


Your team ships a feature on Friday. Staging looked clean. Production breaks anyway.
The cause usually isn't the feature. It's the environment. A security rule changed by hand. A database setting nobody documented. A queue, subnet, secret, or service toggle that exists in one place and nowhere else. Your engineers lose the next week untangling infrastructure trivia instead of building product.
That's why infrastructure as code matters. Not as a DevOps slogan. As a delivery control system.
If you want faster MVPs, predictable releases, and fewer expensive surprises, stop treating infrastructure like a side activity handled through cloud-console clicks. Treat it like a product asset. Define it in code. Review it. test it. Deploy it through pipelines. Own it with the same discipline you expect from application delivery.
Stop Firefighting and Start Shipping Faster
Most CTOs don't have an infrastructure problem. They have a predictability problem.
When environments drift, delivery stops being reliable. Forecasts slip. Engineers waste time recreating issues. Incident calls get louder. Product leaders lose confidence because every release feels like a negotiation with hidden operational risk. If this sounds familiar, your infrastructure model is already costing you velocity.
Infrastructure as code fixes that by making your environments reproducible. Networks, servers, databases, permissions, and supporting services stop living in tribal knowledge and start living in machine-readable definitions. That change sounds technical. The impact is commercial. Teams ship with less hesitation because they know what's being deployed, where, and how.
This isn't niche anymore. One market projection puts the infrastructure as code market at USD 1.582 billion in 2026 and USD 6.94 billion by 2034 via Grand View Research's market outlook. The important point isn't the forecast itself. It's what the forecast tells you. Serious software businesses now treat infrastructure automation as standard operating capability.
Why the firefighting never stops
Manual infrastructure creates three leadership headaches fast:
- Delivery dates become soft promises because environment readiness depends on people remembering hidden steps.
- Incidents take longer to resolve because nobody has a reliable baseline for what changed.
- Scaling multiplies chaos because every new region, client environment, or stage adds another chance for inconsistency.
Practical rule: If production can differ from staging because somebody clicked something manually, your release process isn't under control.
The fastest way out is to make infrastructure changes reviewable and repeatable, then tie them into operational discipline. That's also why strong release controls need equally strong runbooks and escalation paths. If your incident process is still reactive, tighten that up alongside your platform model with clearer incident response procedures for engineering teams.
What changes when you codify infrastructure
You stop relying on memory. You start relying on a system.
That shift gives you a cleaner path to faster launches, safer changes, and less drama between engineering, product, and operations. It also aligns with the #riteway mindset. Ownership over excuses. Proactivity over recovery. Good teams don't wait for infrastructure inconsistency to hurt delivery. They remove the condition that causes it.
Treating Your Infrastructure Like Software
The simplest way to understand infrastructure as code is this. Your cloud estate should follow the same rules as your application code.
You already expect application changes to live in Git, go through review, and move through controlled deployment. Your infrastructure should work the same way. If it doesn't, your application process is disciplined on the surface and fragile underneath.
A useful analogy is a kitchen. A chef cooking from memory might produce something brilliant once, then struggle to reproduce it exactly under pressure. A written recipe changes that. Anyone competent can follow it, refine it, review it, and repeat it. Infrastructure as code is that recipe for your platform.
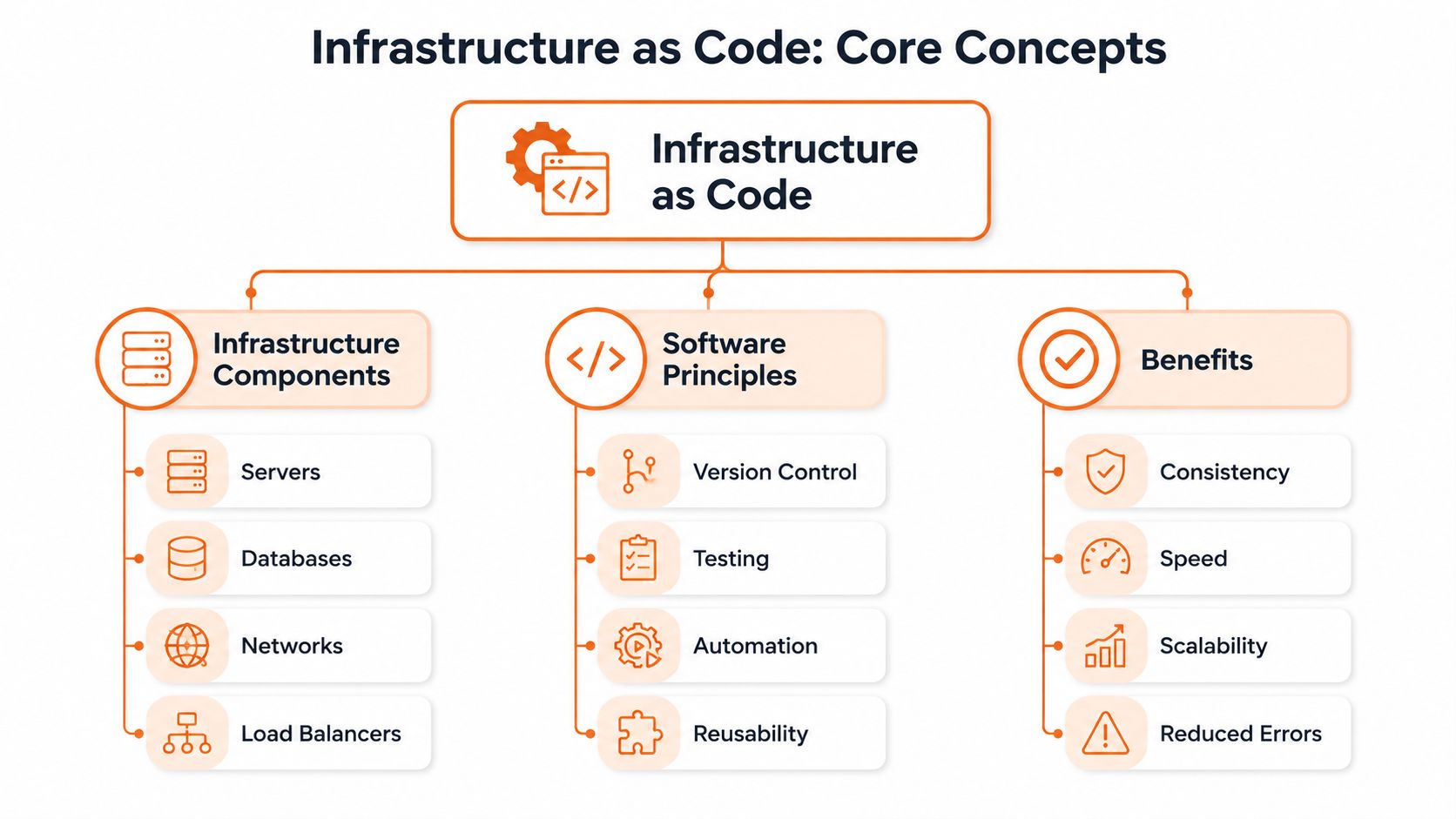
What gets defined in code
You're not just scripting servers. You're defining the shape of the environment your product runs on.
That often includes:
- Compute resources such as virtual machines, containers, and managed runtime services
- Data services like databases, storage, and backups
- Networking including subnets, routing, load balancers, and firewall rules
- Access controls for roles, permissions, and service identities
Once those definitions live in code, engineers can work with infrastructure in a controlled way instead of relying on memory, screenshots, and one-off admin actions.
Why version control changes everything
IBM's guidance is the key operational point here. With infrastructure as code, infrastructure changes become versioned, reviewable artefacts because the files live in version control, which makes them easier to track, review, and roll back through IBM's explanation of infrastructure as code.
That matters more than many teams realise.
A version-controlled infrastructure change gives you:
| Benefit | What it means for delivery |
|---|---|
| Traceability | You can see who changed what and why |
| Reviewability | Peers can catch risky changes before they hit production |
| Rollback | You can revert infrastructure logic without improvising |
| Auditability | Git history and pipeline records become evidence, not guesswork |
Infrastructure that lives outside version control becomes operational folklore. That is not a scalable model.
What leaders should insist on
If you're leading engineering, don't accept partial adoption dressed up as automation.
Require these basics:
- All core environments are defined in code. Dev, test, staging, and production should not depend on undocumented manual steps.
- Infrastructure changes go through pull requests. No direct console edits unless there's a controlled emergency path.
- Every change leaves evidence. Commit history, approvals, and deployment logs should tell the story clearly.
That's the foundation of predictable delivery. Without it, teams may move fast for a sprint or two, but they won't scale cleanly.
Choosing Your IaC Strategy and Toolset
Tool selection matters, but strategy matters more.
Too many teams start with “Should we use Terraform, CloudFormation, or Bicep?” That's the wrong opening move. Start with the operating model you want, then choose the toolset that supports it. If your goal is speed with control, your infrastructure as code approach needs to favour clarity, repeatability, and low blast radius.
Declarative beats imperative for most SaaS teams
There are two broad ways to approach infrastructure automation.
Imperative means writing the steps to achieve an outcome.
Declarative means defining the desired end state and letting the tool reconcile to it.
For most SaaS businesses, declarative wins. Your team doesn't need more handcrafted deployment logic. It needs cleaner intent, easier review, and less room for hidden side effects. That's why tools such as Terraform, AWS CloudFormation, and Azure Bicep tend to be the practical choice for platform teams that care about maintainability.
The better question is fit, not features
Use this lens:
| Situation | Better fit |
|---|---|
| Single-cloud AWS team | CloudFormation may work well if you want tight AWS alignment |
| Single-cloud Azure team | Bicep is often a clean choice for Azure-native delivery |
| Multi-cloud or portability goals | Terraform is commonly the more flexible option |
| Strong platform governance needs | Prioritise modularity and policy enforcement over novelty |
The mistake is chasing the “best” tool in abstract. There isn't one. There's only the tool that best matches your cloud strategy, team capability, and governance expectations.
Modular composition is where scale becomes manageable
The bigger delivery decision is structure. A weakly organised codebase will slow you down regardless of tool choice.
Puppet's guidance is useful here. A key pattern for scaling infrastructure as code in UK engineering teams is using declarative tools with modular composition, splitting infrastructure into reusable modules to reduce drift and lower the blast radius of changes, as outlined in Puppet's write-up on infrastructure as code patterns.
That should shape your architecture.
Build reusable modules for things like:
- Networking baselines that standardise routes, boundaries, and core policies
- Database patterns with approved defaults for resilience and access
- Application stack templates that teams can instantiate without reinventing everything
- Environment wrappers so dev, staging, and production stay aligned without becoming identical in the wrong ways
Recommendations that hold up under pressure
If I'm advising a CTO, I'd push these decisions hard:
- Choose declarative unless you have a very specific reason not to. Organizations benefit from less custom orchestration, not more.
- Standardise modules early. Don't let every squad invent its own VPC, secret pattern, or service baseline.
- Optimise for readability. Infrastructure code is an operating asset. If only one engineer understands it, it's already a risk.
- Avoid a tool sprawl trap. One primary provisioning model is usually enough. Complexity doesn't prove maturity.
Good infrastructure as code doesn't just provision resources. It reduces decision fatigue and increases delivery confidence.
Build Your Environments Automatically with CI/CD
A repository full of infrastructure code is a start. It's not the win.
The true advantage of infrastructure as code becomes evident when it is integrated into CI/CD, and every environment move becomes part of an automated, visible delivery flow. That's when “environment not ready” stops being a weekly excuse and starts becoming a solved problem.
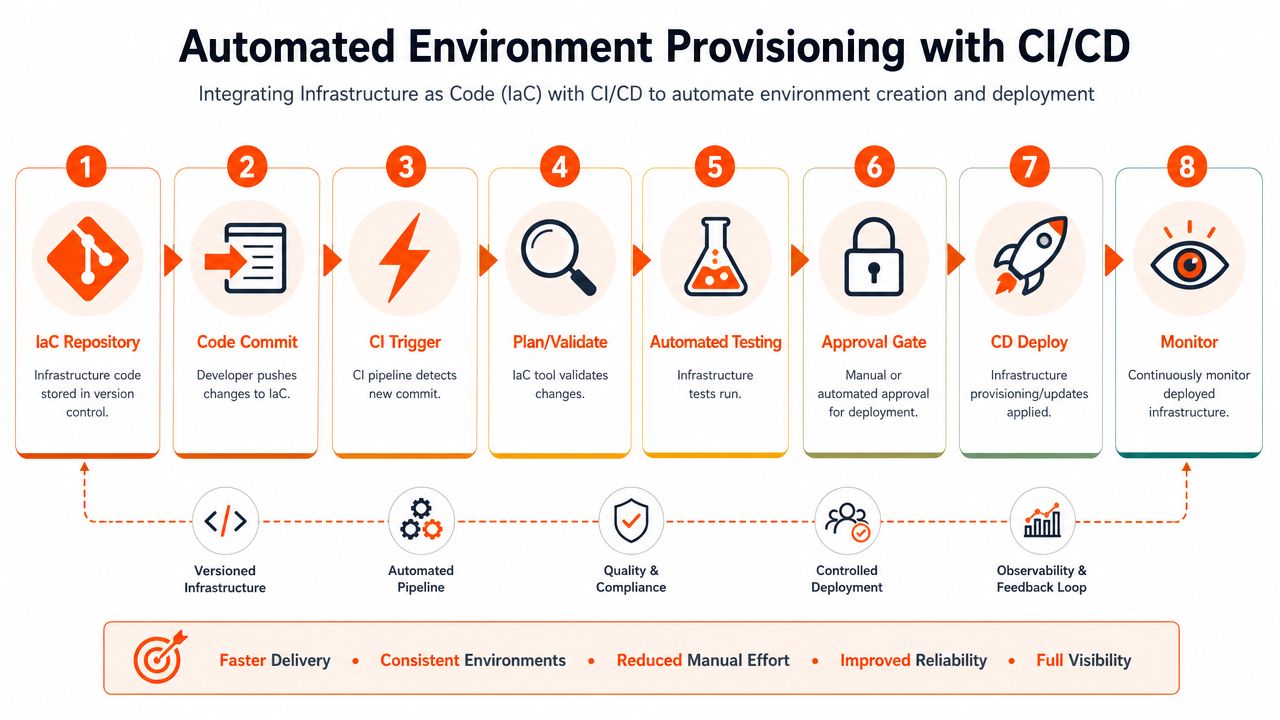
What the pipeline should do
A strong pipeline doesn't just run application tests. It validates and controls infrastructure changes before they become production risk.
A practical flow looks like this:
- A developer commits a change to the infrastructure repository.
- The pipeline validates syntax and structure so bad definitions fail early.
- A plan step shows the impact before anything is applied.
- Automated checks run against security, policy, and configuration rules.
- An approval gate enforces control where production sensitivity demands it.
- Deployment applies changes consistently across the target environment.
- Monitoring confirms the result and creates an evidence trail.
That's not bureaucracy. It's velocity insurance.
For teams still maturing this muscle, tightening your continuous integration practice for software delivery is the right companion move. If app code and infra code follow different quality standards, your pipeline will bottleneck somewhere.
Here's a useful explainer on the broader delivery pattern:
Business outcomes you should expect
When CI/CD provisions and updates environments automatically, several blockers disappear.
- Developers get faster feedback because test environments can be created or updated without waiting on ops handoffs.
- Release coordination gets simpler because the pipeline becomes the standard path instead of ad hoc team rituals.
- Production changes get safer because every step is visible, repeatable, and easier to review.
Build environments through the same system every time. If your process depends on who is online, it isn't mature enough.
Where teams go wrong
The common failure mode is automating only the last step. They script deployment, but not governance, validation, or evidence. That still leaves a brittle delivery chain.
Avoid these traps:
- Skipping plan visibility and applying changes engineers haven't reviewed properly
- Mixing manual production steps into an otherwise automated release path
- Treating non-production environments as disposable chaos instead of a proving ground for release quality
- Ignoring monitoring after apply and assuming deployment success equals operational success
The point of CI/CD with infrastructure as code is not just automation. It's controlled acceleration. That's what creates predictable MVP delivery and more reliable product release cadence.
Embedding Security and Testing into Your Code
The wrong way to think about security is as a brake pedal.
Security should be part of how infrastructure gets designed, reviewed, and deployed from the start. If your team adds it at the end, speed drops and risk still leaks through. Infrastructure as code gives you a better option. It lets you move security controls left, into the codebase and pipeline where they belong.

Governance is the real maturity test
Plenty of teams can provision cloud resources. Far fewer can prove those resources are controlled.
That's the gap that matters. The UK National Cyber Security Centre warns that secure-by-default configuration and automated controls are essential because misconfiguration remains a major threat, as summarised in Harness's discussion of infrastructure as code governance. The strategic takeaway is simple. Provisioning alone isn't enough. You need continuous proof of compliance and control.
What to build into the workflow
A disciplined setup usually includes:
- Static checks before merge so risky patterns get caught in pull requests, not in production
- Policy-as-code rules that block non-compliant resources from being created
- Automated test stages for infrastructure modules and environment definitions
- Evidence generation through pipeline logs, approvals, and version history
Security teams want confidence. Engineers want flow. This gives both sides what they need.
Operating principle: Don't ask whether a change was secure after deployment. Design the pipeline so insecure changes don't pass.
The practical leadership stance
If you're responsible for delivery, insist on these behaviours:
| Control area | What good looks like |
|---|---|
| Defaults | Secure baselines are baked into shared modules |
| Approvals | Sensitive changes require defined review paths |
| Segregation of duties | No single actor can quietly push risky infra changes |
| Evidence | Git, CI logs, and policy checks show what happened |
That's where the #riteway mindset matters. Extreme Ownership means the team doesn't wait for audit season or a security incident to discover missing controls. It builds governance into the delivery system up front.
If your wider engineering lifecycle still treats security as a late-stage review, fix that next with a stronger security approach in the software development life cycle. Infrastructure as code works best when the whole SDLC shares the same discipline.
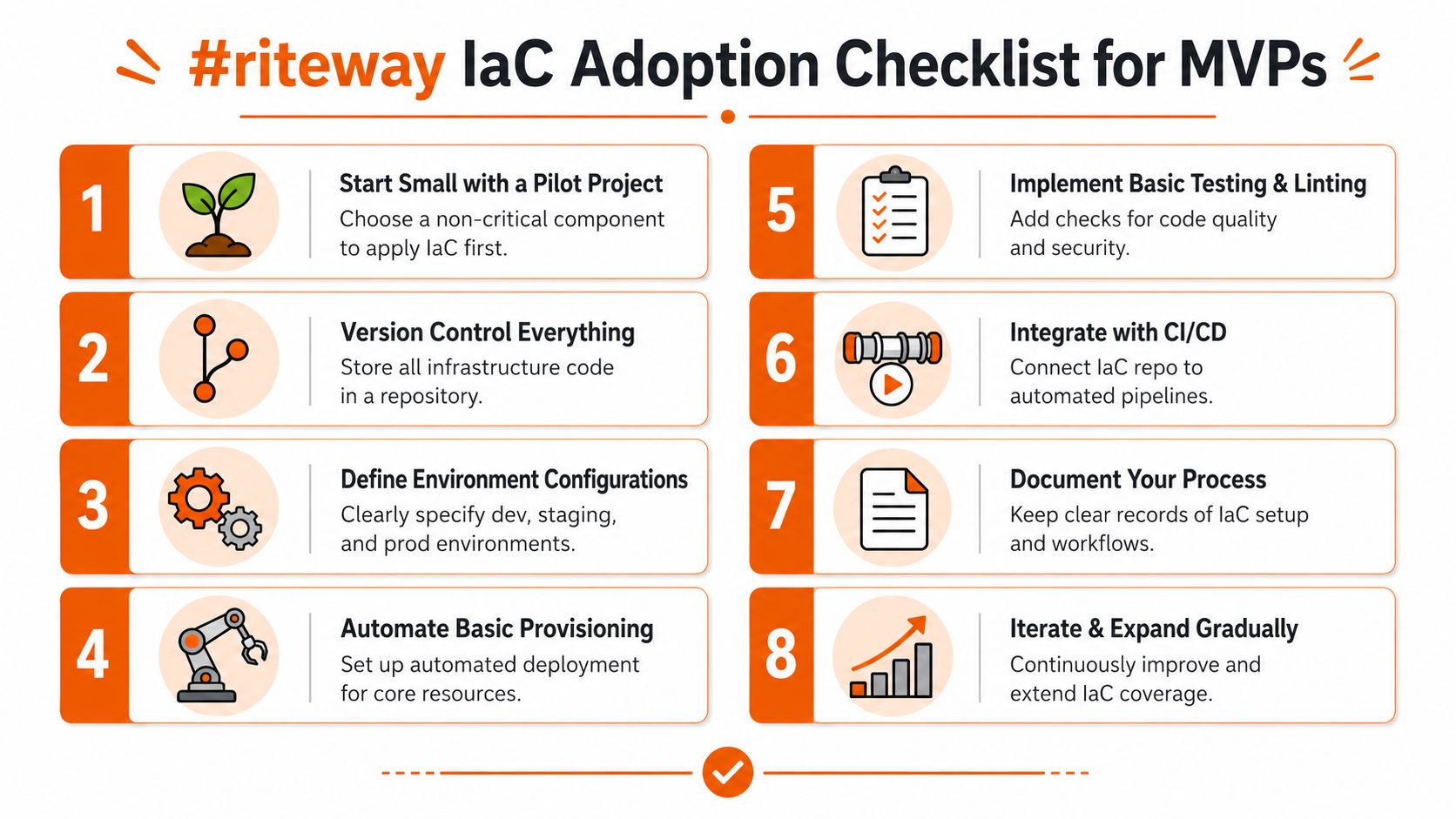
The #riteway IaC Adoption Checklist for MVPs
Organizations often overcomplicate adoption. They treat infrastructure as code like a transformation programme when it should start as an execution discipline.
For MVP delivery, the right move is narrower and sharper. Pick a bounded scope. Define success clearly. Build repeatability fast. Expand only after the team has proven ownership and control.
The UK context makes this more urgent, not less. The cloud computing industry generated about £7.8 billion in turnover in 2021 in the UK, according to the market context cited by Fortune Business Insights on infrastructure as code. In a cloud market of that scale, reproducible infrastructure across development, testing, and production isn't an advanced extra. It's basic operational competence.
A practical checklist that leaders can enforce
Here's the model I'd use for an MVP-stage product team.
Start with one non-critical service
Don't begin with your most tangled production estate. Choose a contained workload where the team can prove the model without paralysing delivery.Put everything in version control
Infrastructure definitions, environment variables strategy, module structure, and change history all need one visible home.Define environment boundaries early
Teams get into trouble when dev, staging, and production are vague copies of each other. Set the shape and purpose of each environment before you automate heavily.
The #riteway difference in execution
A high-energy, ownership-led approach looks like this:
- Set one business metric first such as time to provision a test environment or change failure visibility
- Codify shared modules early so engineers don't produce inconsistent patterns under sprint pressure
- Make reviews mandatory because speed without review just scales mistakes
- Mentor while building so adoption becomes a team capability, not dependency on a few specialists
That's the point many organisations miss. Tools don't create maturity. Team behaviour does.
Strong infrastructure as code adoption isn't about writing more files. It's about removing uncertainty from delivery.
What not to do
Avoid the common startup mistakes:
- Don't codify chaos. If your current setup is messy, simplify the architecture before you automate all of it.
- Don't chase full coverage on day one. Partial but disciplined adoption beats broad and inconsistent adoption.
- Don't separate platform work from product urgency. MVPs need speed, but speed comes from stable foundations, not shortcuts.
The #riteway principle is straightforward. Own the outcome. Be proactive. Build systems that make good delivery easier by default.
Your Infrastructure as Code Questions Answered
Leaders usually ask the same few questions before they commit. They're the right questions.
Is infrastructure as code worth it for an early-stage SaaS?
Yes, if you expect to grow beyond a single engineer manually managing cloud resources.
The earlier value is not enterprise-scale sophistication. It's baseline consistency. Even a lean product team benefits when environments are reproducible, infrastructure changes are visible, and releases stop depending on memory.
Do we need it if we're only on one cloud provider?
Probably yes.
Single-cloud doesn't mean simple forever. You still need repeatability, reviewability, and controlled change. Native tools can work well in single-cloud setups if they fit your team and governance model.
Will infrastructure as code slow us down at the start?
Bad implementation will. Good implementation won't.
If the team creates overengineered abstractions, too many modules, or heavyweight approvals too early, delivery will drag. If it starts with a narrow, practical scope, it usually removes friction quickly because environment setup and change management stop being manual bottlenecks.
What should we measure?
Measure the things that reveal operational maturity, not vanity.
AWS's DevOps guidance frames useful indicators such as infrastructure code coverage, configuration drift rate, and time to provision infrastructure. Those are strong leadership metrics because they show whether your team is standardising and controlling infrastructure, rather than just automating pieces of it qualitatively.
Can infrastructure as code increase cloud waste?
Yes.
That's one of the most under-discussed issues. If teams codify oversized defaults, duplicate environments, or leave non-production stacks running without discipline, automation can lock in waste faster. Good infrastructure as code needs FinOps thinking and clear ownership, not just provisioning speed.
What's the first move if we're doing this now?
Use this order:
- Pick one environment or service boundary
- Choose one primary toolset
- Put all changes through version control
- Add validation and review before apply
- Connect it to CI/CD
- Expand only after the team proves control
That sequence works because it builds capability without creating platform theatre.
What's the biggest mistake CTOs make?
They treat infrastructure as code like a tooling decision when it's really an operating model decision.
The hard part isn't writing templates. The hard part is enforcing ownership, review discipline, module standards, and release controls consistently. Once that clicks, infrastructure as code stops being a DevOps initiative and becomes a delivery advantage.
If you want a senior delivery partner to help your team implement infrastructure as code without slowing product momentum, talk to Rite NRG. They help SaaS companies build predictable delivery systems with senior nearshore engineers, product-first thinking, and the #riteway mindset of ownership, proactivity, and fast execution.
