


Let's be blunt: cloud computing scalability isn't just another tech buzzword. For any ambitious SaaS company, it's the very engine of your growth. It's the critical capability that allows your platform to gracefully handle a flood of new users without breaking a sweat, ensuring your own success never becomes your biggest liability.
Why Cloud Scalability Is Your SaaS Superpower
Stop thinking of scalability as a problem for "future you." For today's SaaS leaders, it's the line in the sand between a platform that merely functions and one that builds unstoppable momentum. As your strategic partner, we see scalability as the core of your competitive advantage, influencing everything from customer retention to your ability to confidently enter new markets.
Think of it like a world-class restaurant. It can serve a table for two with immaculate attention to detail. But when a surprise crowd of 500 diners walks in, it handles the rush with the exact same quality and speed. Your platform must do the same, treating every new user and every traffic spike as a golden business opportunity, not a five-alarm fire.
From Reactive Fix to Proactive Strategy
At Rite NRG, our #riteway methodology is grounded in Extreme Ownership and a high-energy, forward-thinking mindset. We don't just write code; we offer strategic advisory on technology and delivery. We firmly believe that real cloud computing scalability isn’t about frantically putting out fires when servers crash. It's about architecting for success right from the get-go. This proactive approach elevates scalability from a reactive technical chore into a core business strategy.
A proactive scalability strategy means you're not just building a product; you're engineering a platform that thrives on its own success. You're ready for the viral marketing campaign, the major client onboarding, and the unexpected surge in demand before it ever happens.
This consulting mindset is absolutely crucial. As your strategic partner, we guide the architectural decisions that deliver real, tangible business outcomes. A well-designed system isn't just a list of features; it's a value-delivery machine fine-tuned for growth.
The Measurable Business Outcomes of Scalability
Let's translate the technical talk into what really matters: business value. A scalable platform isn’t a "nice-to-have" — it's the fuel that allows your infrastructure to keep pace with your ambition. For any SaaS business, getting this right is non-negotiable. If you're building a product with explosive growth in mind, you can see more on our approach to expert product development for software.
This table breaks down how technical capabilities directly create powerful business results.
The Business Impact of True Cloud Scalability
| Scalability Feature | Technical Benefit | Measurable Business Outcome |
|---|---|---|
| High Availability | Minimal downtime during traffic spikes or component failures. | Reduced Customer Churn: A reliable app keeps users happy and loyal. |
| Elastic Architecture | Ability to add resources on-demand to support larger loads. | Faster Market Entry: Launch in new regions or serve enterprise clients without a platform rebuild. |
| Consistent Performance | Maintained low latency and fast response times for all users. | Higher Customer Lifetime Value (LTV): Great UX encourages loyalty and upgrades. |
| Future-Proof Design | A system built to handle 10x or 100x growth. | Increased Investor Confidence: Shows your business is built on a solid, growth-ready foundation. |
This isn't just about building bigger servers; it's about building a smarter, more resilient business.
Ultimately, cloud computing scalability means you're always ready for the next wave of customers. It’s about making sure your technology is an accelerator, not a bottleneck, on your journey to owning the market.
Understanding Vertical and Horizontal Scaling
To truly deliver business value through cloud scalability, you have to master the two fundamental ways your infrastructure can grow. These aren't just abstract technical concepts; they're strategic choices that will directly impact your bottom line and your customers' experience. We're talking about vertical and horizontal scaling, and as your strategic partner, we help you decide which lever to pull—and when—to build a platform that’s both resilient and cost-effective.
Let’s think about it this way: imagine your entire application runs out of a single, trusty warehouse. As your business booms, you need more space and power. Fast. You’ve got two choices.
The Power of Vertical Scaling
Vertical scaling, or "scaling up," is like adding another floor to your existing warehouse. You take your current server and just make it bigger and better—you pack in a more powerful CPU, slot in more RAM, or upgrade to lightning-fast storage. It’s a direct, no-fuss way to handle a bigger load on a single machine.
This approach is brilliant for a quick fix or smashing a specific bottleneck. Say your database server is struggling to keep up with queries, impacting user experience. Upgrading its CPU and RAM can deliver an instant performance kick and restore customer satisfaction. It’s a straightforward solution that often means you don’t have to touch a single line of your application's code.
But vertical scaling has a very real ceiling. Just like a building, you can only stack so many floors before things get wobbly or ridiculously expensive. You will inevitably hit a hardware limit, and the price tag for those top-of-the-line machines skyrockets, impacting your profitability.
Vertical scaling is all about making a single server more powerful. It's a great short-term fix for isolated performance problems, but it creates a single point of failure and has a hard physical limit.
Unleashing Horizontal Scaling
Now, what about that second option? Instead of building your warehouse taller, you build more identical warehouses right next to it. This is horizontal scaling, or "scaling out." You’re not beefing up one machine; you’re adding more machines to your fleet and spreading the work across all of them.
This is the magic behind the world's biggest applications and the key to unlocking massive business outcomes. When your SaaS product suddenly catches fire, you don't hunt for one mythical supercomputer. Instead, you spin up hundreds or even thousands of standard servers that work in concert. This method gives you almost limitless capacity and is the bedrock of a truly resilient system. If one of your "warehouses" has a problem, traffic just flows to the others, and your users never even notice.
- Enhanced Resilience: This directly translates to higher uptime and customer retention. You wave goodbye to single points of failure, protecting your revenue stream.
- Near-Limitless Growth: You can theoretically add as many servers as you need to handle any amount of traffic. This unlocks the ability to enter new markets or onboard enterprise clients on demand.
- Cost Efficiency at Scale: Scaling out typically relies on commodity hardware, which can be a much smarter investment than shelling out for a single, monolithic beast of a server, directly improving your margins.
Scalability vs. Elasticity: A Crucial Distinction
While we're on the topic, it’s absolutely vital to clear up the difference between two closely related ideas: scalability and elasticity. They might sound like synonyms, but understanding them is key to a cost-effective strategy.
- Scalability is about planning for growth. It’s the inherent ability of your system's architecture to handle an increased load. Think of it like designing a stadium with the structural integrity to hold 100,000 fans, even if you only expect 50,000 for the first match. The foundation is ready for the future.
- Elasticity, on the other hand, is about reacting to demand in real time. It’s your system's ability to automatically add or remove resources as traffic ebbs and flows. This is like having pop-up seating that appears instantly when the crowd surges for a goal and vanishes just as quickly afterwards, ensuring you never pay for empty seats.
A truly well-architected system is both scalable by design and elastic in its day-to-day operation. It’s built on a rock-solid foundation that can support long-term growth while dynamically flexing to meet short-term peaks. This ensures you’re always ready for anything, without paying for resources you aren’t using.
To really get to grips with how to adapt your infrastructure for any scenario, you need to dive into the nuances of Horizontal vs Vertical Scaling. Taking this kind of proactive, expert-led approach from the start is what makes sure your architecture is always perfectly in sync with your business goals.
Building Architectural Patterns For Unstoppable Growth
Knowing how to scale is one thing; actually building a system that scales effortlessly is the real game-changer. This is where your strategy truly meets execution. Let's move beyond abstract diagrams and dense jargon and talk about the architectural blueprints that genuinely power unstoppable growth, connecting each pattern to a tangible business outcome.
Here at Rite NRG, we bring a proactive consulting mindset to the table. We don't just build what we're told; we advise. Every single architectural choice we make has to answer one critical business question: "How does this help us win?" This relentless focus on delivering value is what elevates a good MVP into an investor-ready platform poised for market dominance.
Designing for Resilience and Flexibility
The bedrock of any scalable system is built on patterns that wipe out single points of failure and embrace change. A fundamental concept here is designing stateless services.
Picture your servers as a team of highly skilled, completely interchangeable workers. In a stateless setup, any worker can handle any incoming customer request because they don't hold onto any history from previous conversations. This seemingly small design shift has massive business implications. It means you can add or remove servers on the fly without ever disrupting user sessions, making your application incredibly resilient and directly improving customer retention.
Another non-negotiable pattern is load balancing. Think of a load balancer as the calm, collected traffic director at a chaotic intersection. It intelligently routes incoming user requests across your entire fleet of servers, ensuring no single machine gets swamped. This doesn't just prevent crashes during traffic spikes; it guarantees a consistently fast and smooth experience for every single user, which is a key driver of customer lifetime value.
This diagram gives a great visual comparison of the two main scaling strategies that these patterns support.
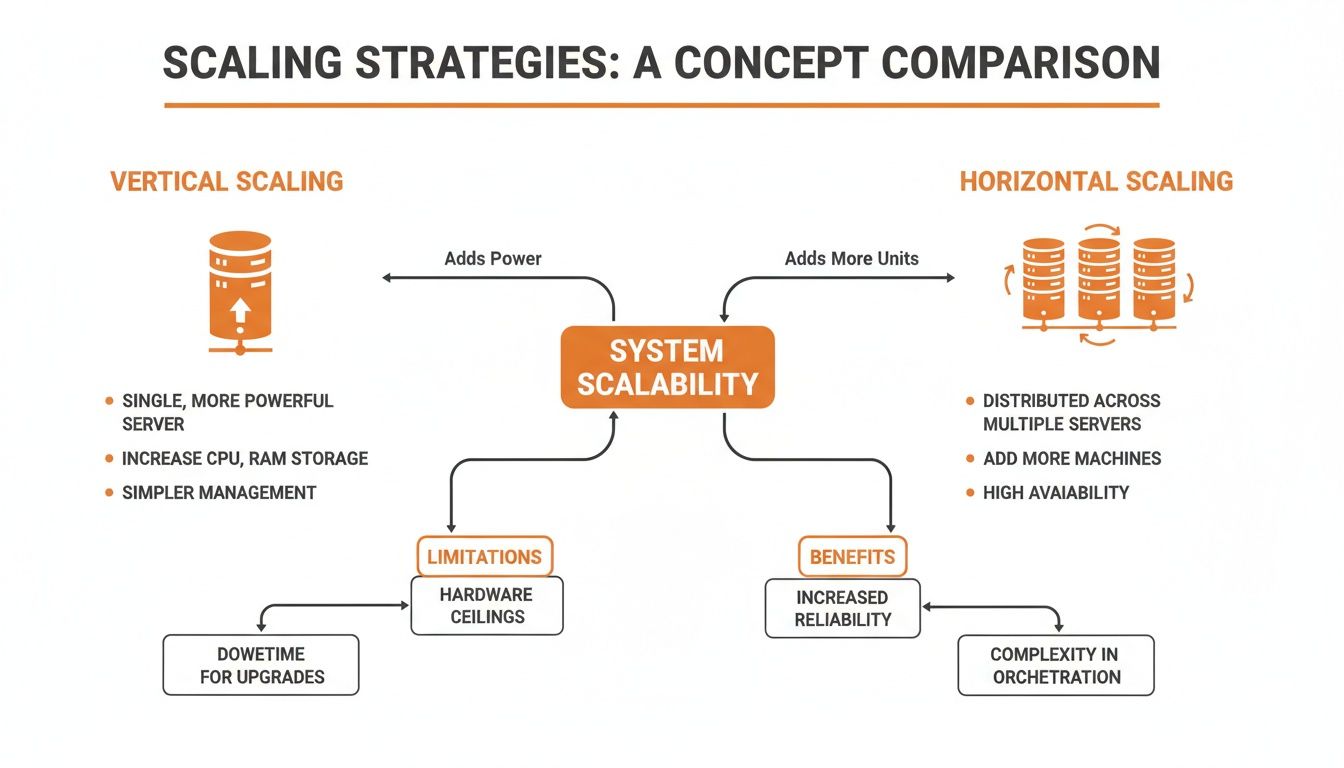
As you can see, while vertical scaling offers a quick power boost, it's horizontal scaling that delivers the near-infinite capacity and resilience you need for genuine long-term growth.
Architectures That Empower Autonomous Teams
As your SaaS platform grows, your engineering team will too. A monolithic architecture, where everything is tangled up in one large codebase, quickly becomes a bottleneck that grinds development and innovation to a halt. This is exactly where modern architectural patterns come into their own, delivering agility as a business outcome.
- Microservices: This approach is like breaking up one giant, slow-moving department into small, nimble, independent teams. Each microservice handles a specific business function—like user authentication or payment processing—and can be developed, deployed, and scaled all on its own. This empowers your teams to move incredibly fast and take real ownership of their domain, accelerating your time-to-market for new features.
- Serverless Computing: This is the ultimate "pay only for what you use" model. Instead of worrying about managing servers, you deploy functions that run only when they're triggered. It’s perfect for handling unpredictable workloads because it scales from zero to thousands of requests in an instant without anyone lifting a finger, which can dramatically optimise your operational costs.
To properly design robust cloud-native systems using these patterns, a deep understanding of Cloud Architecture is absolutely essential. These aren't just technical choices; they are strategic business decisions that breed agility and speed.
Optimising Data for Peak Performance
Even with the world's best compute architecture, slow data access can bring your application to its knees. Two patterns are critical for making sure your data layer can keep up with demand.
First, data partitioning (or sharding) involves breaking a massive database into smaller, more manageable pieces. This allows you to spread the data load across multiple machines, preventing any single database from becoming that dreaded bottleneck that frustrates users.
Second, caching involves storing frequently accessed data in a high-speed memory layer, much closer to the application. It's like keeping your most popular items right at the front of the warehouse for instant access. This slashes latency and dramatically improves response times for your users.
By implementing smart caching and data partitioning, you're not just speeding up your application; you're directly enhancing the user experience, which is a powerful driver for retention and growth.
This is particularly relevant in the UK, where SaaS scalability is fuelling a massive surge in the cloud market. The market is projected to rocket from USD 47.24 billion in 2024 to an incredible USD 135.24 billion by 2030, all driven by businesses ditching the limitations of on-premise setups for flexible scaling. With a whopping 72% of UK businesses expected to choose the public cloud as their primary model in 2025, the right architecture is no longer optional—it's the absolute key to capturing this growth.
These patterns are the building blocks of a truly scalable system, turning your architectural foundation into a serious competitive advantage.
Mastering Autoscaling and Orchestration Strategies
Having a brilliantly designed, scalable architecture is a massive win, but it’s only half the battle. The real magic—and the key to unlocking serious business value—happens when you make that architecture scale automatically. This is where we shift from theory into high-energy, proactive execution, turning your cloud infrastructure into a self-managing asset that directly fuels your bottom line.

Autoscaling isn't just a nifty technical feature; it's a strategic imperative. It’s the engine that ensures you deliver a flawless user experience while ruthlessly optimising your costs. It's about crafting intelligent, automated rules that add or remove resources in real-time, responding precisely to the actual demands your business is facing.
This is where the Rite NRG "can-do" attitude really shines. We don’t just set up autoscaling; we master it. We believe the right team is more than just a list of skills; it's a partner that transforms complex automation into a predictable, powerful tool for growth.
Dynamic and Scheduled Scaling in Action
True cloud computing scalability is never a one-size-fits-all game. Your strategy has to be nimble, adapting to both the predictable rhythms of your business and the electrifying chaos of a viral moment. That’s why a proactive approach combines two essential autoscaling strategies.
Scheduled Scaling for Predictable Peaks: Does your B2B SaaS platform get slammed with activity every Monday morning? Or maybe you run a massive Black Friday sale that you know will bring a tidal wave of traffic? Scheduled scaling lets you proactively boost capacity for these known events, making sure you’re ready before the first user even arrives.
Dynamic Scaling for Viral Moments: What happens when your product gets a shout-out in a major publication or a marketing campaign wildly exceeds expectations? Dynamic scaling is your safety net. It automatically adds resources based on real-time metrics, like when CPU utilisation spikes above 70% or request latency starts to creep up. It ensures your moment of triumph doesn’t turn into a server meltdown.
This dual approach means you’re always prepared. You handle predictable demand with cost-effective planning and absorb unpredictable surges with lightning-fast, automated reflexes.
The Business Outcome: Cost Optimisation and a Flawless UX
Let's be crystal clear about the business outcomes here. Autoscaling directly impacts two of your most important metrics: your cloud spend and your customer satisfaction.
Without it, you’re forced into a costly guessing game called "over-provisioning"—paying for a huge fleet of servers just in case you need them. With autoscaling, that waste is eliminated. You pay only for the exact resources you use, moment by moment, which can lead to jaw-dropping cost savings.
Autoscaling is the ultimate expression of Extreme Ownership over your cloud environment. It's about taking proactive control to ensure you never pay for idle resources while simultaneously guaranteeing your customers never experience a slow or unresponsive application.
On the flip side, under-provisioning is even more dangerous. A slow, laggy, or unavailable application is a one-way ticket to customer churn. Dynamic scaling ensures that as demand grows, your performance remains rock-solid, protecting your brand reputation and keeping your hard-won users happy.
Orchestration: The Conductor of Your Cloud Orchestra
As your application scales out horizontally into dozens, or even hundreds, of separate components, just keeping track of them all becomes an immense challenge. This is where orchestration tools like Kubernetes step in, acting as the energetic conductor of your cloud orchestra.
Orchestration automates the deployment, management, and scaling of your containerised applications. It’s the brain that tells each individual component what to do, where to run, and how to communicate with the others.
Think of it this way:
- Deployment: The conductor ensures every musician (container) is in the right place on stage.
- Healing: If a musician faints, the conductor instantly brings in a replacement without the audience ever noticing.
- Scaling: When the music reaches a crescendo, the conductor signals for more violins to join in, seamlessly adding more power.
With a skilled partner to implement and manage it, orchestration turns a potentially chaotic system of microservices into a perfectly synchronised, resilient, and highly scalable platform. It’s the final, crucial piece of the puzzle, turning your powerful architecture into a predictable, automated asset that’s always ready for the spotlight.
Taming the Beast: Modernising Legacy Systems for Limitless Scale
So, what happens if you’re not starting with a blank canvas? This is the reality for so many ambitious businesses. You have big plans, but you're shackled to a monolithic, legacy platform that was never designed for the elastic demands of the cloud. Let’s be clear: this isn't just a tech headache. It's a direct threat to your ability to compete, innovate, and keep your customers happy. The way forward isn’t a risky, all-or-nothing "big bang" rewrite; it's a smart, strategic path to modernisation.
Navigating the journey from a rigid monolith to a flexible, scalable architecture is one of the most defining challenges a CTO can face. It requires more than just code—it demands a consulting mindset. Every single decision has to be weighed against its business impact, ensuring that every step you take delivers real, measurable value without pulling the rug out from under your existing customers.
The Strangler Fig Pattern: A Pragmatic Approach
Instead of a terrifying, high-stakes migration, we’re huge advocates for pragmatic, phased approaches like the strangler fig pattern. Picture a new vine wrapping itself around an old tree. Bit by bit, the vine grows stronger and more self-sufficient until, eventually, it completely replaces the tree. That’s exactly how we tackle legacy modernisation.
We strategically build new, scalable microservices around the edges of your old monolith. These new services start to intercept requests and handle modern functionality, gradually "strangling" the old system's responsibilities. Before you know it, the legacy core has nothing left to do and can be safely and quietly retired.
This isn't just about shipping new features; it's about systematically de-risking an incredibly complex transition. The strangler fig pattern lets you deliver continuous value, boost performance, and build for the future—all without taking your entire platform offline for months.
Where to Start? Prioritise for Maximum Business Impact
With a smart pattern in place, the million-dollar question is: where do we begin? Our #riteway methodology, grounded in the principle of Extreme Ownership, demands that we start where the business value is greatest. We don't just ask, "What can we migrate?" We ask, "What should we migrate first to make the biggest possible difference, right now?"
For instance, we might target these high-impact areas first:
- User Authentication Service: Moving this out first can immediately supercharge security, speed up logins for every single user, and unlock modern features like social sign-on.
- Payment Gateway: A new, scalable payment service can slash transaction failures, open up new currencies, and smooth out the checkout process—directly boosting your bottom line.
- Reporting Engine: Hiving off a slow, resource-hungry reporting module into its own service frees up the core application and gets critical insights to your customers faster.
This value-first approach is especially critical in the UK market, where cloud migration strategies are shifting fast. There's a huge move towards hybrid models that bridge legacy systems to modern SaaS solutions without causing downtime—a sector enjoying a 19.4% CAGR. While the government’s “Cloud First” policy is pushing public cloud adoption and helping SMEs scale affordably, this hybrid path is the lifeline for established enterprises. You can read more about these UK cloud migration trends to see the bigger picture.
At the end of the day, modernisation is a strategic mission, not just a technical project. Partnering with a team that has been down this road before ensures this complex process is managed with a steady, experienced hand. It's all about seamless handovers, building a rock-solid foundation for your future, and turning your technology into a growth accelerator instead of an anchor holding you back.
Answering Your Cloud Scalability Questions
As a SaaS founder or CTO, you live at the intersection of technical decisions and business outcomes. When you're thinking about cloud scalability, the questions that keep you up at night are rarely just about servers and code; they’re about growth, cost, and outmanoeuvring the competition. Let's dive into the big ones with the kind of clarity and energy you should expect.
We’re not here to hand you a textbook. We're here to give you the strategic insight to make the right call for your business, backed by our #riteway approach of high energy and Extreme Ownership.
What Is The First Step To Improving Application Scalability?
Honestly? The most critical first step has nothing to do with technology. It's about strategy. Before you even think about touching a line of code or resizing a server, you have to find your real performance bottlenecks. This means taking a hard, honest look at your application's architecture and performance data, all through the lens of your immediate business goals.
Are you about to launch a massive marketing campaign? Is your user base set to double after a new feature release? We always start by digging into this business context first. Only then do we bring in the monitoring and observability tools to find the weakest links in your system. It could be a database gasping for air, a clunky stateful service creating traffic jams, or an inefficient algorithm just torching CPU cycles for no good reason.
It's only after we've diagnosed the root cause that we can design a solution that actually delivers business value. This Extreme Ownership mindset ensures your first move is a giant leap forward, not just a frantic shot in the dark.
How Can I Balance Scalability Costs With Performance?
The real win isn't just building something that can scale infinitely; it's building something that scales cost-effectively. Hitting that sweet spot is all about smart automation and getting proactive with your resource management. You have to ditch the old-school approach of over-provisioning for peak traffic and then watching those expensive resources sit idle 90% of the time.
The secret is implementing smart autoscaling policies tied to real-world metrics—CPU utilisation, request latency, or even custom business metrics like the number of active user sessions. This way, you’re only paying for the exact resources you’re using at any given moment. What’s more, adopting serverless architectures for those unpredictable, "bursty" workloads can be an absolute game-changer for your cloud bill.
A good partner can help you dissect your usage patterns and roll out these kinds of clever cost-optimisation strategies. It might mean using spot instances for non-critical jobs or simply right-sizing your entire infrastructure, creating a system that’s both incredibly powerful and financially lean.
When Should I Consider A Multi-Cloud Or Hybrid Strategy?
Let's be clear: going multi-cloud or hybrid just to follow a trend is a terrible idea. It only becomes a powerful, strategic move when it solves a specific business problem that a single cloud provider just can't handle.
A hybrid cloud setup, for instance, is often perfect for businesses wrestling with strict data sovereignty or compliance rules like GDPR. It lets you keep your most sensitive data securely on-premise while still tapping into the public cloud's amazing elasticity for everything else.
On the other hand, a multi-cloud strategy is a fantastic way to avoid getting locked into one vendor, boost your overall resilience, and cherry-pick the absolute best-in-class services from different providers. But—and this is a big but—both of these advanced setups add a ton of operational complexity. The decision has to be deliberate and driven by real value. We help our partners figure out the true ROI, navigate the operational headaches, and build the orchestration needed to manage these sophisticated environments. A big part of that is getting a firm grip on your security posture, which you can read more about in our guide to performing an information technology security audit.
How Does A Delivery Partner Accelerate Scalability Efforts?
Real acceleration isn't just about throwing more engineers at a problem. It's about deploying a senior, product-minded team that operates within a proven, high-energy framework. We speed up your scalability journey in three key ways:
Immediate Expertise: We drop in with deep, battle-tested experience from architecting and launching highly scalable systems for dozens of SaaS clients. We’ve seen what works, what breaks, and how to dodge the common bullets.
Predictable Delivery: Our culture of Extreme Ownership means you can count on us. We call out risks early, over-communicate, and stay laser-focused on outcomes, helping you ship new capabilities up to 50% faster.
Seamless Integration: Our nearshore model gives you access to top-tier talent that plugs directly into your team and your workflow. We bring that "can-do" attitude and collaborative fire needed to crush complex projects as one unified force.
We don't operate like a vendor. We become your strategic partner, making sure every architectural choice and line of code is fueling measurable, unstoppable growth for your business.
Ready to build a platform that doesn't just keep up with your growth but actually powers it? The team at Rite NRG is here to help you architect, build, and scale a SaaS product that's ready for anything. Let's talk about turning your scalability challenges into your greatest competitive advantage. https://ritenrg.com

