


Most advice about the lovable dev is fluff. It treats “lovable” like a personality trait. Friendly. Easy-going. Nice in meetings. That’s not what makes a developer valuable to a SaaS business.
A lovable dev is lovable because they reduce business risk and increase delivery confidence. They don’t just write code. They spot broken assumptions, challenge weak product decisions, surface blockers early, and keep momentum when everyone else starts waiting for permission. That’s the difference between a pleasant hire and a force multiplier.
The teams that matter operate like an operational system. Culture, process, and AI all point at the same thing: shipping useful software fast, with fewer surprises. That’s the standard. Anything less is just expensive motion.
Redefining the Lovable Dev Beyond Soft Skills
The market keeps selling a weak definition of lovable dev. It usually sounds like this: collaborative, empathetic, easy to work with. Fine. Baseline professionalism matters. But if that’s your hiring bar, you’ll end up with polite underperformance.
A real lovable dev earns that label through ownership, problem-solving, and delivery. They behave like someone tied to the outcome, not someone renting out hours. If the backlog is wrong, they say it. If the MVP is bloated, they cut it. If launch risk is rising, they don’t hide behind Jira.
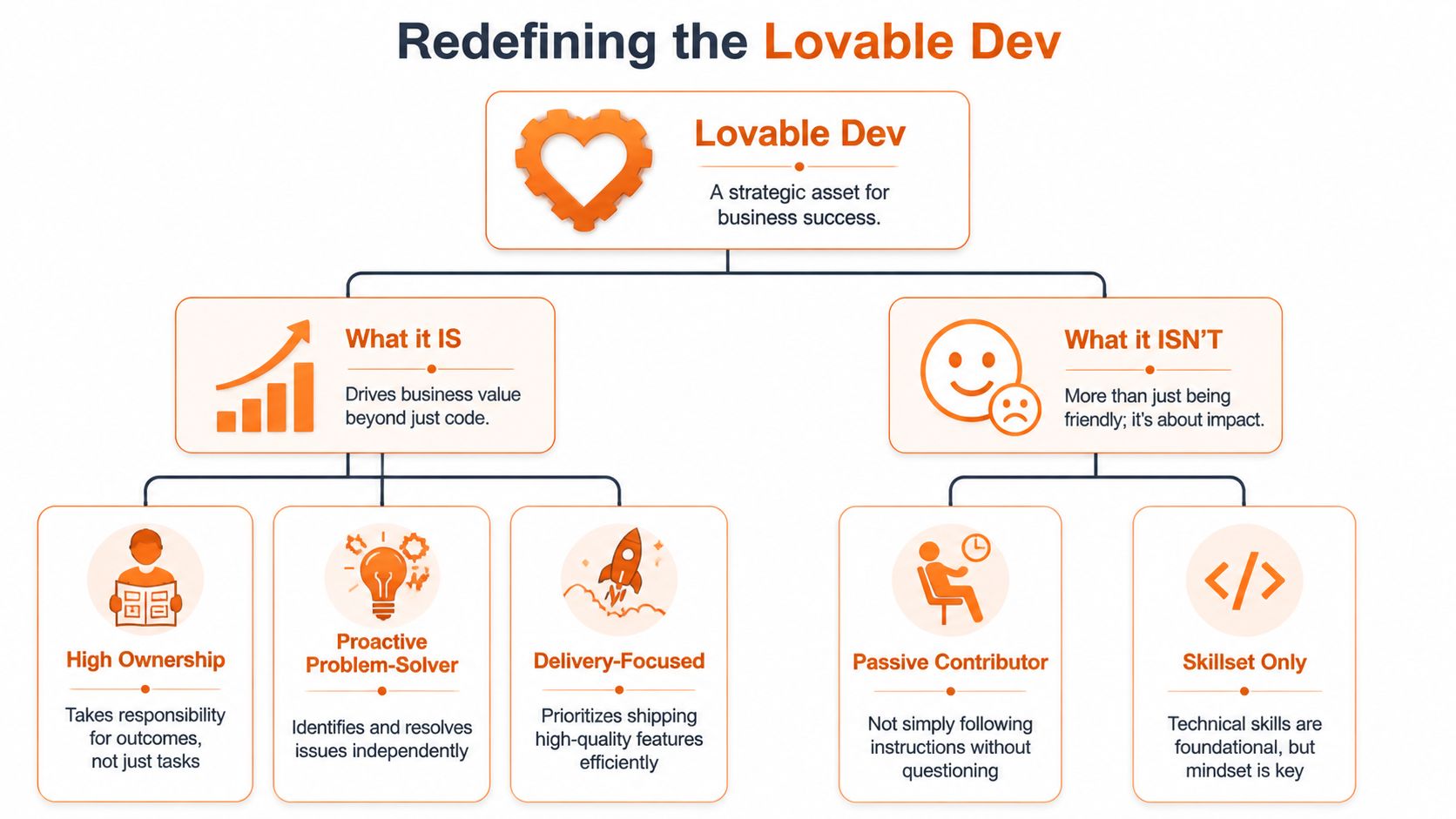
What the lovable dev actually is
The strongest teams I’ve seen all run on three essential principles.
- Extreme Ownership means the work doesn’t stop at “my ticket is done”. The developer cares whether the feature works in production, whether users understand it, and whether it supports the commercial goal.
- High energy means momentum. Not theatre. Not fake enthusiasm. Real urgency, fast follow-up, quick decisions, and visible progress that keeps the whole product team moving.
- Proactive communication means they raise issues before those issues become cost. They don’t wait until sprint review to admit integration is failing or requirements are muddy.
That combination creates a team people trust.
Practical rule: If a developer only reports activity, they’re a contributor. If they improve the plan while delivering it, they’re a partner.
What the lovable dev is not
The lovable dev isn’t passive. They don’t hide behind task lists, technical jargon, or endless “discovery” that never becomes shipped product.
They also aren’t defined by skillset alone. A brilliant React, Node, Supabase, or Tailwind engineer who needs constant chasing is still a drag on business performance. A team can have excellent CVs and still miss market windows because nobody owns the result.
Here’s the sharper definition:
| Trait | Weak version | Strong version |
|---|---|---|
| Communication | Gives updates | Surfaces risks and options |
| Ownership | Completes assigned work | Protects the business outcome |
| Pace | Busy all sprint | Ships value continuously |
| Mindset | Takes instructions | Advises, challenges, improves |
That’s why the lovable dev conversation needs to move away from sentiment and toward operating standards. Teams become lovable when stakeholders stop worrying about whether things will land.
The strongest delivery cultures build this deliberately. Around here, that operating style is the #riteway mindset: own the outcome, bring energy, and act early. It sounds simple because it is simple. It’s just rare.
The RiteWay Hiring Playbook for High-Ownership Talent
Most hiring processes are built to find competence, not accountability. That’s why so many SaaS firms end up with developers who can pass a technical interview but disappear inside ambiguity.
If you want a lovable dev, stop hiring for stack keywords first. Hire for behaviour under pressure. Technical depth matters, of course. But for product delivery, the better question is whether the person can handle uncertainty without becoming a management burden.

A good hiring loop should test three things: how they think, how they communicate, and what they do when the obvious plan breaks.
Ask for judgement, not just answers
Skip the lazy “how would you build X?” questions. Those reward polished theory. Use scenario questions that expose ownership.
Try questions like these:
You find a major flaw in the product strategy one week before launch. What do you do?
Strong candidates don’t just mention escalation. They talk about validating impact, proposing options, and helping the team make a fast decision.A founder asks for a feature that will slow delivery and muddy the MVP. How do you respond?
You’re looking for commercial judgement, not obedience.A production issue appears outside your direct area. What happens next?
Ownership shows up when people move toward the problem.You inherit messy code and vague requirements. How do you create momentum in the first week?
Strong people create clarity. Weak people ask to be spoon-fed.
The right candidate doesn’t defend their comfort zone. They expand responsibility around the problem.
Watch for regulated-sector maturity
Many AI-first hiring recommendations fall short. In regulated products, you need people who understand accountability, auditability, and risk. A 2025 UK SaaS report cited by UI Bakery says 68% of 1,200+ startups faced compliance hurdles delaying MVP launches by 3-6 months, with only 22% using pure AI tools due to security insufficiencies. That’s the signal. In serious environments, code generation doesn’t replace senior judgement.
If you need help widening the talent funnel, an AI talent placement agency can be useful, especially when you want engineers already comfortable working with AI-assisted delivery rather than threatened by it.
For teams comparing sourcing models, this guide on how to hire a dedicated developer is worth reviewing because it frames the key issue correctly: not who can code, but who can integrate into delivery without friction.
The red flags that should end the process
Don’t overcomplicate this. Some signals are obvious.
- Blame-heavy language means low ownership. If every failed project was the PM’s fault, the client’s fault, or the legacy system’s fault, expect more of the same.
- Tool worship is another warning sign. Candidates who keep talking about frameworks instead of trade-offs usually optimise for craft over outcome.
- No questions about the business tells you they’re applying for tasks, not responsibility.
The best hires almost always ask about user risk, commercial priorities, release constraints, and team dynamics. They want the full picture because they expect to carry part of it.
Activating Your Team with High-Energy Onboarding
A strong hire can still fail inside a weak onboarding process. If the first month is full of access requests, fuzzy priorities, and status meetings with no decisions, you’ve already throttled output.
High-performance onboarding is simple. Drop the ceremony. Build context fast, remove ambiguity, and make ownership visible from day one.
The first-week operating rhythm
The best onboarding I’ve seen starts with business context, not tooling. Before anyone opens Linear, Jira, GitHub, or Supabase, they need to know what matters commercially.
Use this sequence:
- Start with the business goal deep dive. Show the product ambition, the user problem, the current constraints, and what a useful win looks like in the next release.
- Map the decision makers. Every engineer should know who owns product priorities, who signs off compliance, and who can unblock architecture choices.
- Define update standards early. Replace “status reports” with short proactive updates that answer three things: what moved, what’s at risk, what decision is needed.
That last point changes behaviour fast. Passive teams report effort. Active teams report movement.
Set the team up to act like stakeholders
Most onboarding fails because companies treat developers like implementation hands. Then they wonder why nobody speaks up when the scope is nonsense.
Give people the operating environment to think properly:
| Area | Weak setup | Strong setup |
|---|---|---|
| Product context | Ticket-level only | User problem, commercial priority, release goal |
| Communication | Long status meetings | Short proactive updates and fast escalation |
| Documentation | Scattered links | Single source of truth |
| Ownership | Assigned tasks | Clear decisions and expected outcomes |
A useful reference point is this case study on rapid onboarding personalization. Not because every team needs the same setup, but because speed improves when onboarding is designed intentionally instead of left to chance.
Operator’s note: Onboarding isn’t admin. It’s your first delivery sprint, just without code.
The non-negotiable rituals
Keep these tight and repeatable.
- Daily proactive check-ins. Short, written, useful.
- Architecture visibility early. New joiners should understand the shape of the system before they start changing it.
- Decision logs. If the team changes direction, document why. This cuts rework and protects momentum.
- Early demos. Even rough progress should be shown quickly. Visibility drives accountability.
A lovable dev team doesn’t wait to “settle in”. They get aligned fast, ask sharp questions, and start creating confidence immediately.
Building a Fast and Predictable Delivery Engine
Fast delivery without predictability is just panic with nicer branding. Plenty of teams look quick in week one and become chaos by sprint three. They overbuild, chase edge cases, and let AI-generated output create hidden maintenance debt.
The better model is boring in the best way. Clear priorities. Tight scope. Senior judgement. Costs that don’t drift every time the prompt loop gets longer.

Measure what executives actually care about
Story points don’t tell a founder much. Neither does velocity in isolation. The delivery engine should track whether the team is shortening the path to value.
Focus on questions like these:
- How quickly can a customer-facing improvement go live?
- Which unresolved risks could delay launch or increase rework?
- Are we shipping the smallest useful version, or indulging technical vanity?
If the team can’t answer those questions cleanly, they’re not running a predictable engine.
Why budgeting breaks with prompt-first delivery
Many lovable dev discussions often overlook a key reality: AI coding tools can be brilliant for prototypes, but scaling with token-based workflows can turn cost planning into guesswork.
A 2026 UK Tech Nation survey discussed in this analysis found 55% of SaaS leaders abandoned prompt-to-code tools post-prototyping due to unpredictable scaling expenses. That should get every CTO’s attention. Prototype speed is useful. Budget volatility isn’t.
That’s also why process maturity matters. Teams with stronger delivery discipline create fewer loops, fewer rewrites, and fewer expensive dead ends. If you want a useful model for that, the CMMI maturity model in software delivery is still relevant because it forces a question many teams avoid: is your process repeatable, or are you relying on heroic individuals?
Build the engine around constraints
The strongest delivery setups usually share the same traits.
- Brutal MVP discipline. They prioritise what proves value, not what decorates the roadmap.
- Senior review at key decision points. Not bureaucracy. Just enough experience in the loop to stop avoidable mistakes.
- Transparent trade-offs. Everyone knows what got cut, why it got cut, and what risk remains.
- Stable collaboration rhythms. Product, design, and engineering stay in the same conversation.
Predictable teams don’t promise certainty. They reduce avoidable surprises.
Nearshore collaboration works well here because it can combine speed with clearer commercial control. The best nearshore teams don’t just offer lower cost. They offer structured accountability, cultural alignment, and fewer budget shocks than volatile AI-only build paths. That’s what turns software delivery from a cost centre into an operating capability.
Using AI to Amplify Your Lovable Dev Team
AI doesn’t remove the need for a lovable dev team. It raises the standard for what that team should do.
Weak teams use AI to produce more output. Strong teams use AI to create more certainty. That’s the difference that matters. The first group generates code faster. The second group reaches usable product decisions sooner, clears blockers earlier, and protects quality while moving quickly.

Where lovable dev actually helps
Tools like Lovable are powerful when teams know how to use them. The useful pattern isn’t “AI replaces engineering”. It’s AI handles repetitive generation and surfacing, while experienced people direct, validate, and tighten the system.
According to Lovable’s guide to using RAG in app development, Retrieval-Augmented Generation can support 60-85% faster MVP delivery compared to traditional methods, and that same source says the process can reduce time-to-market from months to less than 30 days. That’s meaningful. It’s also only valuable when someone competent owns the final product decisions.
A lovable dev team uses AI in the parts of delivery where speed compounds:
- Exploring first-pass implementation options across frontend and backend
- Navigating larger codebases with better context through RAG
- Surfacing likely failure points early instead of discovering them late in QA
- Reducing repetitive build friction so engineers spend more time on architecture and product judgement
The operating model that actually works
The pattern I recommend is simple.
- Use natural language tools to accelerate first drafts, scaffolding, and low-risk implementation.
- Layer retrieval and system context so the model works from your codebase and decisions, not generic assumptions.
- Put senior humans on review, architecture, and release judgement.
- Feed the learnings back into process so the next cycle gets tighter.
If you want a practical breakdown of that workflow, this guide to AI-driven software development is useful because it treats AI as part of a delivery system, not a magic trick.
Here’s a useful demonstration to review before you institutionalise anything:
Don’t let AI hide weak culture
This is the trap. AI can make an undisciplined team look productive for a short period. Lots of code. Lots of demos. Lots of velocity theatre.
But if nobody owns architecture coherence, compliance implications, release quality, or commercial trade-offs, the gains vanish. That’s why the lovable dev model matters more in an AI-heavy workflow, not less. Ownership is the control layer.
AI should increase leverage, not lower accountability.
Used properly, AI gives high-ownership teams more reach. Used badly, it gives low-ownership teams more ways to create expensive mess.
From Lovable Team to Unstoppable Business
The phrase lovable dev sounds soft. Yet, it's hard-edged. It’s about building a team that protects momentum, compresses decision cycles, and keeps product delivery tied to business value.
That kind of team is your defence against the failures that kill promising products. Incomplete prototypes. Fragile launches. Scope drift disguised as innovation. AI-generated progress that collapses the moment real users arrive.
Why experience still wins
There’s a reason experienced teams keep outperforming hype. They know when to use AI, when to challenge requirements, and when to stop building.
That matters because the failure rate around rushed product creation is brutal. Contrary’s Lovable company research notes that incomplete prototypes cause 60% of non-technical users to abandon projects, and that over 90% of niche SaaS products fail to reach $1K MRR. Those numbers should end the fantasy that speed alone is enough.
The real playbook
If you want a lovable dev capability that changes business outcomes, keep it tight:
- Hire for ownership first. Skill matters, but behaviour under ambiguity matters more.
- Onboard for alignment. New people should understand the business problem before they touch implementation.
- Run delivery as a system. Prioritisation, communication, and review cadence determine predictability.
- Use AI with supervision. Amplify strong teams. Don’t try to replace them.
The businesses that win don’t assemble random talent and hope chemistry appears. They build an operating model where ownership is expected, energy is visible, and problems get solved early.
That’s what turns a development team into a growth asset.
If you want a delivery partner that treats lovable dev as an operating system, not a buzzword, talk to Rite NRG. They help SaaS teams build faster, scale with senior engineering talent, and keep delivery predictable through strong ownership, sharp process, and AI embedded where it provides value.

