragging.
- Defect escape rate: What still reaches later environments or production after review. This tells you whether the review process catches meaningful issues.
- Rework patterns: Which kinds of comments repeat across teams. Repeated feedback often means your standards belong in automation, templates, or onboarding.
Review matters for leadership teams trying to connect engineering habits to business performance. Elite-performing teams, as identified by DORA research, consistently keep their change failure rates under 15% and have lead times for changes of less than one hour, goals which effective review processes directly support, as noted in Google Cloud's summary of the Accelerate State of DevOps findings.
That's the benchmark mindset worth pursuing. Fast changes. Low failure. Review should support both.
Metrics to avoid turning into targets
Don't score people by number of comments left or number of PRs approved. You'll train reviewers to perform activity instead of judgement.
Also avoid using review metrics as a hidden productivity surveillance system. If engineers think every review action is being used to rank them, they'll game the process. Then your dashboard looks tidy while your delivery system gets worse.
Track the process to improve the system. Don't weaponise the numbers against individuals.
For a broader delivery lens, I'd also align review KPIs with engineering throughput and team health, not in isolation but alongside measures discussed in this guide to improving engineering productivity.
Use media and conversation together
A short explainer often helps leadership teams understand how reviews fit into engineering performance, especially when they're trying to fix delivery bottlenecks without creating more ceremony.
How to interpret the signals
If turnaround time is poor, you probably have a prioritisation or capacity problem. If comment-to-resolution drags, your comments may be unclear or your changes too large. If defects escape despite heavy review, the team is likely focusing on the wrong issues.
The point isn't to create a perfect dashboard. It's to identify friction quickly and fix the operating habits behind it.
Your Tech Stack for Smarter Code Reviews
Your tooling should remove friction, not add another layer of admin. Human reviewers should spend their attention on design choices, business logic, and architectural consequences. They should not waste time on formatting noise, obvious test failures, or repetitive conventions.
Build a stack that handles the routine automatically and pushes context to the surface.
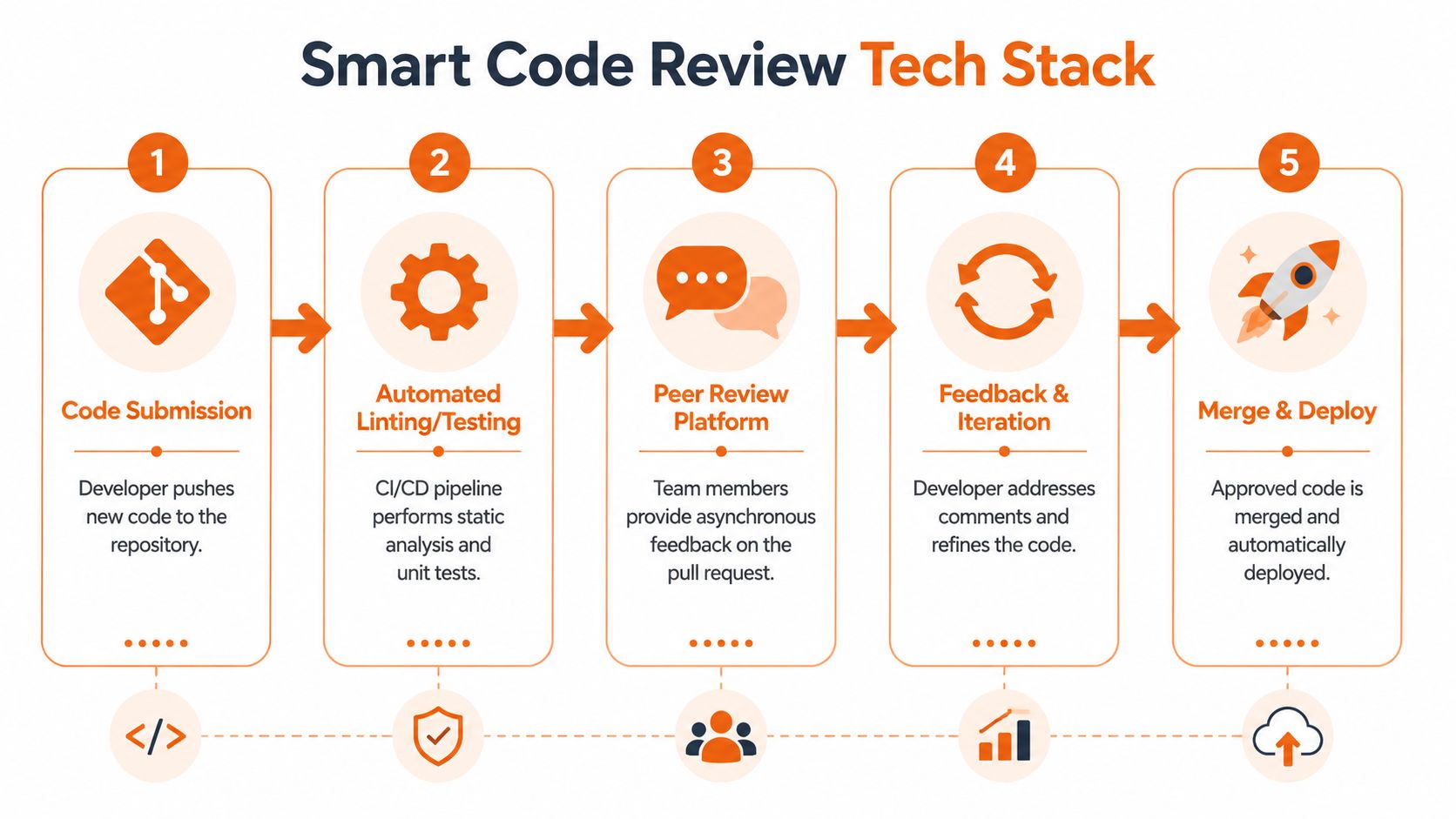
What belongs in the automated layer
Start with the basics and make them non-optional. Use linters and formatters so style arguments disappear from human review. Run unit tests and static analysis in CI so broken branches don't enter the queue. Tools such as SonarQube, ESLint, Prettier, Checkstyle, RuboCop, Pylint, and Stylelint all have a place, depending on your stack.
Repository platforms matter too. GitHub, GitLab, and Bitbucket all support branch protection, required checks, reviewer assignment, and templated pull requests. Use those features properly. They create consistency without extra meetings.
A solid baseline looks like this:
- Formatting and linting: Remove subjective debate before review begins.
- Automated tests: Catch regression risk early.
- Static analysis: Surface maintainability and reliability concerns quickly.
- PR templates: Force authors to explain intent, impact, and review focus.
- Branch policies: Prevent “just merge it” behaviour under pressure.
Where AI can help, and where it can't
AI-assisted review tools can reduce cognitive load. They can summarise diffs, point out suspicious patterns, and suggest areas worth a closer look. GitHub Copilot features, review assistants in repository platforms, and specialist analysis tools can all improve first-pass visibility.
But don't outsource judgement. AI can flag patterns. It can't reliably understand your product's commercial context, the architecture you're intentionally moving towards, or the trade-off behind a tactical compromise.
The best use of AI in code review is triage, not authority.
That means using AI to accelerate preparation and prioritisation, then letting experienced engineers make the actual call.
Build around your system, not someone else's demo
Your stack should fit the architecture and team model you already run. A monolith with strict release discipline needs a different review setup from a fast-moving SaaS platform shipping across multiple services. If you want a grounded example of how engineering environments evolve in practice, this deep dive into Alphasights' technology is worth reading because it shows how stack choices connect to organisational needs rather than abstract best practice.
A practical sequence works well:
- Code enters the repository.
- Automation rejects low-quality or incomplete changes.
- The platform presents context clearly to reviewers.
- Humans review logic, architecture, and product impact.
- Approved changes merge through a predictable path.
That's the right split of labour. Machines enforce consistency. Engineers provide judgement. Delivery gets faster because attention goes where it matters.
Scaling Code Reviews with Nearshore Partners
Nearshore collaboration doesn't fail because of geography. It fails when ownership is weak, expectations are fuzzy, and review habits rely on hallway conversations that distributed teams will never have.
Well-run code review processes solve that. They create a shared operating language across locations, reduce dependency on synchronous access, and make quality visible. If you want distributed delivery to work, review discipline is part of the foundation, not an optional extra.
What good distributed review looks like
Nearshore teams should work inside the same standards, repositories, and review rituals as your core team. Not beside them. One backlog. One definition of done. One set of review expectations.
That means:
- Clear PR context: The author explains purpose, risk, and areas needing attention.
- Asynchronous discipline: Comments are precise enough to move work forward without a meeting.
- Shared standards: Coding conventions, architectural boundaries, and review labels are agreed once and used consistently.
- Escalation paths: If a thread stalls, the team moves quickly to a call and closes the issue.
If you're still treating a nearshore partner like an external code factory, you'll get transactional behaviour. If you treat them like part of the delivery system, with full accountability and visibility, you'll get better outcomes.
Turn time zones into an advantage
A distributed setup can improve flow when your review process is structured properly. One team finishes a change with clear context. Another team picks it up and reviews while the author is offline. Work keeps moving.
That only happens when the process is crisp. Vague tickets, weak PR descriptions, and undocumented architectural assumptions will break the handoff immediately. Strong asynchronous practice, by contrast, creates resilience and continuity. If you're evaluating this model, this overview of nearshore software delivery is a useful starting point for thinking about team integration rather than simple staff augmentation.
Distributed teams don't need more control. They need clearer ownership and better written communication.
The CTO call
If your nearshore team can't participate in review as equal owners, your model is wrong. Fix that first.
Good partners don't just submit code and wait for approval. They challenge weak assumptions, document trade-offs, and help protect delivery speed. That's when nearshore stops being a capacity play and starts becoming a strategic advantage.
If you want a delivery partner that treats code review processes as part of a bigger system for speed, ownership, and predictable outcomes, talk to Rite NRG. We help CTOs build high-performing product teams that ship faster without losing control.

