


Software project risk management isn't about creating lists of what could go wrong. It's an energetic, proactive discipline for identifying, assessing, and neutralizing threats that could derail your project's timeline, budget, and most importantly, the business outcomes you're targeting.
The real game-changer is shifting from a defensive, box-ticking exercise to an offensive strategy. This isn't just about avoiding failure; it's about leveraging risk awareness to accelerate delivery, make smarter decisions, and guarantee you ship a product that delivers real-world value.
Why Your Risk Management Strategy Is Probably Broken
Let's be brutally honest for a moment. Most software project risk management feels like a soul-crushing bureaucratic exercise that spits out documents no one ever looks at again. This old-school, checklist-driven approach creates a dangerous illusion of security. It's precisely what leads to the budget blowouts and missed deadlines that are all too common in the software world.

It’s time to stop playing defense and start using risk as an offensive strategy to win. The goal isn’t to create some mythical, risk-free plan. It’s about building resilience and momentum into your project, enabling your team to make intelligent trade-offs that drive you toward your business goals, faster.
"A consulting mindset transforms risk management from a box-ticking exercise into a strategic conversation. It’s about asking ‘what could stop us from delivering value to our customers?’ and then taking Extreme Ownership of the answer."
This guide will walk you through the #riteway methodology—a proactive, high-ownership framework that turns risk management from a passive activity into a powerful tool for accelerating your MVP. We'll show you exactly how a consulting mindset, paired with high-energy, genuinely senior teams, ensures your project doesn't just survive—it delivers exceptional business value.
The Staggering Cost of Ignoring Risk Management
When risk management is an afterthought, the consequences are both predictable and painful. Projects lurch from one unforeseen fire to the next, incinerating cash and team morale along the way. This kind of reactive firefighting is the absolute enemy of predictable value delivery and sustainable growth.
The numbers paint a pretty grim picture here in the UK. Project failure rates tell a stark story, with data showing that only a measly 10% of large software projects (those over $10 million) are successful. A staggering 38% fail completely. Compare that to smaller projects under $1 million, where 76% succeed and just 4% fail.
Even more telling? High-maturity UK organisations—the ones that put risk management front and centre—hit their deadlines 67% of the time, compared to just 30% for everyone else. If you're interested in the details, you can learn more about these technology risk trends and how they crush project success.
Shifting from Defence to Offence
This is where a fresh perspective makes all the difference. An outcome-driven approach reframes the entire conversation. We’ve seen firsthand how the right team, armed with a proactive and energetic "can-do" attitude, turns risk management into a genuine competitive advantage. It's not about trying to avoid all risks; it's about deliberately choosing which risks are worth taking to smash your business goals faster.
This shift in thinking really comes down to a few key principles from the #riteway methodology:
- Focus Relentlessly on Business Value: Every single risk discussion has to tie back directly to a business outcome. Will this risk delay our MVP launch? Could it tank user adoption?
- Embrace Extreme Ownership: Instead of pointing fingers, our teams own the problems and the solutions. This creates a culture where risks are flagged early and tackled head-on with unstoppable energy.
- Think Like a Consultant: We act as your strategic partner, offering solid advice on technology and delivery. That means we'll challenge your assumptions and spot the hidden risks you might not see coming.
- Bring Proactive Energy: We don't sit around waiting for risks to morph into full-blown issues. We actively hunt for them, discuss them with complete transparency, and build mitigation plans right into our sprints.
Traditional vs Outcome-Driven Risk Management
The difference between a passive, checklist-based process and an active, value-focused one is night and day. One creates paperwork; the other creates momentum.
| Characteristic | Traditional Approach (The Problem) | Our #riteway Approach (The Solution) |
|---|---|---|
| Mindset | Defensive & Reactive ("Cover our backs") | Offensive & Proactive ("Clear the path to value") |
| Focus | Process compliance and documentation | Business outcomes and MVP acceleration |
| Ownership | Siloed or assigned to a single PM | Collective "Extreme Ownership" by the entire team |
| Goal | Risk avoidance and creating a perfect plan | Building resilience and intelligent risk-taking |
| Communication | Formal reports, often after the fact | Continuous, transparent conversation in daily stand-ups |
| Output | A static risk register nobody reads | An active, living backlog of mitigation tasks |
Embracing an outcome-driven approach is how you move from a state of constant, low-grade anxiety to one of confident control. It ensures your project's momentum stays high and your path to market remains clear.
Building Your Risk Radar to Spot Threats Early
Effective risk management isn’t about sitting around waiting for alarms to go off. It’s about building a powerful, always-on radar system that spots trouble long before it can impact your business outcomes. Forget those tired, generic brainstorming sessions. To get ahead, you have to think and act like a strategic partner, actively hunting for the hidden assumptions and silent weaknesses that can completely derail your project.
This is where the high energy of a proactive team truly shines. Instead of just passively documenting risks, we challenge the very foundations of the project plan. This approach once helped us uncover a critical scalability bottleneck in an MVP’s architecture months before it would have forced a costly, time-consuming refactor—saving the client six figures and protecting their launch date. That’s the kind of tangible business value you get from a sharp, effective risk radar.
Uncovering Hidden Dangers with Assumption Analysis
Every single software project is built on a mountain of assumptions. We assume a new API will be reliable. We assume user adoption will hit projections. We assume cloud infrastructure costs will stay within budget. Most of the time, these beliefs are unstated and unexamined—right up until they explode into a crisis that threatens your business goals.
Assumption Analysis is a deceptively simple but incredibly potent technique for dragging these hidden risks into the open. It's all about systematically identifying and questioning the core beliefs your project's success is riding on. The process itself is straightforward, but it demands a culture of open inquiry and what we call "Extreme Ownership."
Get your team together and start asking some powerful questions:
- What absolutely must be true for this project to deliver its intended business value? This unearths dependencies on everything from market conditions to specific user behaviours.
- Which of these beliefs has the least evidence to back it up? This is brilliant for separating educated guesses from pure guesswork.
- What happens to our business goals if this assumption turns out to be false? This immediately connects a flawed assumption to a concrete business impact, like a missed revenue target.
By turning these unverified beliefs into documented risks, you can start building contingency plans that protect your investment before you've even written a single line of code.
Conducting a Premortem to Foresee Failure
Another fantastic technique we rely on is the Premortem Exercise. It’s a powerful psychological trick: instead of asking, "What might go wrong?", you flip the entire conversation on its head.
Picture this: it's six months from now. The project has failed spectacularly. It's way over budget, hopelessly behind schedule, and customers absolutely hate it. Now, as a team, work backwards and write down every single reason why it failed.
This simple reframing gives your team the psychological safety to voice concerns without feeling like they're being negative. It cuts through office politics and encourages brutally honest feedback. When you treat failure as a certainty, the real, tangible reasons for it suddenly become crystal clear.
You might uncover risks you never would have thought of, like:
- "Our key front-end developer quit because the scope kept changing, and we had no one to back them up."
- "Our main competitor launched a similar feature three months ahead of us because our decision-making process was painfully slow."
- "The user interface worked, technically, but it was so confusing that our initial testers just gave up, torpedoing our adoption metrics."
A premortem isn’t about being pessimistic; it’s about smart, proactive problem-solving. It's a high-energy, collaborative way to identify dozens of potential failure points that would never see the light of day in a standard risk workshop. This isn't just theory; it's a core part of a proactive software project risk management strategy that ensures you're prepared for the worst while driving for the absolute best outcome. These methods give you a consultant's toolkit for finding risks across your technology, team, and market, putting you miles ahead of the game.
Sizing Up Your Risks: Prioritizing for Maximum Business Impact
Right, you've got your list of potential project-killers. What now? This is where many teams stumble. They end up with a sprawling spreadsheet of anxieties, and suddenly, a minor UI glitch gets the same panicked attention as a potential data breach. It's chaos.
This is where you need to switch gears from just listing problems to actually quantifying their impact on your business. A proactive team with a consulting mindset doesn't just collect risks; they get ruthless about prioritizing them. They ask one simple, powerful question: "How much could this actually hurt our business goals?" We're talking about tangible things like your time-to-market, revenue, and customer trust. It’s all about cutting through the noise to focus on what will genuinely make or break your project.
From Chaos to Clarity with a Risk Heatmap
Honestly, the best tool for this isn't some ridiculously complex formula. It's a simple, visual powerhouse: the risk matrix, or as it's more commonly known, a risk heatmap. Think of it less as a chart and more as a communication tool that turns a messy list of worries into a crystal-clear, data-driven plan of attack.
The idea is brilliantly straightforward. You score every risk you've identified along two critical axes:
- Likelihood: How probable is it that this will actually happen? (Usually a 1-5 scale, from "highly unlikely" to "almost certain").
- Business Impact: If it does happen, how bad is the damage to our business outcomes? (Again, 1-5, from "barely a blip" to "catastrophic failure").
You then multiply these two scores to get a priority number. Any risk with a high score—say, something with a high likelihood and a high impact—lands squarely in the "red zone" of your heatmap. These are the fire-breathing dragons you have to deal with right now. The stuff in the yellow and green zones? Still on your radar, but they don't demand the same all-hands-on-deck urgency.
This simple exercise forces you to stop treating every problem as a five-alarm fire and start pointing your team's valuable energy where it will have the biggest effect. The diagram below shows how you get to this point, starting with uncovering your assumptions and ending with pinpointing the weaknesses you'll plot on your map.
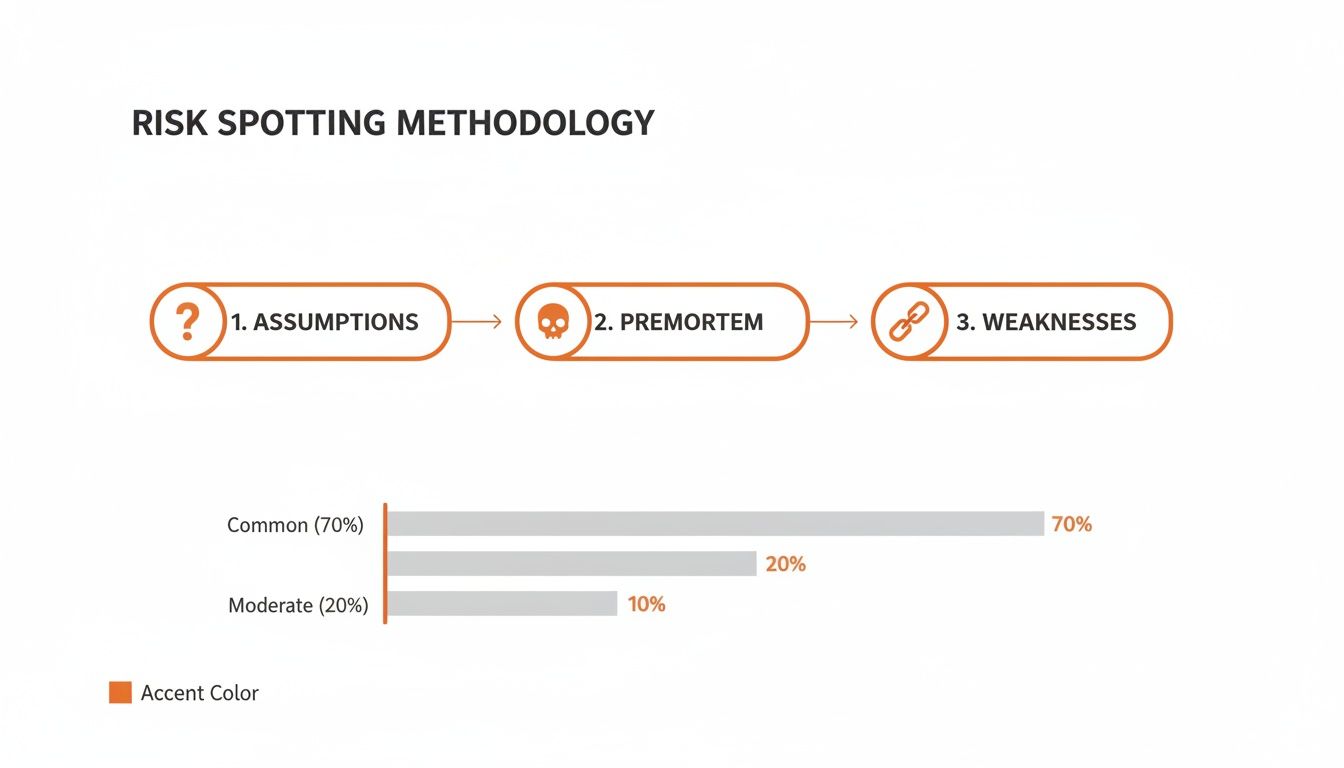
As you can see, this isn't just guesswork. Running exercises like a premortem (where you imagine the project has already failed and work backwards to find out why) is a fantastic way to uncover the hidden weaknesses that need assessing.
Putting the Risk Matrix into Action
Let’s make this real. Imagine you're in a sprint planning meeting for a new SaaS MVP. The team has flagged a bunch of potential risks, but without a clear way to prioritise them, everyone's paralysed. They don't know where to start.
This is where you pull out the heatmap and bring instant clarity.
The real magic of a risk heatmap is that it forces an objective conversation about business impact. It shifts the discussion from a vague, "I'm worried about this," to a concrete, "This specific risk has a 75% chance of delaying our launch by a month, costing us £50,000 in projected revenue." Now that's a conversation that gets people moving.
Let's look at a practical example of how this helps prioritise.
Sample Risk Assessment Matrix for a SaaS MVP
Here’s a snapshot of what this might look like for an early-stage software product. It’s a simple table, but it immediately shows the team where the real dangers are lurking.
| Risk Category | Example Risk | Likelihood (1-5) | Business Impact (1-5) | Priority Score |
|---|---|---|---|---|
| Technical Risk | The chosen database has known scalability issues that could cause outages past 1,000 users. | 2 | 5 | 10 |
| External Dependency | The third-party payment gateway API has unclear documentation, slowing down integration. | 4 | 2 | 8 |
| Team/Resource Risk | The sole back-end developer is a single point of failure and has no documented processes. | 3 | 4 | 12 |
| Security Risk | User authentication flow has a potential vulnerability that wasn't fully tested. | 2 | 5 | 10 |
| Market Risk | A key competitor might launch a similar feature set before our MVP is released. | 3 | 3 | 9 |
Looking at this table, the team can immediately see that while the payment gateway (Priority Score 8) is an immediate frustration, the single point of failure in the back-end team (Priority Score 12) is a much bigger strategic threat to their ability to deliver. Without this matrix, the developers might have spent all their energy on the more immediate, but far less critical, API problem.
This structured approach is what software project risk management is all about. You’re moving from a reactive state of fighting fires to one of strategic, proactive control. For a deeper dive into protecting your systems, it's also worth reading our guide on the importance of a comprehensive information technology security audit.
Creating Your Actionable Risk Mitigation Playbook

Spotting and ranking risks is a fantastic first step, but it’s just that—a start. The real magic in software project risk management happens next. This is where high-energy, proactive teams leave everyone else in the dust, turning a simple list of potential problems into a concrete, hands-on playbook for action.
This isn’t about creating more documents that just sit there gathering digital dust. It’s about building a live, tactical guide that your team actually uses every single day to neutralize threats before they can impact business value. The goal is to weave risk mitigation right into the fabric of your delivery process, making it a natural reflex, not some bureaucratic chore.
It all comes down to a mindset of Extreme Ownership. The team doesn't just flag risks; they own the solutions. We’re moving beyond pointing fingers and channeling all that energy into creating predictable, successful outcomes that keep your project on the fast track to launch.
The Four Core Mitigation Strategies
Right, so you’ve got your risks prioritized on a heatmap. Now what? You need a solid framework for deciding how to tackle each one. There are four main strategies, and picking the right one is all about understanding the specific risk and its potential impact on the business. Let's break them down with some real-world scenarios you can actually use.
- Avoid: This is your knockout punch. You change the plan to eliminate the risk entirely. It’s the most decisive action you can take.
- Transfer: This strategy is about shifting the financial or operational fallout of a risk onto a third party. Think of it as outsourcing the headache.
- Mitigate: This is the most common play. You take specific, targeted actions to reduce either the chance of the risk happening or the damage it would cause if it did.
- Accept: Let’s be honest—sometimes, the cost of dealing with a risk is way more than the potential damage. In these cases, you make a conscious call to do nothing and simply accept the consequences if it happens.
Each of these has its place in a killer playbook. The trick is to choose your response deliberately, not just react when the chaos hits.
Putting Strategies into Practice
Theory is one thing, but action is what counts. Here’s what these strategies look like in the real world of a fast-moving SaaS project, where speed and business value are everything.
1. Avoiding Scope Creep to Nail a Launch Date
Imagine your MVP is being threatened by a seriously complex, time-sucking feature. The risk? It's going to push your launch back by two months, letting a competitor swoop in and steal your thunder, destroying your first-mover advantage.
- Strategy: Avoid
- Action: You take Extreme Ownership of that launch date. After a frank and open discussion, the team decides to radically simplify the feature for the V1 release. All the fancy, complex bits get pushed to a later update. Just like that, you've completely eliminated the schedule risk and protected the business outcome of hitting that critical market window.
2. Transferring Compliance Risk with a Trusted Partner
Your new platform needs to handle online payments, which brings a whole world of PCI compliance and security risks. One tiny mistake could lead to colossal fines and a PR nightmare, vaporizing customer trust.
- Strategy: Transfer
- Action: Instead of trying to build a payment processing system from scratch (a massive undertaking), you integrate with a trusted, fully compliant third-party provider like Stripe or Adyen. Boom. You’ve just transferred the bulk of that compliance burden to an expert, freeing up your team to focus on building your amazing core product.
A core principle of effective software project risk management is knowing when not to build something yourself. Transferring risk to specialised partners isn't a sign of weakness; it's a mark of strategic focus and smart resource allocation.
3. Mitigating Hiring Delays with Nearshoring
You've flagged a critical risk: finding and onboarding two senior back-end developers in your local market could take a painful three months, creating a massive project bottleneck that puts your entire roadmap in jeopardy.
- Strategy: Mitigate
- Action: You bring in a strategic nearshoring partner like Rite NRG to provide a senior, pre-vetted dedicated team. This move slashes the hiring timeline from months down to a couple of weeks, directly tackling the resource risk and keeping the project's momentum sky-high. Protecting your codebase is another key consideration here, and our guide on security in the software development life cycle offers deeper insights into this.
4. Accepting Minor UI Inconsistencies
The team flags a risk that some minor UI inconsistencies might pop up on less-used admin screens. The impact on the core user experience is practically zero, but fixing them all would chew up a lot of front-end development time.
- Strategy: Accept
- Action: The product owner makes the call: for the MVP launch, this risk is perfectly acceptable. The team logs the issue in the backlog to be tidied up post-launch, but agrees not to burn any current sprint capacity on it. It’s all about prioritizing the delivery of customer-facing features that drive business value.
Of course, even with the best preventative measures, things can still go wrong. That’s why having robust processes is crucial; learning about incident management best practices will make sure your team is ready to handle issues when they do crop up. By building this kind of actionable playbook, you turn potential project disasters into manageable, predictable steps on your path to success.
Getting to Grips with Third-Party and Supply Chain Risks
No software project is an island. Your success is completely entangled with a sprawling network of third-party APIs, open-source libraries, and cloud services. Your software is only ever as strong as its weakest link, which is why a high-energy, proactive approach to managing your supply chain risk isn't just a nice-to-have—it's absolutely essential for delivering reliable business outcomes.
Ignoring this reality is asking for trouble. A single flaky vendor or a dodgy open-source package can throw your entire delivery schedule into chaos, poke massive security holes in your system, or land you in a world of compliance pain. With the #riteway methodology, we don't sit around waiting for these problems to show up; we go hunting for them.
Mastering Vendor Due Diligence
Taking Extreme Ownership of your supply chain starts with getting serious about vendor due diligence. This isn't just about a quick price check; it’s a full-on investigation into a potential partner’s reliability, security posture, and financial stability. As your strategic partner, we bring the same intensity to this as we do to writing our own code.
Before you even think about integrating a third-party service, you need to ask some tough questions:
- What are their real uptime stats and performance history? You need to see the data, not just the marketing fluff.
- What’s their security track record like? Have they had recent breaches? What certifications (like ISO 27001) do they actually hold?
- How will they have your back when things inevitably go sideways? A rock-solid Service Level Agreement (SLA) is non-negotiable.
A solid third-party risk management process is your playbook for handling the maze of external dependencies and keeping your software supply chain secure. Skipping this step is like building a house on foundations you haven't bothered to check—a gamble no serious business should ever make.
Building an Architecture That Bounces Back
A huge part of software project risk management is designing an architecture that won't fall over if one of its dependencies does. Architectural resilience is all about building a system that can handle a third-party failure gracefully, without it becoming a catastrophe for your users and your revenue stream.
This comes down to making smart, proactive design choices from day one. A consulting mindset prompts us to implement patterns like circuit breakers that automatically cut off calls to an unstable API, stopping it from dragging your whole application down. Or we might design your system with fallback options, seamlessly switching to a secondary provider if the main one is offline, ensuring business continuity.
Don't just plan for your vendors to succeed; plan for them to fail. A resilient architecture works on the assumption that external services will fail at some point and is built to absorb the shock, protecting your revenue and your customers' trust.
Let's look at the numbers. The reliance on external services is a massive source of risk. Third-party risks in UK software projects are on the rise, driven by our dependency on SaaS, PaaS, and IaaS. It’s got so serious that the UK Corporate Governance Code now requires board-level oversight. While a healthy 77% of high-performing UK projects use project management software, it's worrying that only 52% have clear scoping documents and just 58% follow a defined methodology. That leaves huge gaps when it comes to managing these external risks.
Continuous Monitoring and SLAs That Have Teeth
Your job isn't done once the contract is signed. Your supply chain needs constant, watchful monitoring. We’re talking about setting up automated alerts that ping you the second a key vendor's performance starts to dip or they have an outage. This lets your team jump on the problem instantly, often before your customers even know something's wrong.
Your SLAs should be your shield and your sword. They need to be razor-sharp, spelling out exact metrics for uptime, response times, and how quickly issues get resolved. These aren't just legal papers to be filed away; they're operational tools that set clear expectations and give you a leg to stand on when a partner doesn't deliver. A well-crafted SLA is the sign of a mature team that knows how to de-risk its external dependencies.
For a deeper dive into how we build robust software from the ground up, check out the details of our bespoke software development service.
Your Top Risk Management Questions, Answered
Alright, we’ve covered the theory, but let's get real. In our experience as strategic consultants, the toughest challenges aren't in the textbooks. They're the practical, in-the-trenches questions we get every day from founders and CTOs who are trying to move fast without breaking things. This is where the rubber really meets the road.
Let's dive into some of the most common—and critical—questions we hear. These are the nuances that can truly make or break your project's momentum.
How Do We Weave Risk Management into Agile Sprints Without Killing Our Speed?
This is the big one, isn't it? Many teams fear that talking about "risk" will bog them down in bureaucratic nonsense. But with the right energy and mindset, the opposite is true. The secret is to make it a natural, lightweight part of the ceremonies you're already doing.
Think of it less as a formal event and more as a continuous mindset of proactive problem-solving.
- During Sprint Planning: When sizing up a user story, simply ask: "What's the biggest gremlin that could stop us from delivering the business value of this story?" A quick, five-minute chat can uncover hidden dependencies or technical curveballs that need tackling now.
- In Daily Stand-ups: Let's reframe "blockers" as "risks to the sprint goal." Instead of a flat "I'm stuck on the API," encourage the team to articulate the impact: "Heads up, there's a risk of a two-day slip on the payment feature because the third-party API docs are a mess. This puts our goal of launching the new checkout at risk." This simple shift turns a solo problem into a team-owned challenge that gets swarmed and solved.
The goal isn't to build a giant risk register every two weeks. It's about fostering a low-friction, ongoing conversation about what's around the corner. It's all about that shared sense of Extreme Ownership.
How Much Risk is "Okay" for an MVP?
There’s no magic number here; it’s a strategic business call, pure and simple. An MVP is about validating your biggest ideas as quickly as humanly possible. Therefore, you should be willing to accept risks that threaten bells and whistles but fiercely intolerant of anything that could compromise core functionality, betray user trust, or invalidate the data you need to collect.
A great rule of thumb is to ask this one simple question: "If this risk blows up, will it stop us from learning what we need to learn from this release?"
Look at it this way: if a potential issue only affects a 'nice-to-have' feature but lets you ship a week earlier, that's probably a smart gamble. But if that same risk could corrupt user data and make all your findings worthless, it's an absolute showstopper. It has to be dealt with before you even think about launching.
It’s all about making calculated trade-offs. A great strategic partner helps you make these decisions with your eyes wide open, ensuring you're taking intelligent shortcuts to get to market, not just blindly gambling with your product's future.
What’s the Single Biggest Risk Most Teams Completely Miss?
I see this one all the time. Hands down, the most consistently overlooked risk is team burnout and knowledge silos. Projects often end up with one or two key developers who hold the keys to the kingdom—all the critical knowledge is locked in their heads. This isn't just a "bus factor" problem; it's a direct threat to your speed, quality, and ability to deliver value predictably.
When one person becomes the bottleneck, everything slows to a crawl. That person gets buried under immense pressure, which is a recipe for mistakes and burnout. This single point of failure is often far more dangerous than any technical bug.
Getting ahead of this requires a proactive, people-first approach:
- Make pair programming a standard for complex features.
- Bake clear documentation into your "definition of done."
- Actively cross-train team members to build redundancy and collective ownership.
This is especially true in a critical area like security. Cyber security risks now sit at the top of the list for software project risk management in the UK, where specialist firms attracted a staggering £828 million in investments between 2019 and 2024. Despite the focus, vulnerabilities are everywhere, with a massive 93% of UK businesses reporting IT skills gaps. You can discover more insights about UK security export statistics to grasp the scale of this challenge. A single point of failure in your security expertise is a risk you simply cannot afford to take.
Ready to stop just reacting to risks and start proactively clearing the path to value for your MVP launch? The team at Rite NRG builds and scales SaaS products with senior engineering talent and a consulting mindset that makes delivery predictable.
Find out how our dedicated teams can help you ship up to 50% faster.

