


It is 8:15 on a Monday. Your support dashboard is green, your SLA report looks acceptable, and your leadership team assumes service is under control. By 10:30, a billing incident, a product bug, and a spike in account access requests have buried the queue. Senior agents are rewriting the same answers, escalations arrive stripped of context, and product signals are trapped inside Zendesk instead of reaching engineering. What looked stable at the surface was already failing underneath.
For a CTO, this is not a customer support side issue. It is an operating model problem with direct impact on retention, margin, and delivery speed. Support becomes the place where broken workflows, weak system handoffs, and missing product telemetry show up first. If you ignore it, you pay twice. Once in service cost, then again in churn, rework, and avoidable engineering noise.
AI powered customer service matters because it changes the unit economics of service and improves how information moves across the business. The market has already shifted in that direction, with UK government reporting a sharp rise in AI adoption among businesses in recent years, as noted by the Department for Science, Innovation and Technology and the Office for National Statistics. It's not about whether to add AI. It is whether you will implement it in a way that reduces queue volume, improves resolution quality, and feeds clean operational data back into your product and commercial teams.
Treat this like a core platform decision. If your knowledge base is fragmented, your ticket taxonomy is weak, your CRM and support stack do not share context, and your escalation paths rely on human memory, AI will amplify the mess. If you build the right foundations, AI becomes a high-yield service layer across support, product, and revenue operations.
Your Customer Service Is a Ticking Time Bomb
When a SaaS company starts to grow, customer service usually breaks in a predictable sequence.
First, inbound volume rises faster than the team expected. Then response quality starts to drift because newer agents don't have the same judgement as your experienced people. Then burnout sets in, because your strongest operators spend their day re-answering the same low-value queries instead of solving the difficult issues that protect revenue.
What breaks first
The failure rarely starts with technology. It starts with operating design.
- Repetition dominates the queue: Password resets, billing questions, order status, account changes, and basic product guidance swamp the inbox.
- Escalations get messy: Agents hand over issues without clean context, so customers repeat themselves and frustration climbs.
- Leaders lose signal: Product, commercial, and support data sit in different systems, so recurring problems stay hidden for too long.
At this juncture, many leadership teams make the wrong call. They treat support pressure as a staffing issue and hire into the problem. That works for a while. Then volume rises again, costs follow, and the same bottlenecks return.
Support doesn't collapse because teams work too slowly. It collapses because the operating model can't absorb demand without adding people.
Why AI is now a strategic move
AI powered customer service fixes the structural issue if you deploy it properly. It absorbs repetitive demand, routes work with better precision, and gives agents the context to resolve exceptions faster. That changes the economics of support.
A major UK milestone was the mainstreaming of chatbots and virtual assistants across banking, telecoms, and retail during the 2010s, as regulation, service pressure, and customer demand pushed automation into the mainstream, not the experimental corner, as described in Master of Code's overview of AI in UK customer service. For a CTO, the takeaway is simple. This is no longer a side innovation project. It's core service infrastructure.
If you lead engineering or product, treat support automation the same way you treat payments, identity, or observability. It directly shapes customer trust and operational efficiency.
Beyond the Hype What AI Customer Service Really Is
AI-powered customer service is often discussed as if it's a chatbot sitting on a website. That's too narrow and it leads to weak implementations.
A better way to think about it is as a digital nervous system for service operations. Inputs come in from live chat, email, social, phone, forms, and help centre activity. The AI layer interprets those signals, decides what should happen next, and pushes the right action into the right channel or tool.
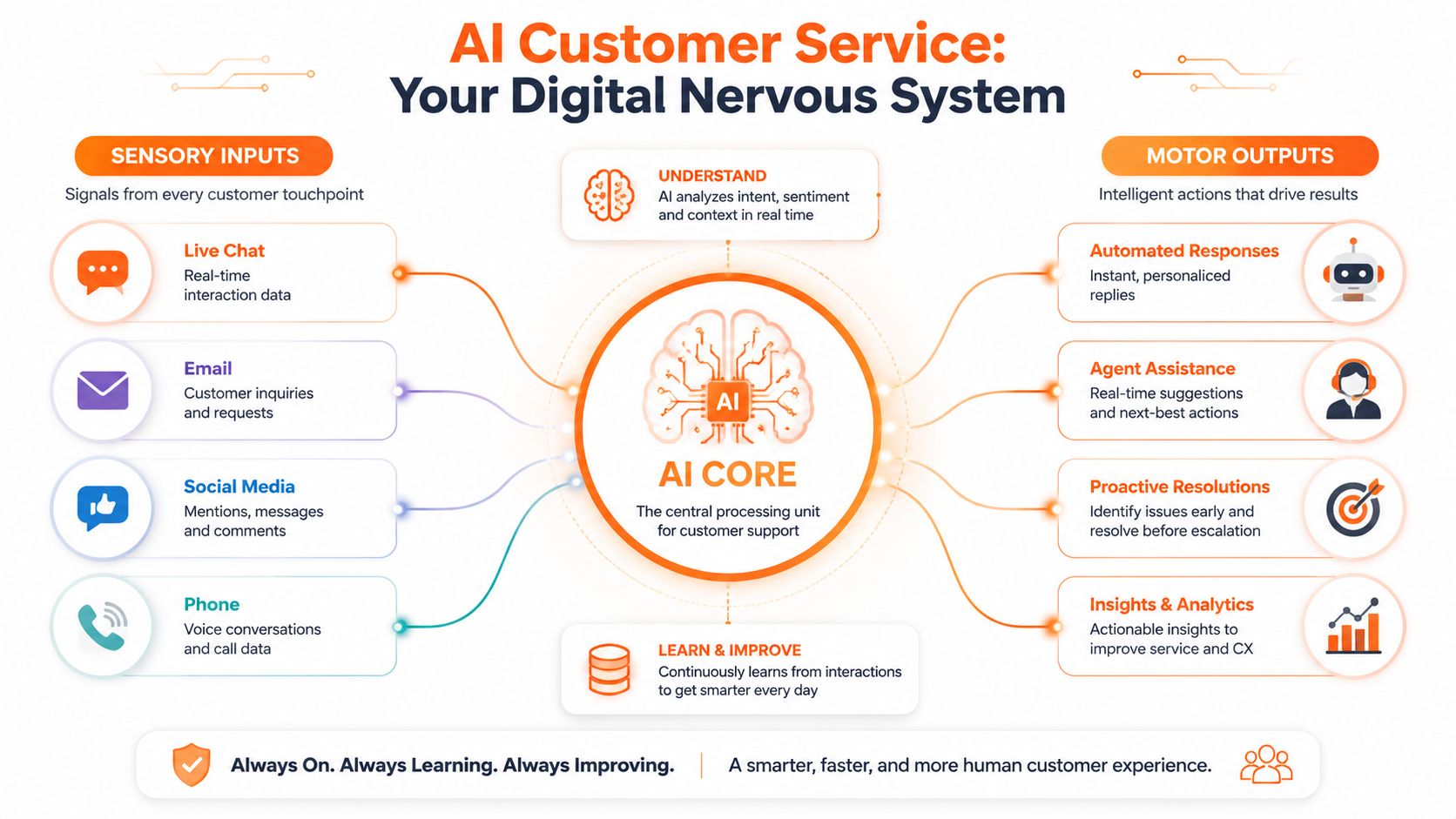
If you want a practical companion read, Halo AI's customer service guide is useful because it frames AI around support operations rather than abstract model talk. For leaders thinking beyond chat interfaces, this perspective also connects well with broader product thinking around Lovable AI and product delivery.
Intelligent self-service
This is the most obvious layer and still the one most companies underbuild.
Good self-service doesn't just answer FAQs. It identifies intent, pulls the right article or workflow, asks follow-up questions where needed, and completes simple tasks without a human touching the interaction. That matters because routine demand is where support queues get bloated first.
The business problem it solves is straightforward. You stop paying skilled people to repeat deterministic answers all day.
Agent augmentation
Serious value emerges. AI should sit beside your agents, not just in front of your customers.
Think real-time suggestions, ticket summaries, recommended next actions, conversation classification, sentiment cues, and pre-filled responses grounded in your knowledge base and account context. Your agents don't need another dashboard. They need faster judgement support inside the systems they already use.
Practical rule: If your AI only talks to customers and doesn't help agents, you're leaving too much value on the table.
Proactive insight generation
The strongest service teams don't just react. They detect patterns early and act before tickets pile up.
AI can surface recurring failure themes, highlight policy confusion, identify content gaps, and expose where customers get stuck in onboarding or billing journeys. That turns support into an operational intelligence layer for product and revenue teams.
Here's the important distinction:
| Capability | Weak implementation | Strong implementation |
|---|---|---|
| Self-service | Static bot answers | Context-aware task completion |
| Agent support | Generic suggestions | In-workflow guidance with history |
| Insights | Conversation logs | Actionable patterns for ops and product |
Most failed projects chase the interface. Strong teams design the decision system behind it.
The Business Case Moving from Cost Centre to Value Engine
It is 8:45 on a Monday. A billing issue hits, contact volume spikes, wait times climb, and your best agents get pulled into password resets and order-status questions while high-risk customers sit in queue. That is the commercial case for AI-powered customer service in one scene. The problem is not support cost alone. It is wasted capacity, avoidable churn risk, and a service model that breaks under pressure.
Prioritise AI here because the economics are clear. Chatbots can handle up to 80% of routine inquiries, with support-cost reductions of about 30%, according to TechClass's summary of IBM and other industry findings. The right response is not a broad rollout. It is a focused operating decision. Start where volume is high, complexity is low, and the resolution path is rules-based.
The Real Sources of ROI
A weak business case talks about labour savings and stops there. A strong one shows how service capacity turns into business performance.
ROI comes from four places:
- Lower unit cost on repetitive demand: AI handles predictable contacts at a fraction of the cost of human-assisted channels.
- Higher-value agent time: Senior agents spend more time on retention, complaints, escalations, and revenue-sensitive conversations.
- Better service resilience: Spikes in volume stop wrecking SLAs and pulling the whole function into triage mode.
- Faster operational learning: Patterns in service demand become visible sooner, so product, billing, and onboarding teams can fix root causes.
That last point matters more than many CFOs expect. Once AI starts classifying and routing work consistently, support stops being a reporting afterthought and becomes a live signal on where the business is creating friction. If you want that system to act, not just answer, the design principles behind agentic engineering for production workflows are worth applying early.
Use cases to prioritise first
Your first wave should prove margin improvement and service stability fast. Do not start with edge cases. Start with high-frequency tasks that already follow a clear decision tree.
| Priority use case | Why it goes first | What good looks like |
|---|---|---|
| Password resets | Clear path, low ambiguity | Fast completion without escalation |
| Order or account status | Data retrieval task | Accurate, context-aware response |
| Account changes | Rules-driven workflow | AI executes or routes correctly |
| FAQ retrieval | Knowledge-heavy, repetitive | Consistent answers from approved content |
Vodafone's AI assistant TOBi reportedly resolves about 70% of inquiries on its own while cutting cost-per-chat by 70%, as noted earlier. The lesson is practical. High-volume, low-complexity flows give you the fastest path to measurable value and the cleanest proof that the model deserves broader deployment.
Start with repetitive demand that drains your team. Then reinvest the recovered capacity into the interactions that protect revenue and customer trust.
What your CFO needs to hear
Keep the business case simple and hard-edged.
You are shifting work from expensive human channels to lower-cost automated ones. You are improving consistency across high-volume interactions. You are freeing experienced agents to handle cases where judgement changes the outcome. You are building a service operation that can absorb growth without scaling cost linearly.
That is how customer service stops behaving like a cost centre and starts operating like a value engine.
Architecting for Success The Technical Foundations
The model is not the main event. Integration is.
That's the architectural truth too many teams learn after they've already launched a weak bot into production. If the AI can't access customer context, ticket history, business rules, and approved knowledge, it won't deliver useful outcomes. It will generate friction faster than it generates value.
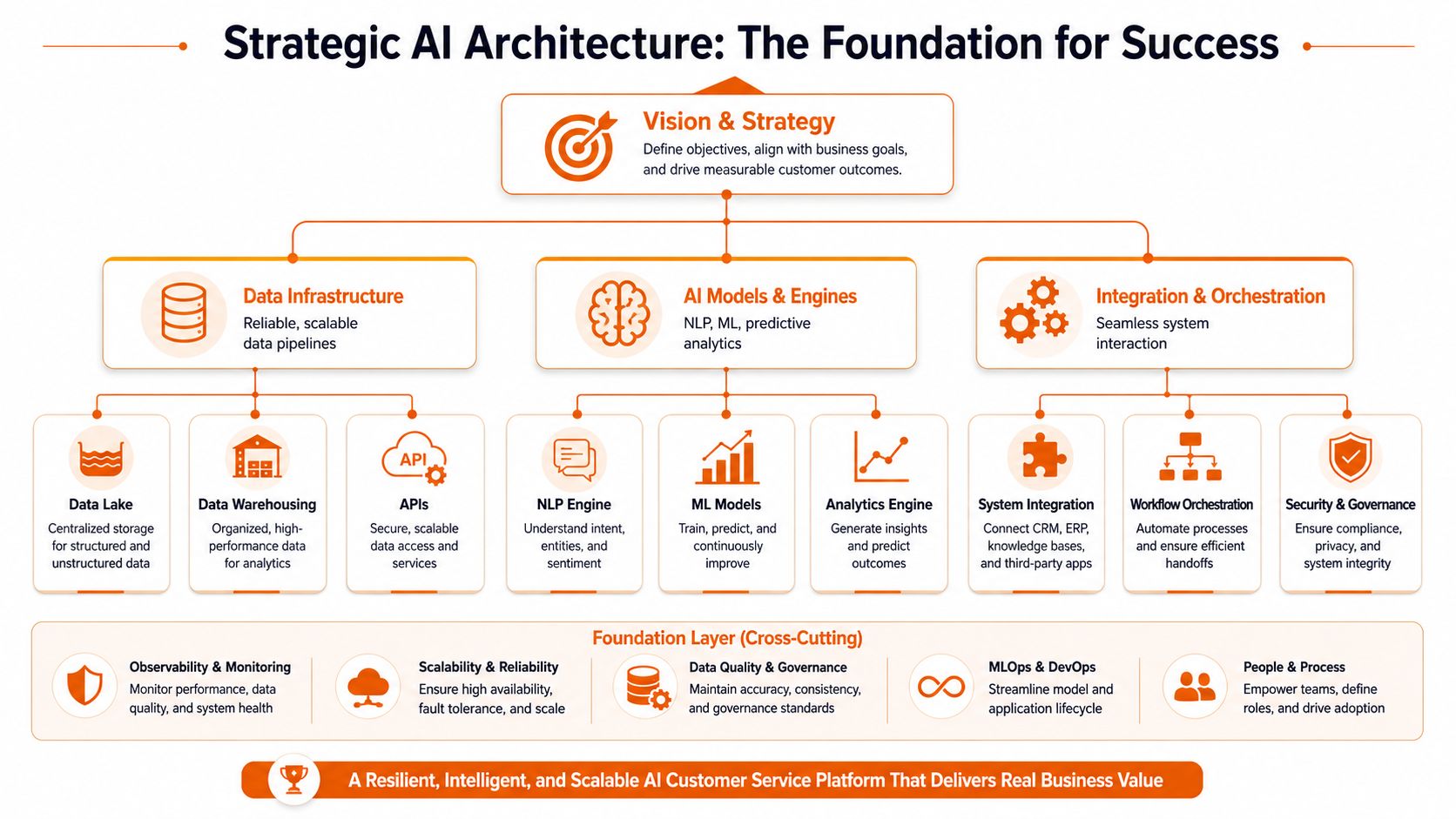
Microsoft notes that effective implementations combine NLP, machine learning, predictive analytics, sentiment analysis, and automated ticketing, and that performance depends on integration quality across CRM, ticketing, and knowledge systems through APIs, as outlined in Microsoft's AI customer service architecture guidance. That's the operating blueprint. Not model magic. Connected systems.
The minimum viable architecture
If I were advising a CTO on a first serious deployment, I'd insist on five layers:
- Channel intake: Live chat, email, forms, phone transcripts, and social messages.
- Decision layer: Intent detection, classification, routing logic, and response orchestration.
- Context layer: CRM records, subscription status, account metadata, previous conversations.
- Knowledge layer: Help centre content, internal runbooks, policies, and approved responses.
- Escalation layer: Human handoff with full conversation history and a clear reason code.
If one of those layers is weak, the whole system degrades.
Where most builds fail
The common failure mode isn't accuracy in a lab setting. It's operational disconnect.
A bot gives a plausible answer but can't verify account state. It routes a billing case correctly but drops the conversation history. It suggests a next action to an agent but ignores the latest product policy. Teams then blame the AI, when the underlying issue is bad orchestration.
This is why agentic design matters. The system has to do more than generate text. It has to take controlled action across tools and workflows. For engineering leaders exploring that approach, agentic engineering patterns are a useful lens because they force you to think in terms of action, state, and control.
Design principles worth enforcing
| Principle | Why it matters |
|---|---|
| Context before conversation | Good answers require account and case data |
| Rules before autonomy | Guardrails protect compliance and customer trust |
| Handoffs with memory | Agents must receive full history, not fragments |
| Observability from day one | You need to see routing failures, escalations, and knowledge gaps |
A smart-sounding bot with poor systems access is just a faster way to disappoint customers.
Architect for traceability, controlled action, and maintainability. If you do that, model upgrades become a bonus. If you don't, every improvement attempt turns into rework.
Implementation the Riteway Your Execution Playbook
Most AI customer service projects fail in delivery, not strategy. The team picks too many use cases, launches with weak governance, and celebrates activity instead of outcomes.
A better model is phased, disciplined, and owned end to end. That's the heart of the #riteway mindset. Extreme Ownership means one team takes responsibility for business impact, integration quality, governance, and adoption. No hand-waving. No blaming the platform. No hiding behind a pilot forever.
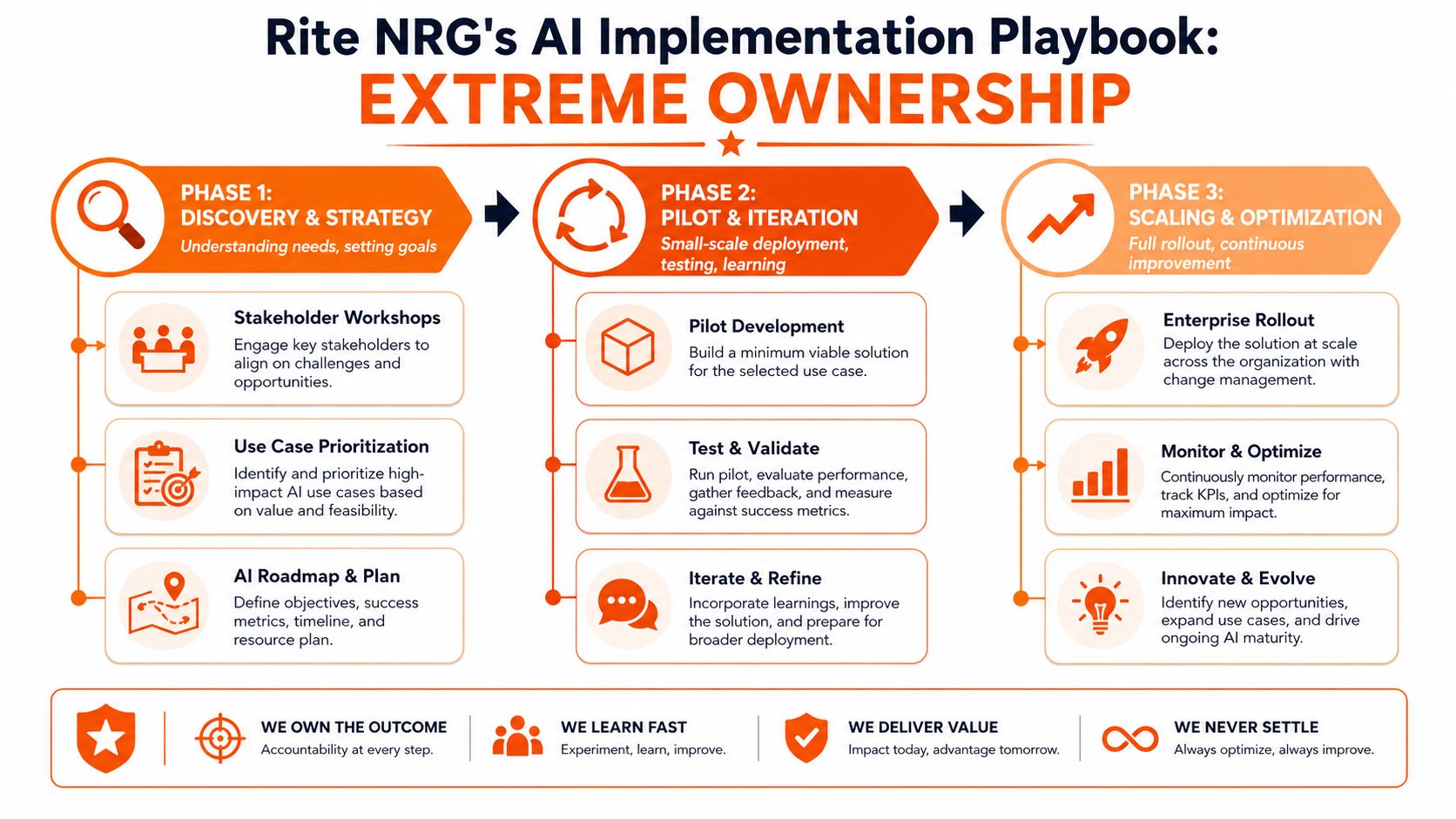
Phase one means narrowing the scope
Start with one workflow family, not a grand transformation programme.
Pick a use case with high volume, stable logic, clean source data, and obvious operational pain. Password resets, account updates, order status, and FAQ retrieval are strong candidates because they expose integration and workflow issues quickly.
Your delivery team should leave discovery with:
- A ranked use-case list: Based on volume, complexity, and business value
- A control model: Who owns prompts, knowledge, escalation policy, and compliance review
- A measurement plan: The operational metrics that prove value or expose failure
The implementation should also include governance from day one. NICE highlights an underserved issue that many teams ignore: UK customer-contact AI must still satisfy FCA expectations on fair treatment and effective complaint handling, which means control frameworks matter more than the chatbot itself, as noted in NICE's overview of AI powered customer service governance.
Phase two means learning in production
Don't wait for theoretical perfection. Launch the pilot with boundaries and inspect it hard.
Use the pilot to understand where intent classification fails, where knowledge is incomplete, where escalations need richer metadata, and where customers need a direct path to a person. This is operational learning, not model worship.
A useful walkthrough of phased AI delivery sits below.
Phase three means scaling what earned the right to scale
Only expand after the pilot proves three things:
- Customers can resolve real issues cleanly
- Agents trust the system enough to use it
- Governance holds under real-world variation
Delivery advice: Scale by repeating a proven pattern across adjacent workflows, not by rebuilding the platform for every new queue.
That's where high-energy execution matters. A good delivery partner doesn't wait for issues to surface in a status meeting. They spot weak knowledge articles, broken handoff logic, or policy drift early and fix them before they hit your metrics. That's what ownership looks like in practice.
Measuring What Matters KPIs for Real Impact
If your dashboard leads with bot sessions, conversation volume, or “AI interactions,” you're measuring theatre.
The only metrics worth caring about are the ones that tell you whether AI powered customer service is improving service economics and customer outcomes. Microsoft's implementation guidance points to the right benchmarks: the share of interactions resolved end to end without human intervention, alongside cost-per-chat, escalation rate, and first-contact resolution, all covered in the earlier Microsoft source.
The KPI stack that matters
Run your measurement model across four levels.
| KPI | What it tells you | Why leaders should care |
|---|---|---|
| Containment rate | How often AI resolves an issue without a person | Direct signal of automation value |
| First-contact resolution | Whether the issue was solved on the first attempt | Strong indicator of service quality |
| Escalation rate | How often AI hands off to human support | Shows where automation or knowledge is weak |
| Cost per interaction | What each support contact actually costs | Core measure of economic improvement |
Containment rate is the headline metric, but it's not enough on its own. A system can “contain” customers by blocking them from help. That's why containment must be read alongside first-contact resolution and escalation quality.
Add customer and agent signals
The second layer of the dashboard should answer two blunt questions. Are customers getting less effort, and are agents becoming more effective?
Use qualitative and operational signals together:
- CSAT trend: Did service quality hold or improve after automation landed?
- Customer effort: Are people solving issues with fewer steps and less repetition?
- Agent throughput: Are agents handling exceptions faster because summaries and routing are better?
- Reopen patterns: Are “resolved” cases remaining resolved?
If your AI reduces queue volume but increases confusion, you didn't improve support. You just moved the pain.
Build a weekly review rhythm
The right cadence is weekly operational review, not quarterly storytelling.
Review failed intents, knowledge misses, unnecessary escalations, and complaint-handling edge cases. Feed those findings into content updates, business rules, and integration fixes. AI customer service is never “implemented” in a one-and-done sense. It becomes a managed operational capability.
That's why the strongest teams treat metrics as control signals, not marketing assets.
Build Buy or Partner Making the Right Delivery Decision
It's 90 days after kickoff. The board wants proof of value, support leaders are fighting new failure modes, and your team is stuck between an expensive platform that can't handle edge cases and a custom build that keeps slipping. That outcome starts with a bad delivery choice.
Build, buy, or partner is not a procurement exercise. It is an operating model decision that sets your speed, control, cost base, and execution risk. As noted earlier, AI adoption is already forcing the issue. The key question is which route gets you into production fast without creating a support stack your team will regret owning.
When buying is the right move
Buy when your service model is mostly standard and your priority is time to value.
That means common channels, repeatable workflows, and a support operation that can adapt to platform constraints without damaging customer experience. If your goal is to deploy AI assistant capabilities quickly for high-volume service flows, a packaged product can get you live faster than a custom programme.
Be strict about fit. Review escalation logic, integration depth, reporting limits, and knowledge management before you sign. Buying works when the platform supports your process closely enough that configuration beats custom engineering.
When building makes sense
Build when customer service is part of your product advantage, compliance model, or revenue engine.
If your workflows span fragmented back-end systems, require custom orchestration, or depend on business logic a vendor cannot model cleanly, ownership matters. In that case, building gives you control over data flow, guardrails, observability, and the customer experience itself.
But building is a delivery commitment, not a feature decision.
You need engineering capacity, product ownership, AI evaluation discipline, and operational support after launch. Teams that underestimate that workload end up with a clever prototype and no dependable service capability.
Why partnering often wins
Partner when the outcome matters too much to learn through avoidable mistakes.
This route works best when you need fast execution, senior technical judgement, and a plan that protects the live operation while change is underway. A strong delivery partner closes the gap between strategy and production. They shape the architecture, sequence the rollout, manage risk, and keep the programme tied to business outcomes instead of demo theatre.
Use this option when internal teams are strong but stretched, or when the failure cost is high enough that speed alone is not the goal. You need speed with control.
Here's the practical decision view:
| Option | Best for | Main trade-off |
|---|---|---|
| Buy | Standard support needs | Less flexibility |
| Build | Unique workflows or defensible IP | More time and execution risk |
| Partner | Complex delivery with business-critical outcomes | Requires choosing the right operator |
If you're weighing these paths against your wider product and engineering roadmap, this guide to choosing an artificial intelligence software development company is useful because it focuses on delivery capability, technical depth, and execution fit.
Pick the route that gets you measurable value with controlled risk. Anything else is an expensive distraction.
If you're ready to implement AI powered customer service with a team that takes full ownership of delivery outcomes, Rite NRG is built for that job. They help SaaS and product-led companies design, integrate, and scale AI-enabled platforms with senior engineers, product-first thinking, and a delivery model focused on speed, control, and measurable business value.

