


Your product team is pushing for faster releases. Operations wants fewer incidents. Security keeps joining late and blocking deploys. Meanwhile, your engineers are drowning in manual steps, flaky environments, and handoffs that nobody owns. That's usually the point when leaders start looking at DevOps consulting services.
Good. But many buyers still frame DevOps as a tooling exercise. It isn't. It's an operating model for building, shipping, recovering, and improving software without burning out the team that runs it. If your consultant only leaves behind a CI pipeline and a Kubernetes cluster, you haven't bought capability. You've rented expertise.
The right partner fixes delivery bottlenecks and leaves your team stronger than they found it. That's the standard. Anything less creates dependency, and dependency gets expensive fast.
Why DevOps Consulting Is More Than Just Automation
Most CTOs don't wake up wanting “better DevOps”. They want releases that don't drag, incidents that don't spiral, and engineering teams that stop arguing about whether a failure belongs to dev, ops, or somebody in between.
That's why strong DevOps consulting services matter. They aren't there to install tools and vanish. They should diagnose where delivery is breaking down, fix the operating model, and build habits your team can sustain. Automation is part of it, but automation without ownership just helps you fail faster.
The UK market reflects that shift. Consulting Services lead the UK DevOps market segment, and the market is projected to grow from USD 714.95 million in 2024 to USD 2,800.63 million by 2035 at a CAGR of 14.63%, according to UK DevOps market projections from Market Research Future. That matters because it shows where buyers are putting money. They want guidance through implementation complexity, not just more software licences.
The real problem isn't tooling
Teams rarely fail because they picked the wrong CI server. They fail because no one aligned release process, infrastructure standards, incident response, and team responsibilities. I've seen companies buy GitHub Actions, Terraform, Docker, Kubernetes, Prometheus, and a shelf full of security scanners, then still struggle to ship reliably because nobody owned the system end to end.
That's where an ownership-led approach changes the outcome. The #riteway mindset starts with Extreme Ownership. If a release is slow, the consultant owns the diagnosis. If environments drift, the consultant drives a repeatable fix. If engineers can't maintain what was built, the engagement isn't done.
Build systems your team can run at 02:00 on a bad day, not architectures that only look good in a sales deck.
What good consulting actually changes
A solid DevOps engagement should help you:
- Reduce delivery friction by removing manual approvals, inconsistent environments, and brittle deployment steps.
- Improve resilience through monitoring, rollback paths, and clearer operational ownership.
- Create alignment across product, engineering, operations, and security, so delivery speed doesn't come at the cost of stability.
- Transfer capability into the internal team instead of turning the consultant into a permanent crutch.
That last point is the hidden differentiator. DevOps isn't a platform you buy. It's a capability you build.
What to Expect from Top-Tier DevOps Consulting
Plenty of firms promise “end-to-end DevOps”. That phrase is too vague to be useful. You need to know what a serious engagement delivers and why each part affects the business.
This gives a cleaner view of the scope.
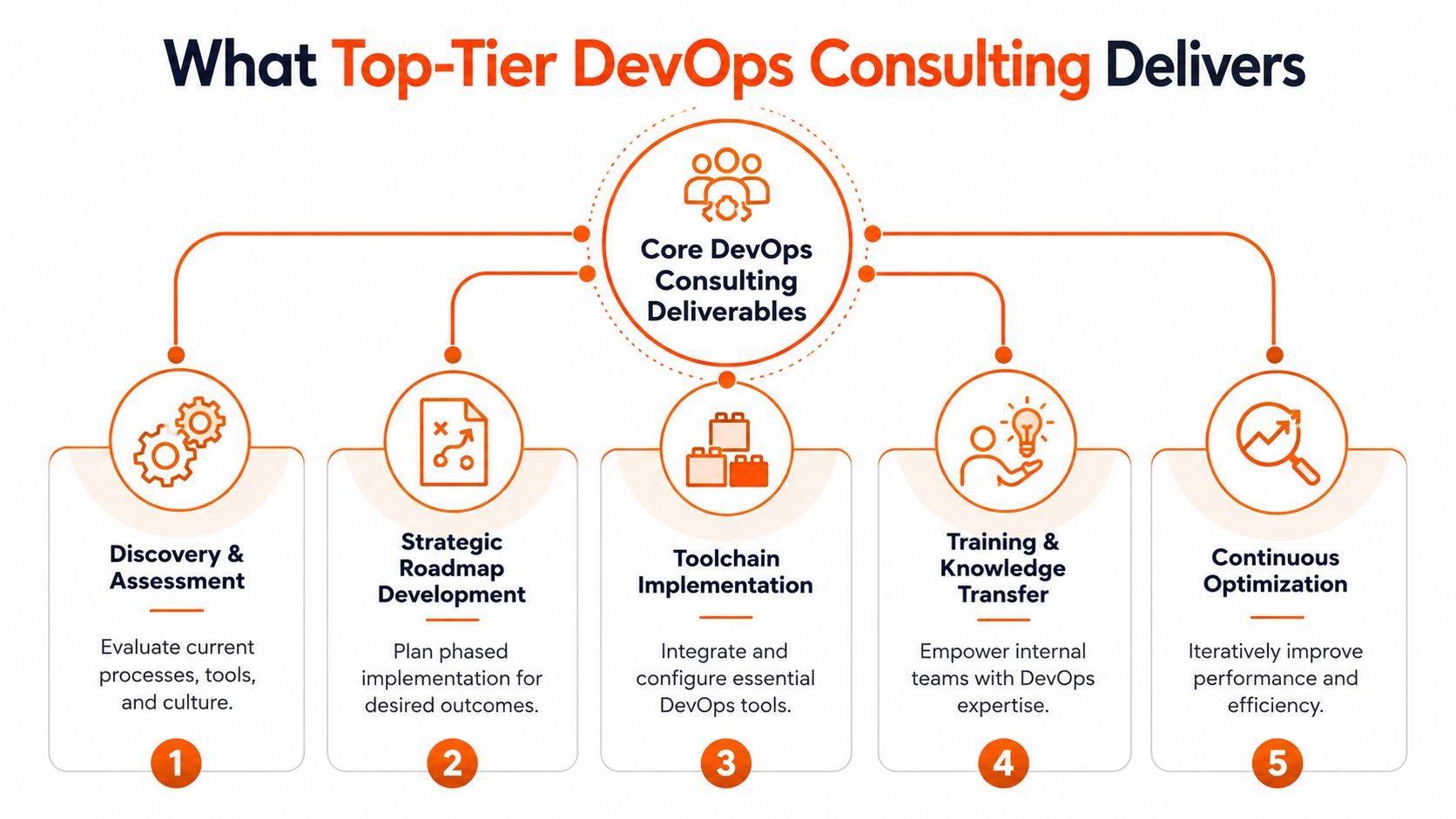
Discovery before delivery
The first deliverable should be a proper assessment. That means reviewing release workflows, cloud setup, environments, monitoring, access controls, incident handling, and team responsibilities. If a consultant wants to jump straight into “implementation” without understanding how work currently moves from commit to production, they're guessing.
A roadmap comes next. Not a bloated strategy document that gathers dust. A phased plan tied to business outcomes. If you're a SaaS founder preparing for enterprise onboarding, your roadmap should prioritise reliability, auditability, and deployment confidence. If you're scaling a product team, speed and repeatability will likely come first.
Core implementation that actually matters
The technical work should map directly to operational pain:
- Infrastructure as Code using tools like Terraform or Pulumi. This isn't about writing infra scripts for the sake of it. It's about making environments repeatable and reducing drift between staging and production.
- CI/CD pipeline automation with tools such as GitHub Actions, GitLab CI, Jenkins, or ArgoCD. The business gain is straightforward. Fewer manual steps, fewer release bottlenecks, and faster, safer changes.
- Containerisation and orchestration with Docker and Kubernetes when the product and team maturity justify them. Not every team needs Kubernetes on day one. Good consultants know the difference between scaling smartly and overengineering.
- Monitoring and observability with platforms like Prometheus, Grafana, Datadog, or New Relic. You can't manage reliability if the team can't see what's happening.
- Security integrated into delivery so access, secrets, vulnerability checks, and policy controls aren't bolted on at the end.
If security testing is part of your roadmap, this guide on Affordable Pentesting for startups is worth reviewing because it helps founders think about practical testing coverage without treating security as a late-stage add-on.
Training separates consultants from installers
Many firms fall short. They implement the toolchain, write some documentation, run a handover call, and move on. That's not enough.
Top-tier DevOps consulting services train the internal team while the work is happening. Engineers should learn how to update Terraform safely, troubleshoot the pipeline, read dashboards, and respond to incidents. Product and engineering leaders should understand release risk, operational trade-offs, and where delivery still depends on tribal knowledge.
Practical rule: if your team can't explain and operate the new setup before the engagement ends, the consultant hasn't finished the job.
Continuous optimisation keeps the gains
After rollout, the job shifts from building to tuning. Bottlenecks show up. Alerts need refining. Pipeline stages need trimming. Cloud spend needs watching. A good consulting partner keeps improving the system rather than declaring victory after the first deployment succeeds.
That's what operational excellence looks like in practice. Not a stack of tools. A delivery system your team can trust.
Measuring Success Beyond Code Deployment
If your consultant reports success by listing tools they installed, push back. Tools are inputs. You need outcome metrics.
This is the scoreboard.

The four metrics that matter most are straightforward: Deployment Frequency, Lead Time for Changes, Mean Time to Recovery, and Change Failure Rate. Leaders don't need to obsess over the labels. They need to understand the business signal behind them.
Four signals leaders should watch
| Metric | What it tells you | Why the business cares |
|---|---|---|
| Deployment Frequency | How often the team ships changes | Higher frequency usually means lower batch size and faster value delivery |
| Lead Time for Changes | How long it takes to move a change into production | Shorter lead time improves time-to-market and reduces queueing |
| Mean Time to Recovery | How quickly the team restores service after failure | Faster recovery protects revenue, trust, and support capacity |
| Change Failure Rate | How often releases cause problems | Lower failure rates mean fewer customer-facing surprises |
Good DevOps consulting services improve these numbers because they remove waiting, standardise deployments, improve visibility, and tighten feedback loops. According to Azilen's review of DevOps consulting outcomes, effective services can deliver 30% faster deployment cycles and reduce Mean Time to Recovery by 40%. Those are useful because they connect technical changes to executive priorities.
The business meaning behind the metrics
A faster deployment cycle isn't just a developer convenience. It means product teams can respond to customer feedback without waiting through long release trains. It means commercial teams aren't stuck apologising for roadmap slippage caused by operational friction.
A lower MTTR matters even more. Every serious SaaS team has incidents. The question isn't whether something will break. It's whether your team can detect it, isolate it, and recover without chaos. Better observability is central here, which is why this guide on monitoring and observability is worth keeping close if you're trying to mature operations rather than just add dashboards.
When incidents happen, speed of recovery says more about your operating model than the incident itself.
What not to measure
Don't let the engagement drift into vanity reporting. Number of pipelines created, clusters provisioned, or tickets closed won't tell you whether delivery improved. They describe activity, not impact.
Ask harder questions:
- Can we release with less coordination overhead?
- Can engineers diagnose production issues faster?
- Can product teams ship smaller changes with more confidence?
- Can the business take on growth without increasing operational fragility?
That's the shift from code deployment to commercial value. The board won't care that you containerised a service. They'll care that your product got faster to improve and harder to break.
Finding the Right Partnership Structure for Your Goals
Not every company needs the same engagement model. The wrong structure can kill a good initiative before the technical work even starts. If the scope is narrow, don't buy a transformation programme. If the need is strategic, don't patch it with one contractor and hope for the best.
Use this comparison to get your bearings.
Three common models
| Model | Best fit | Main strength | Main weakness |
|---|---|---|---|
| Staff augmentation | A team missing a specific skill | Fast access to expertise | Often weak on systemic change |
| Project-based engagement | A defined technical goal | Clear scope and deliverables | Can miss wider organisational blockers |
| Strategic partnership or retainer | Ongoing transformation and maturity work | Deep alignment and continuity | Needs trust and stronger leadership buy-in |
Staff augmentation works when your team already has a good operating model and primarily needs help with something specific, such as Terraform, Kubernetes, GitHub Actions, or cloud migration. It's efficient, but it won't fix ownership gaps, process friction, or poor release governance on its own.
Project-based consulting is the right call when the target is concrete. Build a CI/CD pipeline. Standardise environments. Introduce observability. Automate releases for a particular product area. This model works well when someone on the client side can absorb and sustain the change.
When you need a deeper structure
Strategic partnerships make sense when the business problem is bigger than one technical milestone. A scale-up might need a delivery partner that can improve release systems while supporting roadmap execution. An enterprise might need a Build-Operate-Transfer model to stand up a longer-term capability with strong local leadership and a clean path to internal ownership.
That kind of setup only works if the partner behaves like an operator, not a body shop. They need to challenge assumptions, expose risk early, and keep the work tied to business outcomes.
This short video gives a useful perspective on selecting an engagement style and thinking beyond resourcing alone.
A blunt selection rule
Choose the lightest model that can still solve the actual problem.
If you just need one engineer to unblock a migration, don't overbuy. If your release process, operational ownership, and internal capability are all weak, don't underbuy either. That usually creates a false economy where the team pays less upfront and much more later in delays, rework, and consultant dependency.
The engagement model should fit the operating challenge, not just the procurement budget.
Your Vendor Evaluation Checklist
Most buyers evaluate DevOps vendors the wrong way. They focus on tools, certifications, and hourly rates, then act surprised when the engagement produces a pile of technical changes and very little lasting improvement.
The bigger risk is dependency. According to Deployflow's analysis of managed DevOps services, 52% of DevOps initiatives fail within two years because consulting firms prioritise short-term delivery over long-term team enablement and knowledge transfer. That should change how you vet partners.
This checklist helps cut through the sales talk.

What to look for
- Evidence of ownership. Ask who is accountable when the first rollout hits friction. Serious partners don't hide behind statements of work. They surface issues early and drive resolution.
- A knowledge transfer plan. This should be explicit. You want shadowing, paired implementation, documentation standards, runbooks, and training built into delivery.
- Business-outcome thinking. If the proposal is tool-heavy and KPI-light, that's a warning sign.
- Clear communication habits. You need concise updates, fast escalation, and direct trade-off discussions. Fancy language won't save a weak delivery rhythm.
- Operator-level judgement. The right partner knows when to use Kubernetes, when not to, when to standardise aggressively, and when to leave well enough alone.
- Transparent pricing and scope control. If the commercial model rewards endless extension without capability transfer, expect drift.
Questions worth asking in the first call
Don't ask, “Do you do DevOps?” Everyone will say yes. Ask things that expose delivery behaviour.
- How do you make sure our team can run the platform without you?
- What do you expect our internal engineers to own by the middle of the engagement?
- How do you handle documentation, incident runbooks, and rollback processes?
- What's your approach when our existing architecture is part of the problem?
- How do you prevent a successful pilot from becoming a fragile one-off?
A lot of weak vendors struggle with those questions because their model depends on staying indispensable. That's the opposite of what you want. If you're building a shortlist and want a broader procurement lens, this guide to vendor due diligence is useful for pressure-testing capability, process, and commercial fit.
The standard that matters
A polished deck isn't enough. A long partner list isn't enough. Even strong technical credentials aren't enough if the consultancy can't build confidence inside your team.
Hire the partner that leaves behind stronger engineers, cleaner operational habits, and less dependency than they found.
That's the #riteway standard in practice. Extreme Ownership. High energy. Proactive communication. And no tolerance for hiding behind output when the outcome is what counts.
Launching Your DevOps Transformation
Once you've picked a partner, the work should start with structure, not noise. Good DevOps consulting services follow a phased path that creates momentum without blowing up day-to-day delivery.
A practical rollout sequence
Start with discovery and assessment. Review architecture, environments, deployment flow, monitoring gaps, access patterns, and operational pain points. Identify where delivery slows down, where incidents escalate, and where the team relies on manual knowledge.
Then run a pilot for quick wins. Pick one service, one team, or one release path. Standardise infrastructure, automate a deployment workflow, tighten observability, and prove the model in a contained area. This gives the internal team something concrete to learn from.
After that, scale and automate. Extend the patterns that worked. Add more services to the pipeline, improve rollback processes, harden security checks, and reduce drift across environments. If your infra baseline is weak, this is usually where a stronger Infrastructure as Code approach starts paying off because repeatability becomes an operational advantage.
Handover isn't an admin task
The final phase is team enablement and handover, but don't treat that as a final meeting and a document dump. It should include paired working, ownership transfer, operational playbooks, and clear definitions of what your internal team now runs independently.
That's the difference between transformation and temporary relief. If the consultant still owns every meaningful decision at the end, the engagement wasn't designed properly.
Pricing should be judged against risk and outcome
In the UK, DevOps consulting firms typically charge between £400 and £1,800 per day for implementation services, while ongoing managed DevOps services start from around £4,000 per month, based on UK G-Cloud pricing for DevOps services. Those figures are useful for setting expectations, but they shouldn't drive the decision on their own.
A cheap consultant who creates long-term dependency is expensive. A strong partner who builds repeatable systems, improves release confidence, and transfers knowledge can justify a higher rate because they reduce operational drag and lower strategic risk.
Price matters. But ownership, enablement, and outcome matter more.
From Pipeline to Profit Your Next Move
DevOps consulting services are worth buying when they improve how the business ships, recovers, and scales. Not when they only add more tooling. The hidden test is simple. Does the engagement leave you with a stronger internal capability, or just a cleaner dependency?
That's why knowledge transfer matters so much. Fast pipelines are useful. Stable infrastructure is useful. Better observability is useful. But the primary gain comes when your own team can operate all of it confidently, make sensible trade-offs, and keep improving without waiting for outside help.
Strong delivery leaders know this already. They don't buy motion. They buy outcomes. They want shorter release paths, better recovery under pressure, fewer operational surprises, and a team that can sustain the gains. That's the #riteway mentality. Own the problem, move with energy, and build systems people can run.
If you want a practical reminder of what strong execution looks like in the broader software delivery world, these Faberwork LLC achievements are a useful example of how outcome-led work is presented through real delivery stories rather than vague capability claims.
Your next move should be deliberate. Audit your current bottlenecks. Decide whether you need a project, a retained advisor, or a deeper strategic partner. Then pick the consultancy that's willing to make itself less necessary over time.
If you want a partner that treats DevOps as a business capability, not a tooling package, talk to Rite NRG. Their teams bring senior delivery judgement, proactive ownership, and the #riteway mindset to help SaaS companies ship faster, operate with more confidence, and build internal capability that lasts.
