


Most advice on how to improve engineering productivity is wrong because it starts with output. More tickets closed. More points delivered. More code merged. That mindset creates busy teams, not effective ones.
Engineering productivity is about delivering business value with less friction. If your team ships often, recovers fast, keeps quality under control, and spends less time waiting on handoffs, you have a productive system. If they look busy but releases still drag, customers still wait, and defects still bounce back into the roadmap, you don't.
That's where the #riteway mindset matters. Productivity doesn't improve because a team gets a new dashboard. It improves when leaders and engineers take Extreme Ownership of the whole delivery system. Not just “my ticket”. Not just “my sprint”. The whole path from idea to production. High-performing teams don't wait for permission to spot friction, surface risk, and fix what slows delivery. They act.
Stop Chasing Velocity Start Driving Value
Velocity is a sprint planning input. It is useless as a leadership target.
If you reward story points, hours, or lines of code, you get more story points, more hours, and more code. You do not get faster customer impact. You get bloated backlogs, larger batches, more coordination overhead, and teams that look busy while revenue-critical work waits in queues.
The right question is harsher and more useful. How quickly and reliably does engineering turn a business decision into customer value?
That standard changes behavior fast. Product starts cutting vague scope. Engineering starts reducing handoffs and release friction. Leaders stop praising effort and start fixing the system that delays outcomes. That is the #riteway approach in practice. Extreme Ownership means owning the full path to production, including dependencies, approvals, rework, and slow decisions. If a bottleneck sits outside your squad, surface it, quantify it, and force a decision.
Busy is not productive
Many teams have a permission gap, not a talent gap. Engineers can see the waste. They just have not been told they are allowed to redesign the way work flows.
That is why delivery stalls in plain sight:
- Code is finished, but reviews sit open for days.
- QA is active, but release windows are infrequent and approval-heavy.
- Managers report progress, but customers cannot use the feature yet.
- The roadmap is full, but a meaningful share of effort is trapped in rework, waiting, and coordination.
Each delay has a business cost. A feature that misses the right market window loses learning. An incident that takes too long to resolve burns customer trust. A team that spends half its week in handoffs needs more payroll to produce the same outcome.
This is also where strategy beats local optimisation. Teams that tie engineering to product discovery make better trade-offs upstream, before expensive build work starts. A clear opportunity solution tree for product decisions helps teams challenge low-value work before it enters delivery.
Value-driven productivity has four visible traits
A productive engineering system is easy to recognise:
| Focus area | What good looks like |
|---|---|
| Flow | Work moves in small batches with minimal waiting and fewer handoffs |
| Quality | Defects and rework stay controlled instead of bouncing back into the roadmap |
| Recovery | Incidents have clear ownership and get resolved fast |
| Business impact | Engineering capacity reaches customers and commercial goals, not internal churn |
This is the shift many CTOs still avoid. They keep asking whether engineers are working hard. Hard work is not the constraint. System design is.
Teams that outperform do three things differently. They connect engineering work to product strategy, they give teams permission to fix friction without committee theater, and they shape the team around delivery needs instead of headcount vanity. For AI product groups, Stoa's guide for AI teams is a useful reference on aligning product development strategy with execution choices.
Stop chasing output metrics that flatter the plan. Drive value with a system that ships the right work, with less delay, at a quality level the business can trust.
Establish Your Baseline with Outcome-Driven Metrics
Engineering productivity improves when leaders measure outcomes that expose delay, quality risk, and business drag. Activity metrics hide all three.
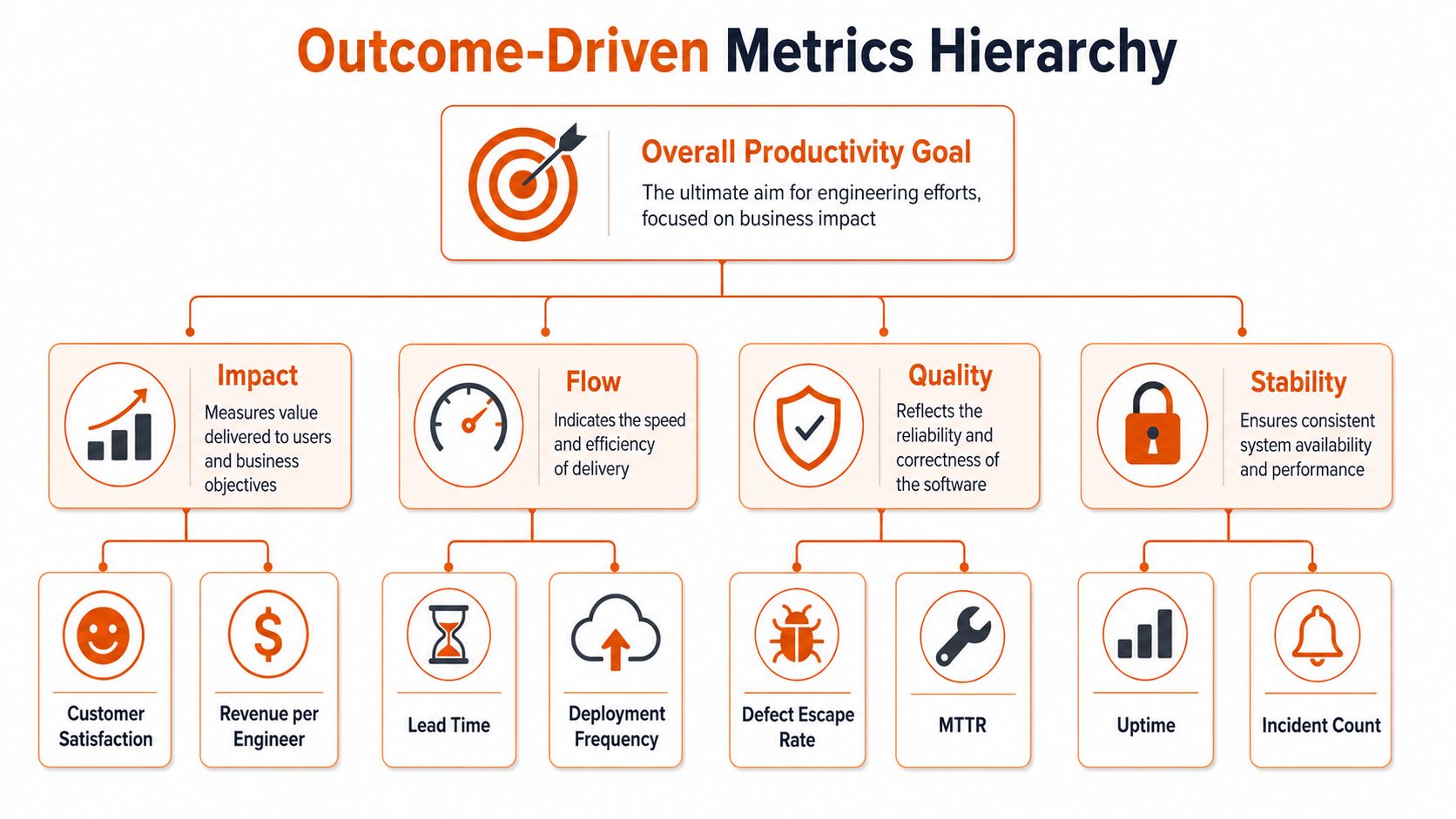
Start with four delivery signals that matter
Use a tight baseline. Four metrics are enough to show whether your system ships safely and learns fast:
Lead time for changes
Measure the time from commit to production. If lead time is long, work is sitting in queues, bouncing across teams, or waiting on weak automation.Deployment frequency
Measure how often you release to production. High-performing teams ship in smaller batches because small changes lower risk and shorten feedback loops.Change failure rate
Measure how often a release causes an incident, rollback, hotfix, or serious defect. Rising failure rates mean your speed is creating rework instead of value.Time to restore service
Measure how fast the team recovers from production problems. This is the clearest signal that ownership is real and operational discipline exists.
These are useful because they expose system behavior, not personal busyness. They show where work slows down, where quality breaks, and where leadership has tolerated friction for too long.
Build a baseline your leadership team can use
Do not wait for a new platform. Pull the first version from GitHub, GitLab, Jira, Linear, CI logs, and incident records. Then review the trends every month with engineering, product, and delivery leaders in the same room.
Use a baseline that covers:
- Delivery speed: Lead time and deployment frequency
- Release quality: Change failure rate and defects per release
- Operational resilience: Time to restore service
- Workflow health: Review time and work in progress
Then connect those metrics to product outcomes and cost. A seven-day review queue is not just an engineering annoyance. It delays revenue, extends feedback cycles, and increases the chance that teams build the wrong thing at full cost.
That is the permission gap many companies refuse to fix. Teams can see the bottleneck. Leadership still treats it as normal.
Tie delivery metrics to decision quality
Metrics only help if the roadmap deserves to be built. If weak ideas enter delivery, clean dashboards will not save you.
Use a structured opportunity solution tree for product decisions to challenge low-value work before it reaches engineering. That is how you stop random delivery churn and keep capacity focused on customer problems that matter.
Teams building AI products face this problem even harder because experimentation can blur ownership and priorities. Stoa's guide for AI teams is a useful reference for tightening the link between product strategy and execution choices.
Avoid the three baseline mistakes that waste time
The first mistake is tracking vanity metrics. Story points closed, hours logged, and lines of code reward motion, not results.
The second is measuring too much too early. A bloated dashboard creates reporting work and hides the actual constraint.
The third is using metrics as surveillance. Productivity is a system property. If managers use the numbers to pressure individuals, teams will game the data and protect themselves instead of fixing flow.
Good baselines create ownership. Under the #riteway approach, that means engineers, managers, and leadership all act on what the metrics expose. No waiting for another committee. No pretending the bottleneck belongs to someone else.
Good metrics show where value is getting stuck, what it costs the business, and who needs to fix it.
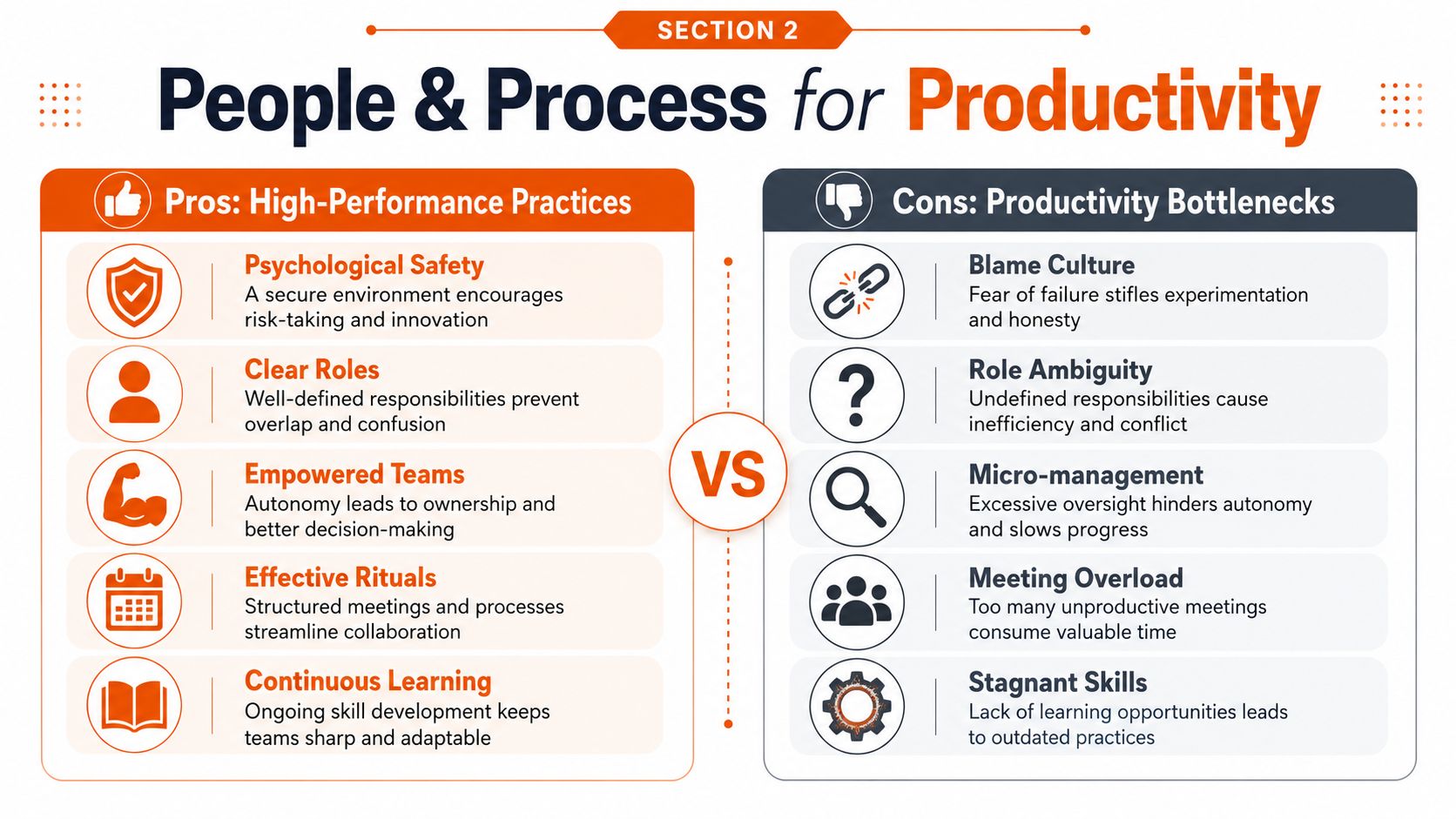
Engineer Your Team and Rituals for High Performance
Most productivity problems don't come from lack of effort. They come from poor team design, fuzzy ownership, and rituals that drain attention.
Tools matter, but structure matters more. A weak team setup will turn a strong toolchain into a slower mess. A strong team setup can keep delivery moving even with imperfect tooling.
Separate active work from wait time
Leaders often identify the underlying issue. Engineers aren't slow. Work is waiting.
The Worklytics guidance on engineering productivity recommends measuring flow efficiency across coding, review, QA, staging, and deployment by separating active work from wait time, then attacking the biggest source of delay first. That is exactly the right move.
If coding takes hours and review takes days, your bottleneck is review. If staging takes too long because environments are unreliable, your bottleneck is provisioning. If low-risk changes need too many approvals, your bottleneck is governance.
Fix the team before you buy another tool
High-performance delivery teams usually share a few traits:
- Clear decision ownership: Somebody owns release decisions, quality gates, and escalation paths.
- Senior enough composition: The team doesn't need constant external approval for routine delivery work.
- Cross-functional proximity: Product, design, engineering, and QA stay close enough to solve issues before they become queues.
- Rituals built for action: Stand-ups surface blockers. Refinement removes ambiguity. Reviews make decisions.
A strong tech lead is often the hinge point here. The role works best when it drives technical clarity, removes blockers, and protects flow. This breakdown of tech lead responsibilities is useful if your current setup has ownership gaps disguised as collaboration.
Teams don't slow down because they lack effort. They slow down because nobody owns the queue between steps.
Rituals that help and rituals that hurt
Here's the blunt version:
| Keep doing | Stop doing |
|---|---|
| Short decision-focused stand-ups | Status meetings with no outcome |
| Async updates for routine visibility | Dragging everyone into every discussion |
| Tight review SLAs | Letting pull requests age in silence |
| Small batch releases | Holding work for big coordinated drops |
| Clear WIP limits | Starting more work than the team can finish |
In this scenario, Extreme Ownership becomes practical, not motivational. Teams with ownership don't say, “QA is blocked” and move on. They ask why, fix the handoff, and change the workflow so the same blockage doesn't repeat next week.
Protect attention like it matters
Because it does.
Worklytics also points to reducing standing meetings, limiting work in progress, and using async updates plus focus hours to protect engineering attention. That's not soft advice. It's core throughput discipline. Fragmented attention turns simple changes into stretched delivery cycles.
High-performing teams treat calendars, review queues, and approval paths as production systems. They tune them aggressively. You should too.
Streamline Your Delivery Engine for Maximum Flow
Feature pressure is not your real delivery problem. Queue time is.
Your pipeline decides how fast value reaches customers and how much waste your team absorbs on the way. Flaky tests, slow builds, manual approvals, brittle environments, and risky deployments all create wait states. Wait states hide inside "busy" teams, then show up later as missed dates, rework, and rising delivery cost.
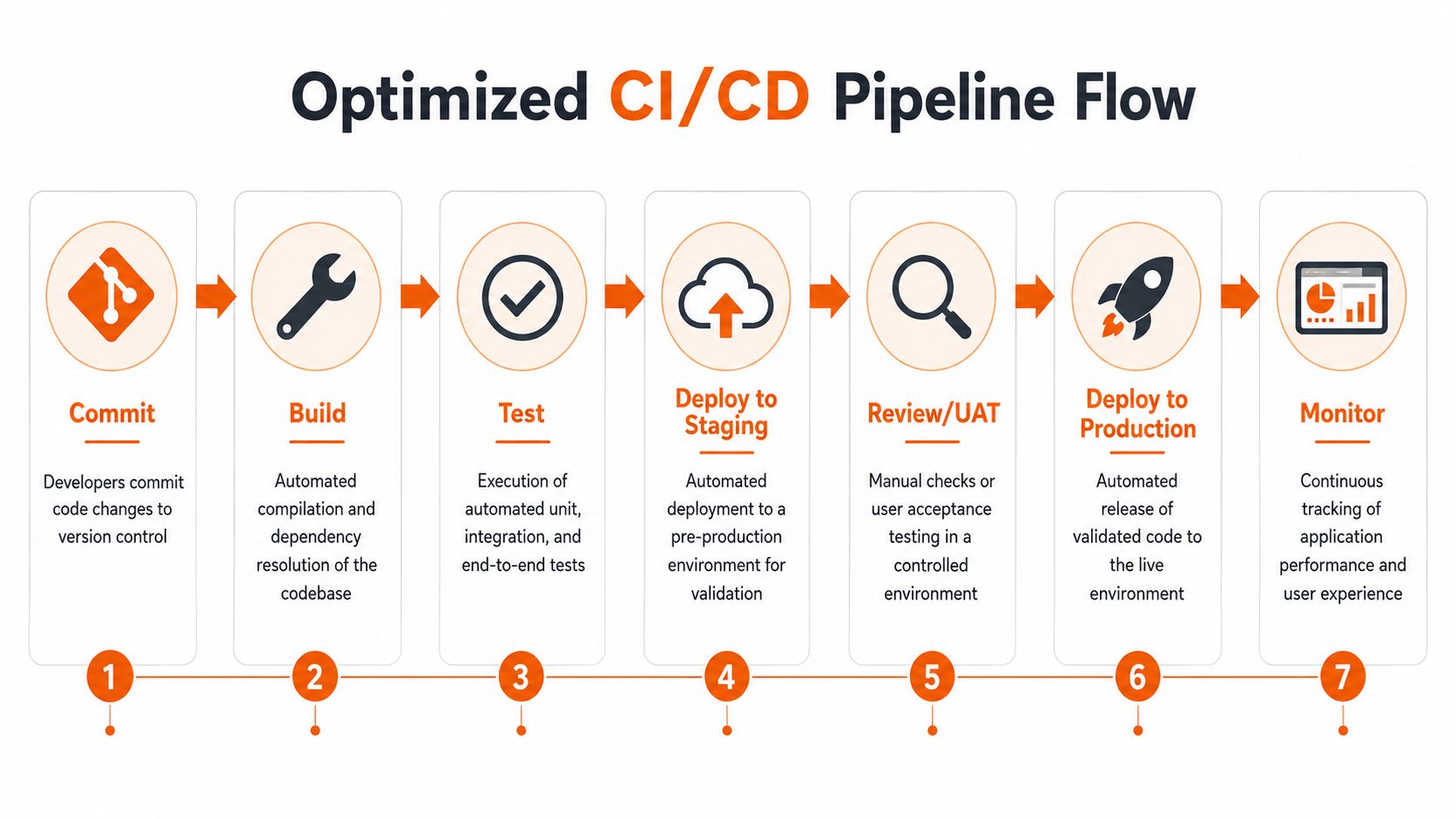
Shrink the batch, automate the path
Release friction usually comes from oversized changes and too many human checkpoints.
Fix that first. Push smaller changes. Run automated checks early. Remove approvals that exist only because nobody trusts the system. Production releases should feel routine because the path to production is tested constantly, not because engineers got better at heroic launches.
A practical reference point is continuous integration principles for faster, lower-risk delivery. High-performing teams use CI as a management discipline. It cuts feedback time, exposes defects earlier, and reduces the cost of change before work piles up.
A useful outside perspective is Prompt Builder on productivity strategies, especially if you want a practical checklist for common engineering slowdowns.
Close the permission gap
Tooling is only half the job. Leadership sets the ceiling.
Many engineers know exactly which pipeline issues are hurting throughput. They still avoid fixing them because roadmap pressure rewards visible feature output and treats system repair as a side task. That is the permission gap. It is one of the biggest reasons delivery systems stay broken.
Under the #riteway approach, Extreme Ownership applies to leaders first. If the pipeline is slow, unstable, or full of handoffs, leadership owns the conditions that allowed it. That means giving teams explicit cover to remove recurring friction, then holding them accountable for measurable improvements in lead time, failure rate, and recovery speed.
Set the rule clearly. Time spent removing repeat bottlenecks counts as product delivery because it improves the rate and reliability of future delivery.
Leadership move: reserve protected capacity for pipeline fixes every sprint, and require teams to show which source of delay they removed with it.
That can mean stabilising CI, removing an approval layer for low-risk changes, or fixing environment provisioning that burns hours every week. The point is not activity. The point is fewer queues, faster feedback, and smoother releases.
A short explainer on delivery habits can help ground this operationally:
What to fix first
Do not start with a broad transformation plan. Start where work waits.
- If pull requests sit untouched, set review SLAs, reduce reviewer count, and automate formatting, linting, and other low-value checks.
- If builds are slow, measure the longest stages, remove duplicated test runs, and parallelise only after you cut waste.
- If releases feel risky, reduce batch size, deploy more often, and standardise rollback steps.
- If environments keep blocking delivery, fix provisioning, permissions, and test data access before adding more ceremonies.
- If teams keep shipping around known friction, make that friction visible in business terms: hours lost, release delays, and opportunity cost.
The article's business angle matters. A slow pipeline is not just an engineering nuisance. It is a cost centre hiding inside delivery. The companies that improve fastest quantify that waste, assign ownership, and fix the system with the same urgency they apply to feature work.
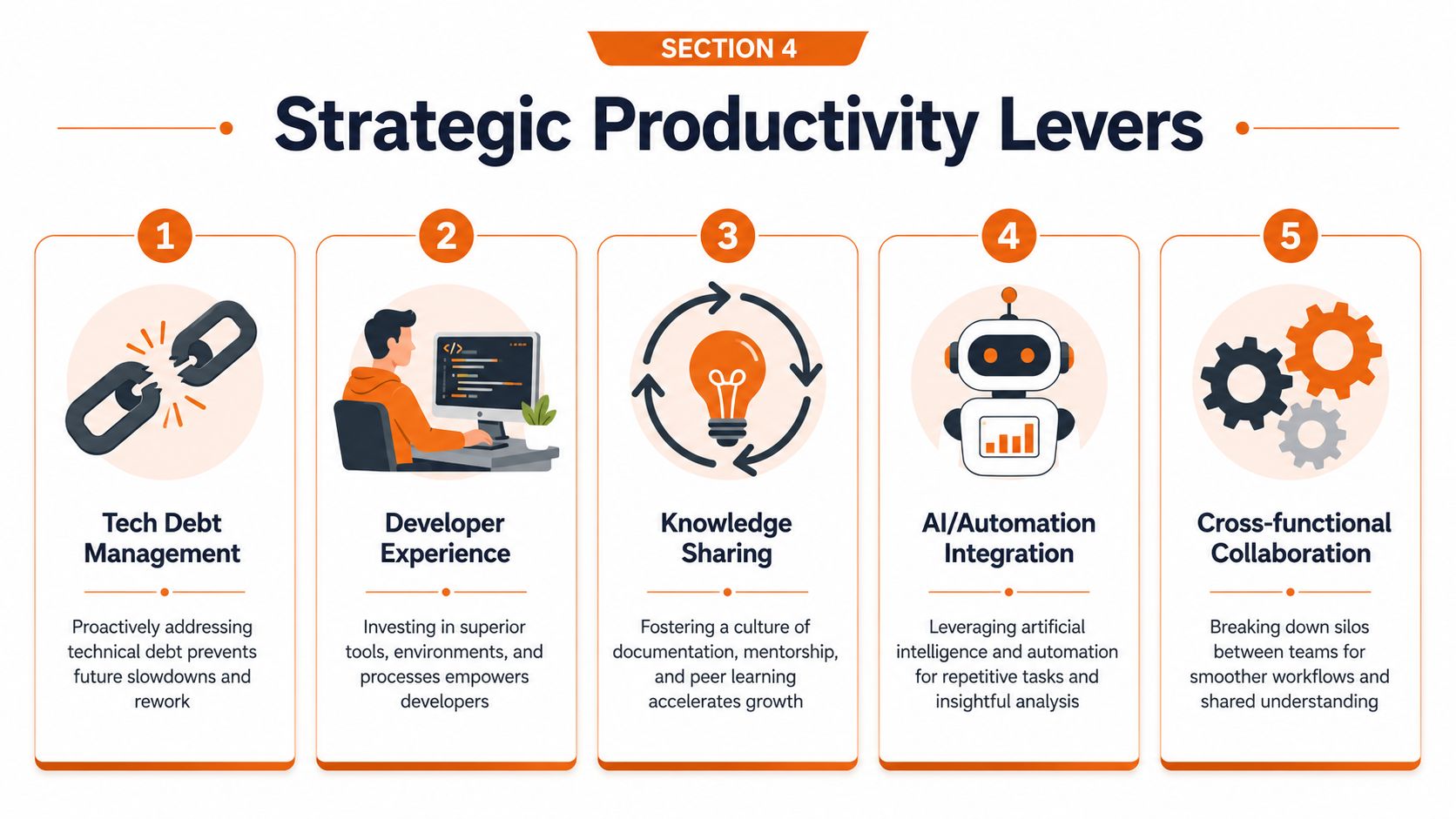
Amplify Your Impact with Strategic Levers
Teams hit a ceiling when they treat productivity as a local optimisation problem. You do not break through that ceiling with one more dashboard or a stricter standup. You break it by changing capacity, ownership, and the way work moves across the system.
Translate technical friction into business terms
If engineering cannot explain delay in financial terms, finance will treat it as a technical complaint.
Put a price on the bottleneck. Calculate wasted engineering hours, then add the revenue impact of slower releases, missed customer commitments, and deferred product bets. Use a simple formula your leadership team can challenge and still understand: salary cost of wasted time, multiplied across the team, plus the cost of delayed outcomes.
This is the permission gap. Leaders say they want faster delivery, but they keep funding visible feature work over invisible system fixes. Extreme Ownership closes that gap. The engineering leader names the cost, ties it to a business result, and asks for a decision. No waiting for someone else to bless the obvious.
Pull levers that change capacity
The highest-return moves usually sit above the sprint level. Team shape, sourcing model, and ownership design have more impact than marginal process tuning.
Nearshore senior teams
Use nearshore talent when hiring locally is too slow, too narrow, or too expensive for the delivery target in front of you. This only works if the team is senior enough to own outcomes, communicate directly, and work inside your cadence, standards, and product context. A cheap extension team creates handoffs. A senior integrated team increases throughput.
Build-Operate-Transfer
Use BOT when you need speed now and a durable capability later. It gives you a fast start without locking you into permanent dependency. The smart use case is expansion into a new engineering hub where you want early operational support, then full internal ownership once the model proves itself.
AI and workflow automation
Use AI to cut repetitive work and tighten feedback loops. Good use cases are documentation support, test generation, issue triage, incident pattern detection, and release risk signals. Bad use cases are novelty pilots that create noise, weak code, or extra review burden.
Rite NRG applies this model through dedicated teams, consulting, and Build-Operate-Transfer delivery. The point is not vendor substitution. The point is adding capacity with stronger operating discipline, clearer ownership, and less drag between decision and execution.
Match the lever to the real constraint
| Constraint | Better lever |
|---|---|
| Hiring is too slow | Nearshore senior team |
| You need a long-term delivery base | Build-Operate-Transfer |
| Engineers drown in repetitive work | AI and automation |
| Work gets blocked between functions | Cross-functional operating model |
Choose the lever that removes the most expensive constraint.
That means looking past headcount requests and asking a harder question. What is limiting delivery right now? If the answer is weak ownership, fragmented decision-making, or a team mix that cannot carry the load, fix that first. Strategic productivity work pays off when it increases value flow, reduces management drag, and gives the business a delivery system it can trust.
Your Continuous Improvement Playbook in Action
Engineering productivity does not improve because a dashboard exists. It improves when leadership turns friction into an operating problem with an owner, a deadline, and a business target.
Run that discipline on a fixed quarterly cadence. A month is too short for meaningful trend movement. A year is too slow and invites drift.
Use a connected set of metrics such as cycle time, defect rate, and deployment frequency. Pair them with a few leading signals inside the delivery path, like pre-merge check pass rates, review wait time, and failed release causes. Then review the pattern once a quarter and decide what to fix next.
A useful operating loop looks like this:
Review the baseline
Look at speed, quality, and recovery together. Find the point where work stalls, bounces, or comes back as rework.Choose one expensive constraint
Pick the bottleneck that is wasting the most time or delaying the most value. Long reviews, unstable environments, handoff delays, and oversized batches are common offenders.Name one accountable owner
One leader owns the result. That includes diagnosis, intervention, and follow-through.Make a focused change
Cut approval layers. Tighten work in progress limits. Shift status traffic to async updates. Add automation where it removes manual checking and shortens feedback loops.Measure the business effect
Check whether releases got easier, defects dropped, and customer-facing work reached production faster.
Many companies stall at this point. They can see the bottleneck, but nobody feels permitted to change the system around it. That permission gap is a leadership failure, not a tooling problem. The #riteway approach closes it with extreme ownership. If a queue is hurting delivery, someone owns fixing the queue. If a ritual creates drag, change the ritual. If a team shape cannot support the roadmap, redesign the team.
Keep the scope tight.
Broad productivity programs collapse under their own language. Small, owned interventions compound because teams can execute them fast and leaders can see whether they worked. That is how you build confidence in the system and trust with the business.
Use a few hard rules:
- Treat friction as an operating issue: remove blame and fix the condition causing the delay.
- Act before analysis turns into avoidance: if the bottleneck is obvious, start there.
- Build repeatable habits: stop rewarding rescue work caused by a weak system.
- Tie every fix to value flow: show what changed in release reliability, rework, or time to customer impact.
Start with the delay everyone complains about and nobody owns. That is usually the highest-return fix on the board.
Rite NRG applies this playbook through delivery consulting, dedicated teams, and Build-Operate-Transfer models. The point is practical: stronger ownership, clearer operating rhythm, and a delivery system the business can trust.

