


Your SaaS business probably looks resilient from the outside. The app is live. Alerts are configured. Backups exist somewhere. Your team ships often, your roadmap is aggressive, and investors expect momentum.
Then a real disruption hits and the illusion disappears. Continuity isn’t tested when everything is green. It’s tested when your deployment pipeline stalls, a critical integration fails, and the people who know how to recover it aren’t available at the same time.
Your Wake-Up Call Is Coming
At some point, your wake-up call will arrive at the worst possible hour. A production issue blocks releases. A customer-facing service degrades. Your nearshore team is unreachable for reasons nobody planned for. The issue stops being technical within minutes. It becomes commercial.
A delayed release can push back a client launch. A missed SLA can trigger escalations. A messy incident can damage confidence with the board faster than any post-mortem can repair it. Founders often treat continuity as a compliance task because they haven’t yet paid the full price of operational fragility.
Confidence and preparation are not the same thing. While 94% of businesses believe they would recover from a disaster, 74% have no documented disaster recovery plan, and 34% of organisations that face disruption without a plan take six months or more to recover according to business continuity statistics compiled by Invenio IT. For a SaaS company, that kind of recovery timeline doesn’t just hurt. It threatens renewals, roadmap credibility, and the next funding conversation.
Business continuity strategies should protect revenue, delivery momentum, and trust. If they only protect infrastructure on paper, they’re incomplete.
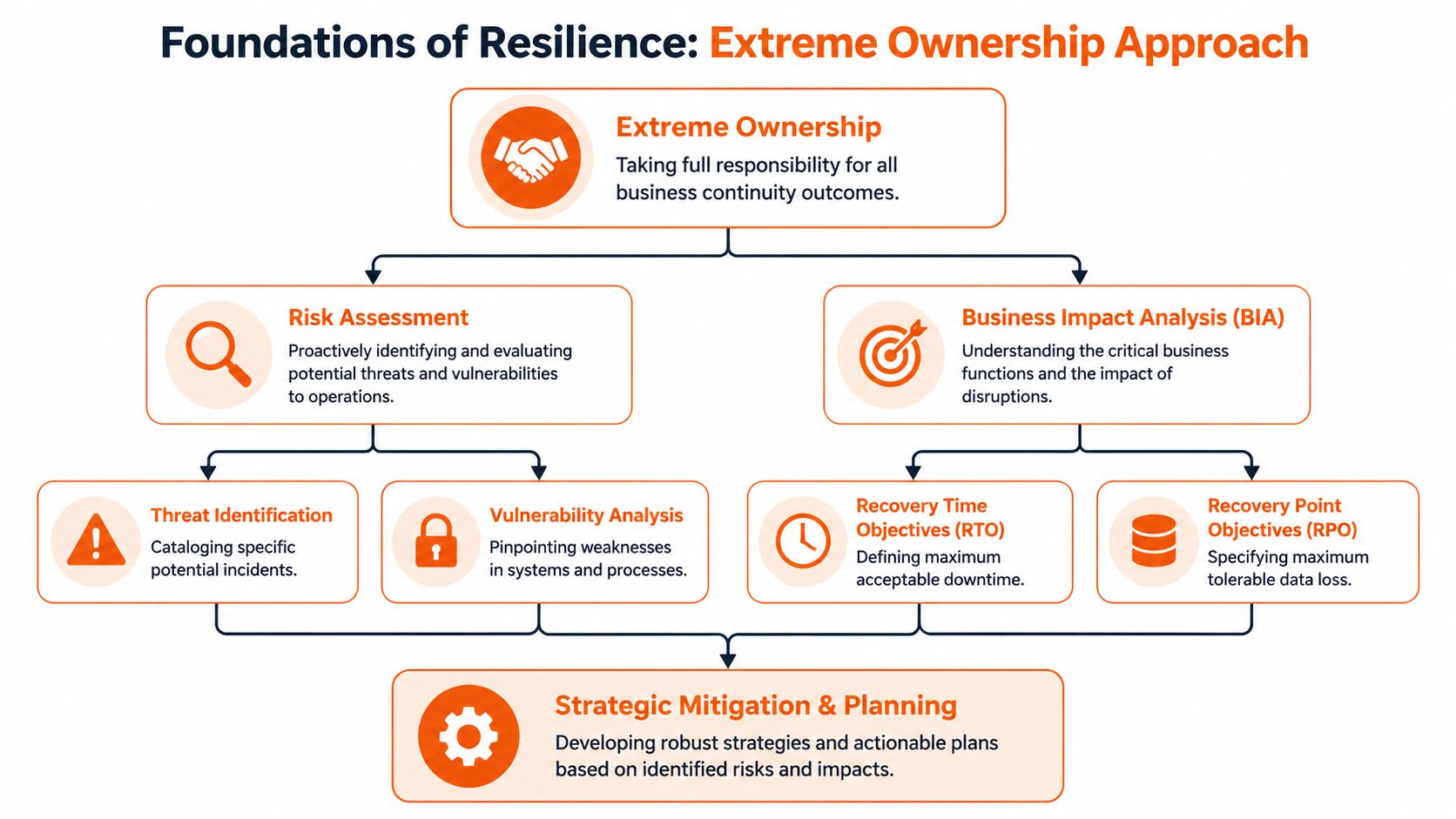
I’m opinionated on this point. A once-a-year document review is not a continuity strategy. It’s theatre. Real resilience comes from Extreme Ownership. Someone owns the outcome, the dependencies, the testing cadence, the handovers, and the weak spots nobody wants to admit exist.
That’s the #riteway mindset. Treat continuity as part of delivery, not as a side file owned by operations alone. If your product depends on engineers, cloud services, vendor access, release processes, and customer communications, your continuity model has to sit inside those same workflows. Done properly, continuity stops being a cost centre and starts acting like a delivery multiplier.
Foundations of Resilience Your Risk and Impact Analysis
Many organizations begin with a spreadsheet of risks. That approach is too shallow. You need a map that demonstrates how disruption impacts the business, rather than just the technology stack.
A proper impact analysis starts with one hard question. What must keep working to protect revenue, customer trust, and delivery confidence? If you can’t answer that clearly, your continuity work will drift into generic controls that look sensible and fail under pressure.
Start with business consequences
Founders and CTOs should list critical outcomes before listing threats. Focus on things such as subscription billing, production availability, release capability, customer support continuity, and access to the product data your team needs to operate. Then identify what each outcome depends on.
Those dependencies usually include more than infrastructure:
- People dependencies: key engineers, platform owners, team leads, DevOps specialists
- Process dependencies: deployment approvals, incident escalation, on-call handovers
- External dependencies: cloud providers, authentication platforms, payment gateways, analytics tools
- Delivery dependencies: sprint planning continuity, QA availability, CI/CD access, release management
A lot of leadership teams underestimate one category in particular. Most BCPs treat offshore vendors as simple third-party dependencies, but for SaaS companies using integrated nearshore partners, a regional disruption can halt product delivery entirely. A key gap in planning is failing to design for redundancy across distributed delivery models and cross-geography knowledge transfer, as noted in this small business continuity planning guidance from the US Chamber.
That’s the hidden dependency risk. If your nearshore team is your delivery engine, they are not just a vendor. They are part of your operating core.
Build a dependency map you can act on
Don’t stop at naming risks. Score them by business effect. A failed feature release is inconvenient. A blocked production fix during a major customer launch is existential.
I recommend three practical layers:
Critical now
Anything that stops customer access, cash collection, security response, or production change control.Critical soon
Anything that won’t hurt in the first hour but will hurt within days, such as roadmap slippage, reporting gaps, or delayed integrations.Tolerable temporarily
Internal functions you can run through workarounds for a limited period.
Practical rule: If a dependency affects customer trust or release capability, put an owner against it. Shared concern without named ownership is where continuity plans die.
If you need a sharper framework for assessing operational impact, this guide for security leaders is useful because it keeps the analysis tied to decision-making instead of paperwork. I’d also pair that with a serious look at software project risk management so your delivery risks and continuity risks don’t live in separate universes.
What good looks like
A strong analysis produces decisions, not documents. By the end of it, you should know:
- Which services must recover first
- Which roles create single points of failure
- Which vendors require backup arrangements
- Which workflows need manual alternatives
- Which client commitments are impossible to meet with the current setup
That list becomes the foundation for every technical, staffing, and contractual decision that follows.
Designing Your Technical Defence System
Once your priorities are clear, build for failure instead of hoping to avoid it. Good business continuity strategies assume components will break and make recovery routine.
The architecture decision that matters most is not “what’s modern?” It’s “what recovery speed does the business need, and what’s the cheapest design that can deliver it consistently?”

Choose failover patterns by business impact
Some teams overbuild. Others underinvest and discover too late that “we can restore from backup” is not the same as “we can keep the business moving”.
Use a simple lens:
- Active-active suits workloads where interruption immediately affects customer operations or revenue. It costs more and demands stronger operational discipline.
- Active-passive works when brief service degradation is tolerable and cost control matters more than instantaneous failover.
- Cold recovery is acceptable for non-critical internal systems that don’t need immediate restoration.
Your production stack isn’t the only thing that needs resilience. Protect the systems that let you ship, support, and secure the product. That means source control, build runners, secrets management, observability, incident tooling, and internal documentation. If the app survives but your team can’t deploy or diagnose, you still have a continuity problem.
Backups are a financial decision, not just a technical one
A lot of backup conversations stay trapped inside engineering. They shouldn’t. Backup design is a board-level resilience decision because it changes the cost of failure.
As of 2026, 84% of businesses store their data and backups in the cloud, according to these cloud and continuity statistics. The same source states that for companies recovering from ransomware attacks, using backups costs a median of $750,000 compared to the average ransom demand of $3 million. That gap is the clearest business case you’ll ever get for disciplined backup strategy.
Here’s the practical standard I push clients towards:
- Separate backup domains: don’t let the same failure path affect production and recovery assets
- Restore testing: a backup that hasn’t been restored is a theory
- Priority-based recovery order: restore what protects customer service and revenue first
- Documented ownership: one named person owns the backup policy, another validates recoverability
Security validation matters here as well. If you’re exposing customer-facing systems to the internet, regular web application pentesting helps identify the weaknesses that can turn an incident into a continuity event.
Harden the delivery pipeline
Many continuity plans obsess over production and ignore the route to production. That’s a mistake. If your CI/CD pipeline, package registry, or deployment permissions fail, your delivery machine stalls.
Treat your engineering workflow like a critical service:
| Delivery component | What to protect | Practical safeguard |
|---|---|---|
| Source control | Code access and branch history | Mirrored repos, strict access hygiene |
| CI runners | Build and test execution | Secondary runners and fallback workflows |
| Artifact storage | Deployable packages | Replication and retention rules |
| Secrets management | Runtime credentials | Recovery procedures and access separation |
| Observability | Diagnosis and validation | Redundant logging and alert access |
If you want a broader operational view of gaps around controls, process resilience, and exposure, run an information technology security audit before a real incident forces the issue.
A practical explainer on recovery thinking is worth watching here:
Build continuity into delivery partners too
Vendor strategy transitions into operational strategy. If you work with a nearshore partner, test whether they can maintain delivery under disruption. Ask how they handle team substitution, handovers, knowledge capture, and environment continuity. One option in the market is Rite NRG, which provides nearshore software delivery teams and consulting around delivery continuity, team integration, and operational handovers.
The point isn’t who you pick. The point is that your technical defence system must include the people and processes that keep releases moving.
Ensuring Your Team Is Your Strongest Link
Technology breaks in predictable ways. Teams break in subtle ways. That’s why the people side of business continuity strategies deserves the same rigour as architecture.
A resilient SaaS team doesn’t rely on heroic individuals. It relies on shared context, repeatable handovers, and calm execution across locations. If one engineer, one lead, or one timezone holds too much knowledge, your delivery model is fragile no matter how strong your cloud setup looks.
Remove knowledge bottlenecks
The first thing I look for is concentration risk. Who knows the deployment process? Who understands the billing edge cases? Who can restore the staging environment? Who can explain the hidden dependencies in the release train?
If the answer to any of those is one person, you have a continuity failure already in place.

Build redundancy through habits, not slogans:
- Operational runbooks: keep them short, current, and written for stressed humans
- Recorded walkthroughs: capture recovery tasks, release flows, and environment quirks
- Shared ownership rotations: rotate incident, deployment, and support responsibilities
- Architecture reviews with mixed attendance: don’t let critical decisions live in small circles
The strongest continuity control in a software team is not a document. It’s a second person who can execute the task cleanly without escalation.
Integrate nearshore teams into the core
A nearshore team should never sit on the edge of your operating model. If they only build tickets and don’t own outcomes, they can’t support continuity when pressure hits. Integrated teams recover faster because they already understand the context, constraints, and communication rhythm of the product organisation.
That means your nearshore engineers should join the same ceremonies, use the same tools, and have access to the same operational knowledge as your in-house team. Keep escalation paths unified. Keep decision-making visible. Keep documentation shared.
A lot of companies say they want resilience while maintaining a hidden class system between “core” and “external” teams. That doesn’t work. In a disruption, separation becomes delay.
If you’re trying to create that kind of operating model, this piece on building high-performing teams is a useful starting point because it focuses on integration and accountability rather than job titles.
Train for continuity under pressure
Training shouldn’t feel like compliance theatre. It should feel like operational rehearsal.
I’d structure team continuity around three layers:
Role backup
Every critical responsibility needs a clear secondary owner.Scenario drills
Rehearse realistic disruptions, including unavailable people, not just unavailable systems.Communication discipline
Decide in advance who updates customers, who briefs leadership, and who runs internal coordination.
Leadership test: If your team lost a key engineer for two weeks tomorrow, would work slow down gracefully or stop abruptly?
If the answer is “stop abruptly”, don’t buy more tools first. Fix ownership, cross-training, and team design.
From Plan to Action Your Incident Response Framework
Continuity plans fail in the same moment incident response gets messy. People don’t need a long document when systems are down. They need a playbook that tells them what happens next.
Start with a believable scenario. A release introduces a defect. Rollback fails because the pipeline is unstable. Customer support starts logging complaints. Your infrastructure team sees secondary issues in a dependent service. Leadership wants updates every few minutes. Sales wants to know what to tell a strategic client.
That’s where weak plans collapse. Nobody knows who is leading, who is communicating, or when continuity mode officially starts.
Build playbooks for decisions, not for theatre
A good playbook fits on a few pages. It includes triggers, decision rights, workarounds, communication paths, and recovery steps. It doesn’t try to predict every variation. It gives the team enough structure to act quickly.
Your core incident playbooks should cover:
- Service outage: who declares the incident, who owns recovery, what customer message goes out first
- Security event: who isolates systems, who coordinates legal and customer updates, how release activity changes
- Cloud or vendor outage: what internal fallback exists, what work pauses, what can continue manually
- Team continuity event: who reassigns responsibilities, how handover happens, what roadmap commitments get reset
Define roles before emotions take over
I like a simple incident structure because people remember it under stress:
| Role | Responsibility |
|---|---|
| Incident lead | Owns decisions and cadence |
| Technical lead | Directs diagnosis and restoration |
| Communications lead | Handles internal and external updates |
| Business owner | Prioritises trade-offs based on client and revenue impact |
That structure matters more than fancy tooling. If four people think they are in charge, nobody is.
For practical ideas on how mature teams resolve incidents faster, it’s worth studying how procedures, escalation paths, and communication templates reduce wasted motion during active disruption.
Rehearse the hard conversations
The toughest part of incident response is rarely the technical fix. It’s the judgement call. Do you pause releases for all customers or just one segment? Do you invoke a backup vendor process? Do you tell a major client now or wait for cleaner facts?
Those calls become easier when the language is prepared in advance.
Use pre-drafted communications for:
- Customers: what happened, what they should expect next, when the next update lands
- Internal teams: what changed operationally, what work pauses, what needs immediate attention
- Executives and investors: commercial impact, mitigation path, next decision point
Calm communication is a continuity control. Teams that communicate late create operational drag for everyone else.
Run exercises that include your delivery partner and any critical vendor involved in support, hosting, or release management. If handover is part of your resilience strategy, practise it. Don’t leave it as a contractual fantasy.
Proving and Improving Your Continuity Strategy
A release goes out on Thursday. By Friday, a dependency change has broken a recovery script, your nearshore team is offline for a local holiday, and the person who knows the failover sequence is in transit with no signal. If your continuity strategy is only reviewed once a year, you do not have a strategy. You have paperwork.
SaaS delivery changes too fast for static continuity plans. Product releases, vendor updates, team rotations, AI-assisted workflows, and cross-border handoffs all change your recovery posture. Treat continuity as part of delivery management. Track it, test it, and improve it with the same discipline you apply to deployment performance and service quality.
Measure what recovery looks like
Start with metrics that reflect execution under pressure.
| KPI | Description | Practical target |
|---|---|---|
| Recovery Time Achievement Rate | Percentage of recovery events or exercises that meet the agreed recovery time objective | Track trend by service and keep the rate high enough to support your customer commitments, using target ranges informed by Bryghtpath’s business continuity strategy guidance |
| Recovery Time Objective | Maximum acceptable downtime for a critical function | Set by service tier, revenue impact, and contractual exposure |
| Recovery Point Objective | Maximum tolerable data loss window | Set by data type, client expectation, and operational risk |
| Cross-training coverage | Number of people who can run recovery for each critical function | Ensure every critical function can be recovered without relying on one person or one location |
These metrics force honest conversations. If your SLA promises near-continuous service but your recovery design depends on a single engineer, a manual handoff, or a vendor ticket queue, your operating model is out of line with your commercial promise.
Use recognised standards to tighten the model. The NIST Cybersecurity Framework 2.0 is useful for governance and recovery maturity. ISO 22301 is the benchmark for building and maintaining a business continuity management system. For cloud resilience patterns, the AWS Well-Architected Framework reliability pillar gives practical design guidance that maps well to modern SaaS estates.
Replace calendar-based testing with delivery-based validation
Annual testing creates false confidence. Your systems and teams will not wait for the next exercise window.
Tie continuity validation to change. New architecture, new supplier, new AI tool in the delivery chain, new support coverage model, new nearshore pod structure. Each of those changes can weaken recovery without anyone noticing.
Set a review cadence that matches how SaaS teams work:
- Quarterly continuity reviews: confirm owners, dependencies, recovery paths, and third-party assumptions
- Post-incident updates: update runbooks and decision paths while the lessons are fresh
- Change-triggered validation: test continuity controls whenever architecture, staffing, vendors, or release processes change
- Cross-border handoff checks: validate that recovery can continue across time zones, language boundaries, and country-specific leave calendars
Any plan that survives several delivery changes without revision is probably wrong.
Use AI to find weak signals earlier
Modern continuity practice should not rely on scheduled workshops alone. Your delivery data already shows where resilience is thinning out.
Use AI-assisted analysis to detect concentration risk in key people, repeated build or deployment failures, fragile service dependencies, inconsistent runbook usage, and support patterns that point to an emerging incident class. That matters even more for nearshore models, where continuity depends on clean handoffs, shared context, and clear ownership across distributed teams.
The goal is simple. Find the weakness before the outage exposes it.
That is the difference between a legacy continuity plan and a modern one. Legacy continuity sits in a folder and comes out during an audit. Modern continuity sits inside engineering, service operations, and delivery governance. It gets better every quarter because the team uses it.
If you want a continuity model that protects releases, client trust, and growth momentum, talk to Rite NRG. We work with SaaS teams on delivery resilience, nearshore operating models, and continuity practices that sit inside the way products are built and shipped.

