


Your phone goes off at 3 AM. Production is wobbling. Customers are refreshing dashboards. Slack is filling with guesses. One engineer starts digging in logs, another restarts a service, someone from leadership asks if this is reportable, and nobody is sure who owns the call.
That's how revenue leaks. Not from the incident alone, but from hesitation.
Organizations rarely fail because they lack talent. Instead, failure occurs because incident response procedures remain trapped in ignored documents rather than being integrated into daily operations. In the UK, only 55% of organisations have a fully documented incident response plan, and those without one face an average breach lifecycle of 258 days versus 189 days for prepared businesses, according to JumpCloud's incident response statistics summary. That gap is brutal for SaaS. It results in longer disruption, more difficult customer conversations, and more time with your roadmap hijacked by crisis work.
Beyond the Playbook The #riteway Incident Response Mindset
A static runbook won't save you when pressure hits. People will.
I've seen the difference first-hand. One team treats incidents like an awkward interruption. They improvise, argue over severity, and wait for a manager to bless every move. Another team treats incidents like a core business workflow. They know the chain of command, they know the customer impact threshold, and they start with containment instead of commentary.
That second team is operating with Extreme Ownership. That's the foundation of the #riteway mindset.
Ownership beats documentation alone
Most incident response procedures are too passive. They describe phases, define labels, and satisfy a compliance checkbox. Then they die in Confluence.
A working playbook does three things:
- Assigns decision rights clearly so nobody waits for vague approval.
- Connects technical action to business impact so engineers understand what revenue, trust, and contractual exposure are at stake.
- Turns response into muscle memory through repetition, not theory.
If your engineers don't know who declares a SEV1, who speaks to customers, or who signs off on recovery, your plan is decorative.
Practical rule: If your incident response plan can't be executed by a tired on-call team under pressure, it isn't a plan. It's documentation theatre.
What the #riteway mindset looks like in practice
Extreme Ownership during an incident means:
- The first responder owns clarity: confirm the signal, classify impact, escalate fast.
- The incident commander owns pace: keep decisions moving, kill side quests, protect the room from noise.
- The technical lead owns evidence: don't “fix” the issue so quickly that you erase the root cause.
- The comms owner owns trust: customers should hear facts, timing, and next steps. Not panic and not silence.
High-growth SaaS teams separate themselves through this approach. They don't ask, “Whose fault is this?” They ask, “What do customers need from us in the next 15 minutes?”
Your plan should be alive
Treat incident response procedures like product infrastructure. Version them. Review them after launches. Update them after architecture changes. Test them after team changes. If you run a distributed setup across London and Poland, the plan has to reflect real handoffs, real systems, and real accountability.
A good culture won't remove incidents. It will stop one bad hour becoming one bad quarter.
Assemble Your Response Unit Roles and Responsibilities
The fastest teams aren't larger. They're clearer.
When an incident kicks off, you need a response unit, not a crowd. Four roles cover most SaaS incidents well: Incident Commander, Communications Lead, Technical Lead or SME, and Scribe. You can pull in legal, data protection, support, or vendor contacts as needed, but these four create the operating spine.

The four roles that matter first
Incident Commander
This person runs the response. They don't chase logs or patch servers unless the team is tiny and there's no alternative. Their job is to set severity, assign actions, manage time, approve escalation, and keep everyone focused on customer impact.
Communications Lead
One owner for internal and external updates. That means leadership briefings, support guidance, customer status page wording, and coordination with legal or privacy stakeholders when needed. If this role is fuzzy, your engineers get dragged into writing updates instead of fixing the problem.
Technical Lead or SME
This person owns diagnosis and remediation. For a SaaS platform, that might be your backend lead, platform engineer, SRE, cloud specialist, or security engineer, depending on the incident. They coordinate the technical responders and protect the integrity of the investigation.
Scribe
Underused and massively important. The scribe records timeline, decisions, owners, evidence, and open questions. During the post-incident review, this person saves you from false memories and missing detail.
A chaotic response usually has enough talent. It's missing a single command structure.
A practical RACI you can start using
| Activity | Incident Commander | Comms Lead | Technical Lead/SME | Scribe |
|---|---|---|---|---|
| Declare incident severity | Accountable | Informed | Consulted | Responsible |
| Open incident channel and bridge | Accountable | Informed | Responsible | Responsible |
| Lead technical investigation | Informed | Informed | Accountable | Responsible |
| Approve customer update | Accountable | Responsible | Consulted | Informed |
| Coordinate executive updates | Accountable | Responsible | Informed | Informed |
| Decide containment action | Accountable | Informed | Responsible | Responsible |
| Record timeline and decisions | Informed | Informed | Informed | Accountable |
| Close incident and trigger review | Accountable | Informed | Consulted | Responsible |
How to integrate a nearshore team properly
Distributed teams fail during incidents for one simple reason. Local assumptions don't travel well.
If you have engineering in Poland and leadership or customer operations in London, define the handoff model before anything breaks. Don't leave it to goodwill.
Use these rules:
- Name the command language: all incident updates, severity labels, and timestamps should follow one format.
- Share one toolchain: one PagerDuty schedule, one Slack or Teams incident channel convention, one status page workflow, one source of truth for runbooks.
- Pin ownership by role, not geography: the best person for the incident should lead, regardless of office.
- Write escalation triggers explicitly: suspected data exposure, payment failure, authentication outage, and API degradation each need pre-agreed thresholds.
What Extreme Ownership looks like by role
- Incident Commander: makes the call when evidence is incomplete and documents why.
- Comms Lead: drafts an update before someone asks for one.
- Technical Lead: preserves evidence while fixing service.
- Scribe: captures decisions in real time so the team can learn, not guess, later.
That's how incident response procedures become executable instead of aspirational.
The Core Playbook From Detection to Full Recovery
Generic frameworks are fine for training decks. SaaS teams need something sharper. The six-phase UK NCSC-aligned flow works because it's simple, repeatable, and operational.
Organisations in the UK that follow the NCSC's 6-phase methodology and conduct regular training reduce MTTR by 62%, and top-quartile firms using SOAR automation achieve MTTD of under 30 minutes compared with the industry average of 4.2 hours, according to incident.io's guide to the incident response process. Those aren't abstract security wins. That's less downtime, fewer refunds, tighter executive comms, and a smaller blast radius.
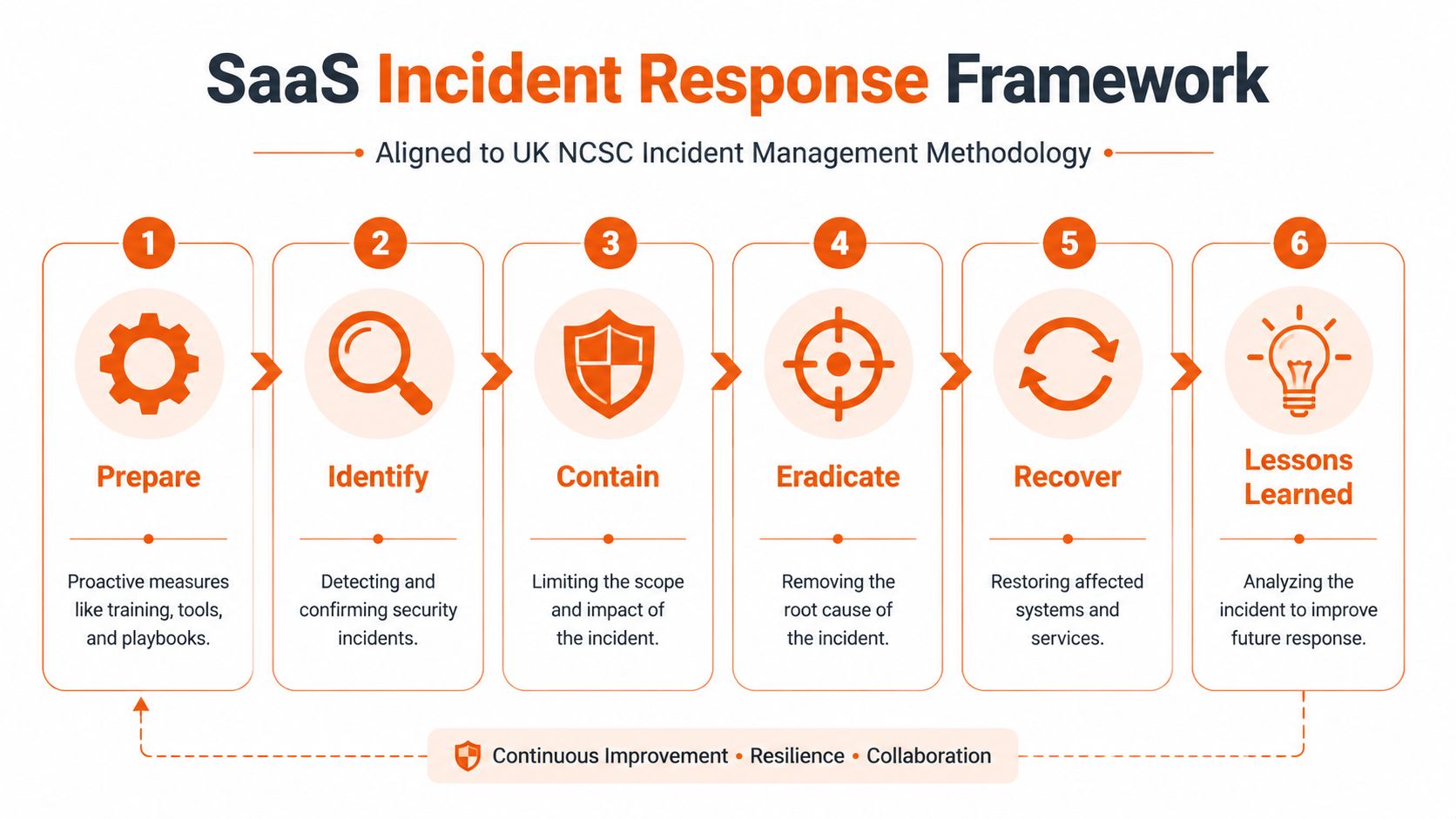
Prepare
Preparation starts long before the alert. Your monitoring, escalation paths, service ownership, and legal reporting routes must already exist.
For a SaaS product, preparation means:
- Map critical journeys: sign-in, billing, core API calls, data exports, admin actions.
- Define severity by business impact: a broken internal dashboard is not the same as customer auth failure.
- Pre-approve the operating room: who joins, who leads, which tools are used, and what gets recorded.
- Train on real scenarios: expired certificates, database lock contention, credential compromise, third-party outage, suspicious data access.
If you use tools like Datadog, Grafana, PagerDuty, Opsgenie, Jira, Sentry, or Cloudflare, wire them into one response flow. Alerts without workflow create noise.
Identify
This phase is about confirming that a signal is an incident, then classifying it fast.
In SaaS, identification usually starts with one of four patterns:
- Customer-facing symptom such as failed logins or API errors.
- System anomaly such as latency spikes, queue backups, or strange service restarts.
- Security signal such as impossible travel, privilege changes, or suspicious token activity.
- Third-party notification from a vendor, researcher, or partner.
Your team needs a short checklist:
- What's affected?
- Who's affected?
- Is this active or historical?
- What evidence do we have right now?
- Do we need to escalate for privacy, legal, or executive awareness?
Contain
Containment protects revenue first. That's the hard truth. You don't win points for elegant diagnosis while customers keep failing.
For a compromised microservice, containment may mean isolating that service behind feature flags, revoking risky credentials, disabling a dangerous integration, or throttling a damaged pathway while the wider platform stays live.
For account compromise, it may mean forcing session invalidation and raising authentication friction temporarily.
The right containment move isn't the one that looks cleanest on a diagram. It's the one that stops spread without causing a second outage.
This is also the phase where broader reputation issues can emerge. If the incident spills into public accusations, coordinated misinformation, or reputational attacks against leadership, teams should treat communications as part of containment. A useful executive resource on that front is managing targeted smear campaigns, especially when a cyber event starts dragging brand trust into the crisis.
Eradicate
Now remove the cause, not just the symptom.
Examples in SaaS environments include rotating compromised secrets, removing malicious persistence, patching a vulnerable dependency, killing unauthorised integrations, rebuilding tainted workloads, and validating that stale sessions or tokens can't still reach production.
Technical discipline matters here:
- Preserve forensic value before wiping evidence.
- Check adjacent systems that share access paths.
- Validate IaC and CI/CD pipelines if the incident touched build or deployment tooling.
Recover
Recovery is controlled re-entry, not a heroic “all clear”.
For a phased API rollback, restore the minimal healthy path first. Bring back critical endpoints, validate error rates, confirm data integrity, and only then reopen secondary functions. Don't return every workload at once just because the queue looks calmer.
A good recovery checklist includes:
| Recovery checkpoint | What to verify |
|---|---|
| Core service health | Auth, API responsiveness, background jobs |
| Data integrity | No corruption, duplication, or failed writes |
| Access integrity | Revoked credentials stay revoked |
| Customer comms | Status page and support guidance are current |
| Monitoring | Alert thresholds match the temporary state |
Lessons learned
This phase is where mature teams get paid back.
Run a blameless review quickly while memory is fresh. Focus on timeline, decision quality, system weakness, detection gaps, and communication bottlenecks. Then update the playbook, not just the slide deck.
If the same class of incident can happen again next week, you didn't finish the work.
Crafting Your Essential Incident Response Assets
A response framework is useless without assets your team can grab under pressure.
When systems are failing, nobody wants a philosophical policy. They need a runbook, a stakeholder list, a customer update template, and a severity matrix that doesn't require debate. Good incident response procedures are built from these working assets.
The minimum asset library
At a minimum, keep these documents current and easy to access:
- Severity matrix: define SEV levels by customer impact, security implications, and operational risk.
- Runbooks for common failure modes: payment issues, database degradation, authentication failure, cloud misconfiguration, suspicious access event.
- Communication templates: internal alert, executive summary, customer status update, regulator-ready draft.
- Contact map: owners for engineering, support, legal, privacy, infrastructure, and critical vendors.
- Evidence checklist: what logs, screenshots, event history, tickets, and approvals must be preserved.
Put these in one place. If people have to hunt across five tools, they'll default to memory.
What a useful runbook actually looks like
A runbook should be short enough to use and specific enough to guide action. Here's a practical structure for a database outage runbook:
Trigger conditions
Define the symptoms that activate the runbook. Increased database errors, write failures, timeout spikes, or customer-facing transaction failures.Immediate stabilisation steps
Pause risky deploys. Declare incident severity. Route traffic if safe. Protect recent backups and audit logs.Diagnostic checks
Review replication state, connection pool pressure, recent schema changes, failed jobs, and infrastructure events.Containment options
Shift read-heavy traffic, disable non-critical write paths, or place selected features into maintenance mode.Recovery sequence
Restore service in stages. Validate customer-critical workflows before reopening background or reporting features.Exit criteria
Error rates stable, integrity checks passed, monitoring normalised, customer message updated.
Keep customer communication pre-written
Many organizations underinvest in this area. Consequently, the initial public update sounds like legal hedging combined with engineering jargon.
Write templates in advance. Keep them calm and direct.
We're investigating an issue affecting customer logins. We've identified the affected service and are working on containment. We'll share another update at [time] or sooner if we confirm broader impact.
That's better than silence, and far better than improvised speculation.
Build documents for use, not audits
Use plain language. Add owners. Add timestamps. Add links to dashboards and tickets. Strip out policy waffle.
A strong asset library has three traits:
- Fast to scan
- Easy to update
- Written for tired humans
That's the standard. If a document can't help during a rough on-call shift, it doesn't belong in your incident response procedures.
Supercharge Response with AI and Nearshore Integration
AI in incident response is no longer optional for scale-ups that care about speed. It's now a practical operating advantage.
A 2025 PwC UK study cited in SentinelOne's SANS incident response overview found that only 22% of scale-ups use AI in their IRPs, yet those who do reduce containment times from 72 hours to 28 hours. The same source notes that UK SaaS incidents rose 32% in 2025, driven by AI-powered supply chain attacks. If your procedures assume humans will manually triage everything at growth-stage volume, you're already behind.

Where AI actually helps
Skip the hype. Use AI where it removes drag.
The best uses inside incident response procedures are:
- Alert triage: rank incoming alerts by business context so the team sees probable incidents first.
- Pattern correlation: connect logs, endpoint signals, cloud events, and deploy history faster than a human can.
- Drafting support: generate first-pass summaries for incident channels, executive updates, and postmortems.
- Knowledge retrieval: surface the right runbook, prior incident, or owner based on the current symptom set.
Tools vary, but the principle is the same. Let automation handle repetition. Keep human judgement for impact, risk, and final decisions.
Don't bolt AI on. Design for it.
Many organizations make the same mistake. They add an AI feature to a security tool and call the job done.
That's lazy architecture. AI has to be embedded in the procedure itself.
For example:
| Procedure point | Manual-only response | AI-assisted response |
|---|---|---|
| Initial triage | Analyst reviews alert queue | AI groups related alerts and flags likely incident |
| Root cause search | Engineer checks services one by one | AI summarises correlated anomalies across systems |
| Stakeholder update | Manager writes from scratch | AI drafts status update for review |
| Post-incident review | Team reconstructs timeline manually | AI compiles event chronology from logs and chat history |
If you operate across legal and regulatory boundaries, pair this with strong review controls. Teams working with reporting obligations often borrow ideas from adjacent domains where AI helps accelerate document-heavy analysis. A useful example is how firms apply AI tools for legal research to reduce search time while keeping human oversight on final interpretation.
Nearshore integration is an incident response multiplier
A nearshore team isn't just a delivery model. Done properly, it becomes a response engine.
For SaaS teams split across the UK and Poland, the gains come from continuity, not cost. You can extend operational coverage, speed up investigation, and maintain delivery momentum while the incident squad handles the live issue. That only works if the nearshore team is fully integrated into your incident response procedures.
Use one set of rules across both locations:
- Shared monitoring and paging
- Shared runbooks
- Shared severity language
- Shared access model
- Shared post-incident review process
If you want a practical operating model for that setup, this guide to nearshore service delivery is a good reference point for structuring collaboration without messy handoffs.
Here's the critical bit. Your Poland team shouldn't be “extra hands” during an incident. They should hold named responsibilities, own systems, and participate in tabletop drills exactly like the London side.
A distributed team responds well only when it trains as one team before the incident, not during it.
A short explainer helps when you're socialising this model internally:
One practical stack for modern SaaS teams
A strong setup often includes SIEM, SOAR, cloud logging, endpoint telemetry, ticketing, paging, and status communications tied together. Tools like Datadog, Sentry, PagerDuty, Jira, Slack, and cloud-native audit logs can do the heavy lifting if your process is disciplined.
One delivery option some teams use is Rite NRG, which supports automated incident management workflows through tools such as PagerDuty or Opsgenie and provides corrective maintenance for critical incidents. That matters if you need your engineering partner to participate in response, not just feature delivery.
AI plus a properly integrated nearshore team gives you something most SaaS businesses lack. Response capacity without operational chaos.
Battle-Test Your Plan with KPIs and Tabletop Exercises
An untested plan is fiction.
The most efficient method for exposing weak incident response procedures involves putting people through a realistic scenario and observing where they hesitate. Most hesitation stems from unclear authority, missing assets, or compliance confusion. These issues are fixable, but only if you surface them before a true incident occurs.
For UK SaaS firms, the compliance angle is getting sharper. 68% of UK SaaS firms lack IRPs customized for NIS2 compliance, which mandates reporting within 24 hours and carries potential fines of £17.5 million. The same source notes that over-reliance on generic US frameworks can delay recovery by 40% in UK-specific cases, according to Exabeam's discussion of SANS-based incident response practice. If your tabletop never includes reporting pressure, cross-border data questions, or executive sign-off timing, your exercise is too soft.

Run tabletop exercises that feel real
Don't run a vague “cyber breach” workshop. Run scenarios your architecture and customer base make plausible.
Good scenarios for SaaS teams include:
- Customer authentication outage: login failures after a deployment.
- Suspicious data access event: unusual admin activity across tenant data.
- Third-party compromise: billing, identity, or analytics vendor exposure.
- Ransomware-style lateral threat: developer tooling or CI/CD pipeline concern.
- Public pressure incident: outage mixed with social media escalation and enterprise customer demands.
Make the room work. Interrupt them. Add new facts midway. Force trade-offs.
Score the exercise properly
You don't need a giant maturity model. Track a small set of KPIs that reveal whether the team can execute.
Use measures such as:
| KPI | What it tells you |
|---|---|
| MTTD | How fast the team recognises a real incident |
| MTTR | How fast the team stabilises and resolves |
| Containment time | How long exposure remains active |
| Escalation accuracy | Whether the right people were involved at the right moment |
| Communication latency | How long customers or executives wait for a clear update |
| Action closure rate | Whether review actions actually get completed |
The point of KPIs is improvement, not punishment. If people think metrics are a blame tool, they'll hide mistakes and your incident response procedures will rot.
Make postmortems blameless and specific
Every exercise and every real incident should end with a review that answers three questions:
- What slowed us down?
- What confused ownership?
- What needs to change in tooling, training, or architecture?
Then assign owners and deadlines. If you want a broader framework for handling these delivery threats beyond security incidents, this article on software project risk management is worth sharing with engineering leadership.
The point of a tabletop isn't to prove the plan works. It's to find the exact place where it breaks.
That's how strong teams improve. Not with heroic memory. With evidence, repetition, and updates.
From Firefighting to Proactive Business Resilience
The essential outcome of strong incident response procedures isn't a prettier security posture. It's predictable SaaS delivery under pressure.
When you combine Extreme Ownership, a role-based command model, a SaaS-native six-phase workflow, practical response assets, AI-assisted triage, and a fully integrated nearshore team, incidents stop derailing the company. They still hurt. But they don't own the quarter.
That's the shift the #riteway approach is built for. High energy. Clear ownership. No waiting around for someone else to solve the problem. Your team moves, communicates, documents, and learns. Customers see control instead of confusion. Leadership gets facts instead of noise. Product delivery recovers faster because the response isn't consuming every engineer for weeks.
There's also a bigger leadership point here. Incident response isn't just a security function. It's an operating capability that protects revenue, contracts, investor confidence, and customer trust. The companies that treat it seriously don't just recover better. They sell better, renew better, and scale with fewer ugly surprises.
If you want your response capability to support a wider resilience model, not sit in a silo, align it with broader business continuity strategies. That's where incident response becomes a board-level asset instead of a technical afterthought.
Build the procedures. Name the roles. Train the team. Test the system. Tighten the handoffs. Automate the boring parts. Review every incident without ego.
That's how you move from firefighting to resilience customers can feel.
If you need a strategic partner to tighten your incident response procedures while also improving delivery predictability, Rite NRG can help you design the operating model, integrate nearshore teams into real ownership structures, and build SaaS delivery processes that hold up under pressure.

